







"""不含模型参数的自定义层""" #如何定义一个不含模型的自定义层: #下面的CenteredLayer类通过继承Module类自定义了一个将输入减掉均值后输出的层,并将层的计算定义在了forward函数里。 #这个层里不含模型参数
import torch
from torch import nn
class CenteredLayer(nn.Module):
def __init__(self,**kwargs):
super(CenteredLayer,self).__init__(**kwargs)
def forward(self,x):
return x-x.mean()
#实例化这个层,
layer=CenteredLayer()
print(layer(torch.tensor([1,2,3,4,5],dtype=torch.float)))
#构建更复杂的模型
net=nn.Sequential(nn.Linear(8,128),CenteredLayer())
#下面打印自定义层各个输出的均值,因为均值是浮点数,所以它的值是一个很接近0的数
y=net(torch.rand(4,8))
print(y.mean().item())输出:
"""含模型参数的自定义层""" #parameter类其实是Tensor的子类,如果⼀个 Tensor 是 Parameter ,那么它会⾃动被添加到模型的参数列表⾥。 #所以在自定义含模型参数的层时,我们应该将参数定义成parammter,除了直接定义成 Parameter 类外,还可以使⽤ ParameterList 和 ParameterDict 分别定义参数的列表和字典
class MyDense(nn.Module):
def __init__(self):
super(MyDense, self).__init__()
self.params=nn.ParameterList([nn.Parameter(torch.randn(4,4)) for i in range(3)])
#ParameterList 接收⼀个 Parameter 实例的列表作为输⼊然后得到⼀个参数列表,使⽤的时候可以⽤索引来访问某个参数,另外也可以使⽤ append 和 extend 在列表后⾯新增参数
self.params.append(nn.Parameter(torch.randn(4,1)))
def forward(self,x):
for i in range(len(self.params)):
x=torch.mm(x,self.params[i])
return x
net=MyDense()
print(net)
#⽽ ParameterDict 接收⼀个 Parmeter 实例的字典作为输⼊然后得到⼀个参数字典,然后可以按照字典的规则使⽤了
class MyDictDense(nn.Module):
def __init__(self):
super(MyDictDense, self).__init__()
self.params=nn.ParameterDict({
'linear1':nn.Parameter(torch.randn(4,4)),
'linear2':nn.Parameter(torch.randn(4,1))
})
#update() 新增参数
self.params.update({'linear3':nn.Parameter(torch.randn(4,2))})#新增
def forward(self,x,choice='linear1'):
return torch.mm(x,self.params[choice])
net=MyDictDense()
print(net)
#根据传入的键值来进行不同的前向传播
x = torch.ones(1, 4)
print(net(x, 'linear1'))
print(net(x, 'linear2'))
print(net(x, 'linear3'))
#也可以使用自定义层构造模型。
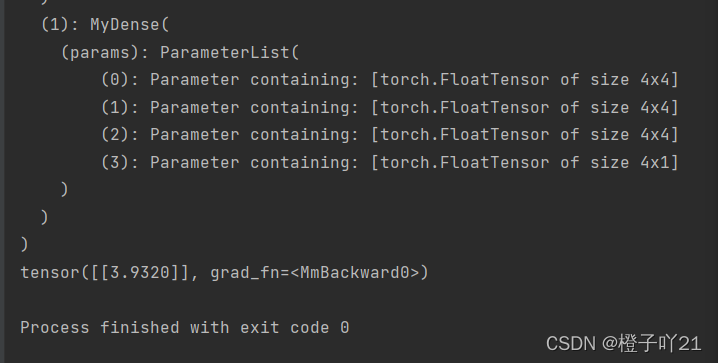
net=nn.Sequential(
MyDictDense(),
MyDense(),
)
print(net)
print(net(x))输出: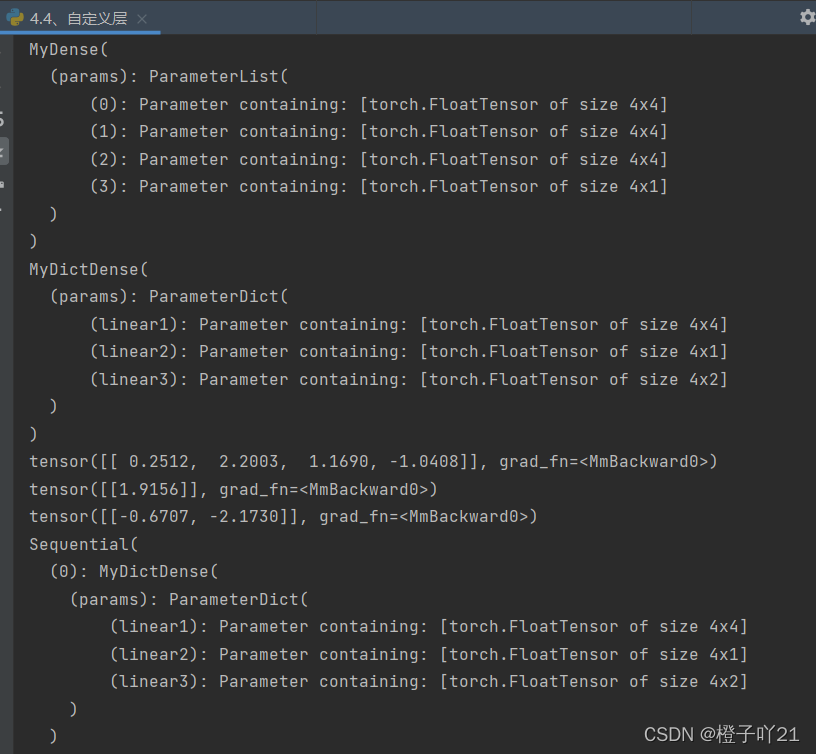

















 1537
1537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









