






发生在1912年的泰坦尼克事件,导致船上2224名游客死亡1502(我们的男主角也牺牲了),作为事后诸葛亮,我们掌握了船上乘客的一些个人信息和一部分乘客是否获救的信息。我们希望能通过探索这些数据,发现一些不为人知的秘密随便预测下另外一部分乘客是否能够获救。下面将用pandas进行数据预处理,用matplotlib进行画图,用sklearn进行模型的训练和预测
前期准备:
pip install pandas
pip install numpy
pip install matplotlib
pip install sklearn加载数据集并进行数据预处理
def get_csv(path):
train = pd.read_csv(path, index_col=0)
print(train.head())
print("处理前数据总量为:{}".format(len(train)))
print("含有缺失值数量:\n{}".format(train.isnull().sum()))
# 缺失值过多 删除cabin列
train.drop('Cabin', axis=1, inplace=True)
# 将没有年龄得设置为平均年龄
train['Age'] = np.where(train['Age'].isnull(), np.mean(train['Age']), train['Age'])
# 将没有票价得设置为平均数票价
train['Fare'] = np.where(train['Fare'].isnull(), np.mean(train['Fare']), train['Fare'])
# 删除没有embrked的两条空数据
train = train.dropna(subset=["Embarked"])
print("处理后数据总量为:{}".format(len(train)))
print("含有缺失值数量:\n{}".format(train.isnull().sum()))
return train数据结构为:

数据分析(初步了解数据之间的相关性,为特征选取和模型建立做准备。进行统计学与绘图,分析各参数和存活之间的关系)
客舱等级
def create_charts_pclass():
train = get_csv()
# 取生存行和等级行
df1 = train[["Pclass", "Survived"]]
group = df1.groupby(["Pclass"]) # 按等级分组
df = group.sum() # 分组求和
df['notSurvived'] = group.size() - df['Survived'] # 总数减去活着的人等于私人
df['survived_rate'] = df['Survived'] / (df['notSurvived'] + df['Survived'])
# hanshu=np.polyfit(df.index.tolist(),df.survived_rate.tolist(),2)
print(df)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.scatter(df.index.tolist(), df.survived_rate.tolist(), marker='o')
plt.plot(df.index.tolist(), df.survived_rate.tolist())
plt.title("客舱等级和生存率之间的关系")
plt.xlabel("舱位等级")
plt.ylabel("生存率")
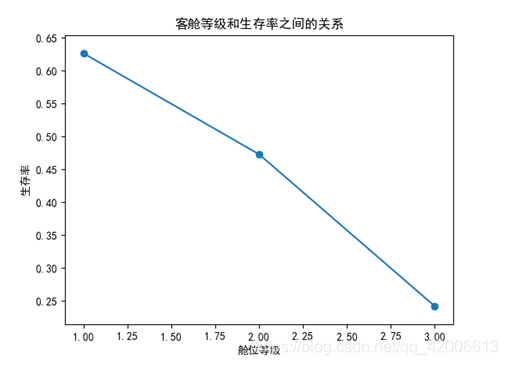
plt.show()根据训练集首先将客舱等级和生存列提取出来,然后根据客舱等级进行分组后求和,求和结果为存活的人,用存活人数除以总数即可得到不同客舱等级的存活率,根据存活率拟合一条曲线如图所示,可以看到一个简单的线性关系,等级越低,生存率越低
性别
def create_charts_sex():
train = get_csv()
df1 = train[['Sex', 'Survived']]
group = df1.groupby("Sex")
df = group.sum()
df['notSurvived'] = group.size() - df['Survived']
df.plot(kind="bar")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.title("性别生存分析")
plt.show()
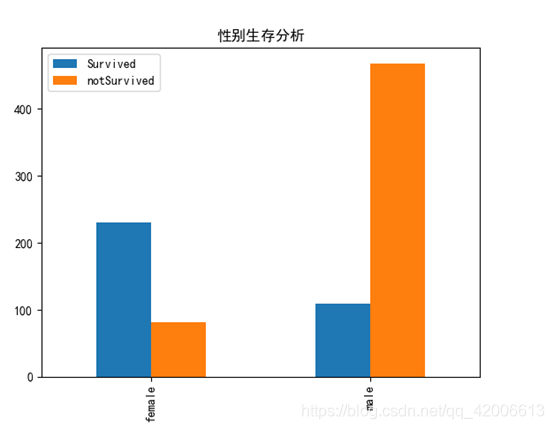
绘制性别分析柱形图可见男性存活率较低
年龄
def create_charts_age():
train = get_csv()
df1 = train[['Age', 'Survived']]
df1['High2'] = "老年"
df1.High2[df1.Age < 14] = "儿童"
df1.High2[(df1.Age <= 22) & (df1.Age > 14)] = "青年"
df1.High2[(df1.Age <= 34) & (df1.Age > 22)] = "中年"
df1 = df1[['High2', 'Survived']]
group = df1.groupby("High2")
df = group.sum()
df['notSurvived'] = group.size() - df['Survived']
df.plot(kind="bar")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.title("不同年龄段生存分析")
plt.show()
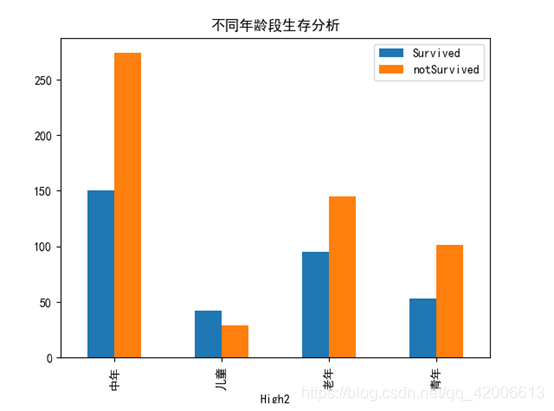
因年龄数据较为复杂,首先根据年龄将人群分为4种,小于14岁为儿童,小于22岁为青年,小于34岁为中年,大于34岁为老年然后绘制不同年龄段柱形图
上船港口
def create_chart_embraked():
train = get_csv()
# 取生存行和等级行
df1 = train[["Embarked", "Survived"]]
group = df1.groupby(["Embarked"]) # 按等级分组
df = group.sum() # 分组求和
df['notSurvived'] = group.size() - df['Survived'] # 总数减去活着的人等于私人
df['survived_rate'] = df['Survived'] / (df['notSurvived'] + df['Survived'])
print(df)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.scatter(df.index.tolist(), df.survived_rate.tolist(), marker='o')
plt.plot(df.index.tolist(), df.survived_rate.tolist())
plt.title("上船的港口编号和生存率之间的关系")
plt.xlabel("港口编号等级")
plt.ylabel("生存率")
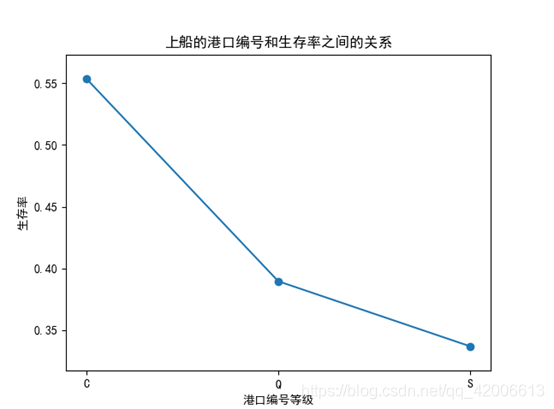
plt.show()采用和客舱等级相同的分析方法,进行线性拟合,结果如图,生存率随着港口编号C、Q、S依次降低
直系亲友和旁系
def create_chart_sp():
train = get_csv()
df1 = train[["Parch", "SibSp", "Survived"]]
df1['family_size'] = df1['SibSp'] + df1['Parch'] + 1
df1['family_samll'] = 0
df1['family_midle'] = 0
df1['family_big'] = 0
df1.family_samll[df1.family_size <= 1] = 1
df1.family_midle[(df1.family_size <= 4) & (df1.family_size >= 2)] = 1
df1.family_big[df1.family_size > 5] = 1
df = df1.groupby('family_size').sum()
print(df)
df['Survived'].plot()
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.title("家庭成员个数和幸存人数")
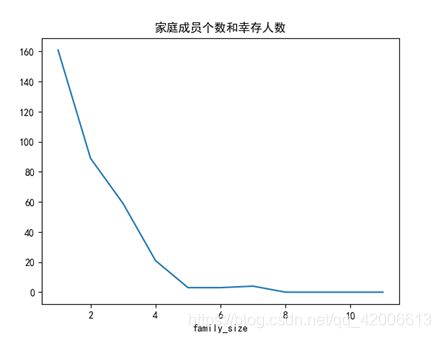
plt.show()分析方法为将直系亲友和旁及加1总计为一个家庭,根据家庭人数分为大家庭、小家庭和中家庭、根据家庭成员个数绘制与死亡直接的关系图
特征选取(根据上面统计结果图,比对各特征对survived值的影响,选取合适的特征)
#性别one-hot编码
full['Sex'] = np.where(full['Sex'] == "male", 1, 0)
#pclase one-hot编码
df_pclass =pd.get_dummies(full['Pclass'],prefix="pclass")
full = pd.concat([full,df_pclass],axis=1)
#age one-hot编码
full['age'] = "老年"
full.age[full.Age < 14] = "儿童"
full.age[(full.Age <= 22) & (full.Age > 14)] = "青年"
full.age[(full.Age <= 34) & (full.Age > 22)] = "中年"
df_age=pd.get_dummies(full['age'])
full = pd.concat([full, df_age], axis=1)
#family one-hot编码
full['family_size'] = full['SibSp'] + full['Parch'] + 1
full['family_samll'] = 0
full['family_midle'] = 0
full['family_big'] = 0
full.family_samll[full.family_size <= 1] = 1
full.family_midle[(full.family_size <= 4) & (full.family_size >= 2)] = 1
full.family_big[full.family_size > 5] = 1
#embarked one-hot编码
df_embarkd =pd.get_dummies(full['Embarked'])
full = pd.concat([full, df_embarkd], axis=1)
#删除无用列
del_list=["Pclass","Name","Age","SibSp","Parch","Ticket","Embarked","age"]
del full["Name"]
del full["Age"]
del full["SibSp"]
del full["Parch"]
del full["Ticket"]
del full["Embarked"]
del full['age']
del full["Pclass"]
# del full["Fare"]
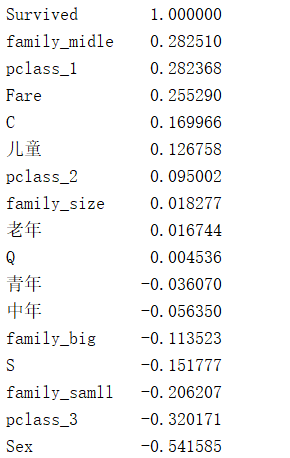
print(full)根据分析将性别,船舱等级,年龄,家庭成员个数,上床的港口编号进行one-hot编码 ,方便后期进行机器学习,在将原始多余的列名进行删除。调用corr方法生成相关性,查看和surivived相关性最强的列名。由图可知,性别,船舱等级,票价,港口编号对survived影响较大,年龄段影响较小
建立模型(选取合适的算法建立预测模型,将测试集带入模型得预测结果)。
上文已将训练集和测试集进行了合并进行了数据预处理,这里进行一下拆分。889为训练集长度。用LogisticRegression进行模型训练,传入训练集。生成正确率,
fina_train = full.drop(['Survived'],axis=1)
print(full)
len_sour=889
x=fina_train.loc[0:len_sour-1,:]
y=full.loc[0:len_sour-1,'Survived']
pred_x = fina_train.loc[len_sour:,:]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=.8)
model=LogisticRegression()
model.fit(x_train,y_train)
print("正确率为:{}".format(model.score(x_test,y_test)*100))
结果为:
![]()
使用刚才训练好的模型,对测试集进行预测,生成预测结果
pred_y = model.predict(pred_x)
pred_y=pred_y.astype(int)
print(pred_y)
预测结果为:

注:具体代码请参考py文件,文档中部分代码省略,如果需要源码和数据文件,点击链接即可下载,0积分哦
https://download.youkuaiyun.com/download/qq_42006613/89297880


















 1281
1281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











