






java解析PDF文档中的表格数据,处理合并单元格问题
背景
需要从PDF文档中提取里面的表格数据,支持简单表格解析、合并单元格的解析。
原理
自动识别PDF文档中有横竖线的,认为是表格部分,没有横竖线的部分会自动忽略。
前提是PDF不能为图片内容。
实现
- 引入tabula三方工具
<!-- tabula工具从pdf中获取表格数据-->
<dependency>
<groupId>technology.tabula</groupId>
<artifactId>tabula</artifactId>
<version>1.0.5</version>
<exclusions>
<exclusion>
<artifactId>slf4j-simple</artifactId>
<groupId>org.slf4j</groupId>
</exclusion>
</exclusions>
</dependency>
- 使用我写的ReadPdfTableUtil工具类,这里面有用虚拟表的方式很好的处理了合并单元格的问题,将合并单元格拆成独立单元格,合并单元格之前的值赋给每个独立单元格。
package com.example.demo.readPDFUtil.v3;
import cn.hutool.core.util.StrUtil;
import lombok.extern.slf4j.Slf4j;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.springframework.util.CollectionUtils;
import technology.tabula.Cell;
import technology.tabula.ObjectExtractor;
import technology.tabula.Page;
import technology.tabula.PageIterator;
import technology.tabula.RectangularTextContainer;
import technology.tabula.Ruling;
import technology.tabula.Table;
import technology.tabula.extractors.SpreadsheetExtractionAlgorithm;
import javax.annotation.Nonnull;
import java.io.File;
import java.lang.reflect.Field;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Objects;
import java.util.Set;
import java.util.stream.Collectors;
/**
* 解析PDF文档中的表格数据
* @author yanshaoli
* @date 2025/1/13 16:12
**/
@Slf4j
@SuppressWarnings("all")
public class ReadPdfTableUtil {
private static final SpreadsheetExtractionAlgorithm SPREADSHEEET_EXTRACTION_ALGORITHM = new SpreadsheetExtractionAlgorithm();
/**
* 读取pdf文档里面的表格数据
* 默认第一行开始读取
*
* @param file 文件
* @return 读取的内容
*/
public static List<List<String>> parsePdfTableForTasks(@Nonnull File file) {
return parsePdfTableForTasks(file, 0);
}
/**
* 读取pdf文档里面的表格数据
*
* @param file 文件
* @param customStart 读取起始行
* @return 读取的内容
*/
public static List<List<String>> parsePdfTableForTasks(@Nonnull File file, Integer customStart) {
customStart = Objects.isNull(customStart) ? 0 : customStart;
// 存储解析后的数据
List<List<String>> resultStr = new ArrayList<>();
try (PDDocument document = PDDocument.load(file)) {
// 获取页面迭代器
PageIterator pi = new ObjectExtractor(document).extract();
// 遍历所有页面
while (pi.hasNext()) {
// 获取当前页
Page page = pi.next();
// 解析页面上的所有表格
List<Table> tableList = SPREADSHEEET_EXTRACTION_ALGORITHM.extract(page);
for (Table table : tableList) {
List<Ruling> verticalRulings = getParentField(table, "verticalRulings");
List<Ruling> horizontalRulings = getParentField(table, "horizontalRulings");
// 创建虚拟表格
List<List<RectangularTextContainer>> virtualTable = createVirtualTable(verticalRulings, horizontalRulings);
if (CollectionUtils.isEmpty(virtualTable)) {
continue;
}
// 获取表格中的每一行
List<List<RectangularTextContainer>> rowList = table.getRows();
// 虚拟表格填充数据
Set<RectangularTextContainer> rectangularTextContainerList = rowList.stream().flatMap(List::stream).collect(Collectors.toSet());
for (List<RectangularTextContainer> row : virtualTable) {
for (RectangularTextContainer cell : row) {
searchCellText(rectangularTextContainerList, cell);
}
}
// 遍历所有行并获取每个单元格信息
for (int rowIndex = customStart; rowIndex < virtualTable.size(); rowIndex++) {
// 获取行中的每个单元格
List<RectangularTextContainer> cellList = virtualTable.get(rowIndex);
List<String> elementStr = new ArrayList<>();
for (RectangularTextContainer rectangularTextContainer : cellList) {
String text = rectangularTextContainer.getText();
if (StrUtil.isEmpty(text)){
text=" ";
}
String textString = null;
if (StrUtil.isNotEmpty(text)) {
textString = text.replace("\t", "").replace("\n", "").replace("\r", "");
}
elementStr.add(textString);
}
resultStr.add(elementStr);
}
}
}
} catch (Exception e) {
log.error("读取PDF错误:{}",e.getMessage());
}
return resultStr;
}
/**
* 覆盖方式寻找cell的text值
*
* @param rectangularTextContainerList 单元格容器集合
* @param cellContainer 当前单元格容器
*/
public static void searchCellText(Set<RectangularTextContainer> rectangularTextContainerList,
RectangularTextContainer cellContainer) {
for (RectangularTextContainer entry : rectangularTextContainerList) {
boolean found = entry.contains(cellContainer);
if (found && entry.getTextElements() != null) {
cellContainer.setTextElements(entry.getTextElements());
break;
}
}
}
/**
* 反射获取横纵线坐标
* @param instance 实例对象
* @param elementName 元素
* @return
*/
public static List<Ruling> getParentField(Object instance, String elementName) {
try {
Class<?> clazz = instance.getClass();
Field field = clazz.getDeclaredField(elementName);
field.setAccessible(true);
return (List<Ruling>) field.get(instance);
} catch (Exception e) {
log.error("getParentField failed. elementName:{}", elementName, e);
return null;
}
}
/**
* 创建拆解合并后的虚拟空表格
* verticalRulings 垂直线
* horizontalRulings 水平线
*
* @return List<List<RectangularTextContainer>> 虚拟空表格
*/
public static List<List<RectangularTextContainer>> createVirtualTable(
List<Ruling> verticalRulings, List<Ruling> horizontalRulings
) {
if (CollectionUtils.isEmpty(verticalRulings) || CollectionUtils.isEmpty(horizontalRulings)) {
return null;
}
// 预处理 verticalRulings
List<Ruling> verticalRulingsNew = verticalRulings;
// 预处理 horizontalRulings
Set y1Set = new HashSet<>(verticalRulings.size());
List<Ruling> horizontalRulingsNew = new ArrayList(horizontalRulings.size());
for (int i = 0; i < horizontalRulings.size(); i++) {
Ruling ruling = horizontalRulings.get(i);
if (y1Set.contains(ruling.y1)) {
continue;
}
y1Set.add(ruling.y1);
horizontalRulingsNew.add(ruling);
}
int rowCount = horizontalRulingsNew.size() - 1;
int colCount = verticalRulingsNew.size() - 1;
List<List<RectangularTextContainer>> virtualTable = new ArrayList<>(rowCount);
for (int rowIndex = 0; rowIndex < rowCount; rowIndex++) {
List<RectangularTextContainer> row = new ArrayList<>(colCount);
for (int colIndex = 0; colIndex < colCount; colIndex++) {
if (colIndex + 1 > colCount || rowIndex + 1 > rowCount) {
continue;
}
// x
float x = verticalRulingsNew.get(colIndex).x1;
// y
float y = horizontalRulingsNew.get(rowIndex).y1;
// w
float w = verticalRulingsNew.get(colIndex+1).x1 - x;
// h
float h = horizontalRulingsNew.get(rowIndex+1).y1 - y;
if (w == 0 || h == 0) {
continue;
}
Cell cell = new Cell(y, x, w, h);
row.add(cell);
}
virtualTable.add(row);
}
return virtualTable;
}
}
- 单测
准备一个PDF文档:放在resources下的
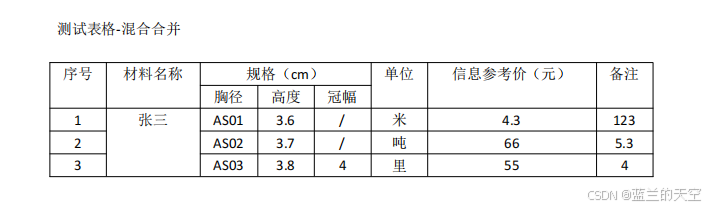
写一个单测方法
@Test
public void testHybridMerge(){
URL url = getClass().getClassLoader().getResource("pdftable/test_table_hybrid_merge.pdf");
assert url != null;
File file = new File(url.getFile());
// 读取数据
List<List<String>> strings = ReadPdfTableUtil.parsePdfTableForTasks(file);
for (List<String> elements : strings) {
for (String ele : elements) {
System.out.print(ele + "\t");
}
System.out.println();
}
}
输出结果

工具返回结果List<List>为通用的二维结构,数据是完整的,可以根据实际需求做适当二次开发。
说明
之前看到过有别人的博客写pdf解析表格的,但没有很好的处理合并单元格的问题,刚好工作上也遇到了这个需求,心血来潮,动手撸完。代码可能没那么完美,欢迎指教!!!

















 733
733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









