






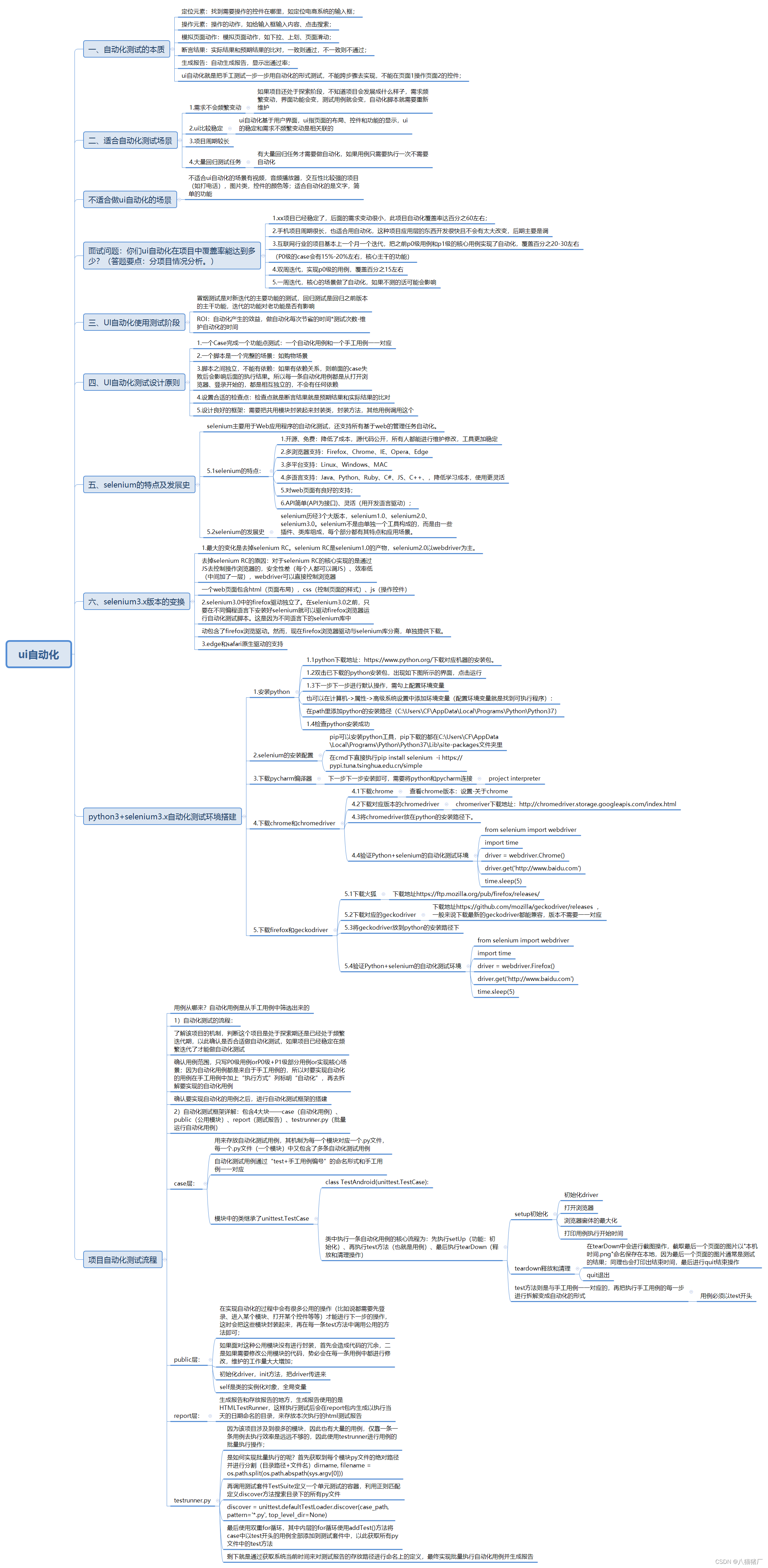
from selenium import webdriver #导入selenium的webdriver模块
yiyuan=webdriver.Chrome() #初始化webdriver
yiyuan.get('http://101.133.169.100:8090') #打开浏览器输入url进入医院系统的登录页面
yiyuan.find_element_by_id('LoginEmail').send_keys('111') #给邮箱框中传入数据
yiyuan.find_element_by_id('LoginPassword').send_keys('111')#给密码框传入数据
yiyuan.find_element_by_id('loginId').click()#点击登录按钮
#
from selenium import webdriver #导入selenium的webdriver模块
dianshang=webdriver.Chrome() #初始化webdriver
dianshang.get('http://101.133.169.100/yuns/index.php') #打开浏览器输入url
dianshang.find_element_by_name('key').send_keys('111') #给搜索框传入数据
from selenium import webdriver #导入selenium的webdriver模块
baidu=webdriver.Chrome() #初始化webdriver
baidu.get('http://www.baidu.com') #打开浏览器输入url
baidu.find_element_by_name('tj_briicon').click() #点击更多按钮
from selenium import webdriver #导入selenium的webdriver模块
baidu=webdriver.Chrome() #初始化webdriver
baidu.get('http://www.baidu.com') #打开浏览器输入url
baidu.find_element_by_name('wd').send_keys('111') #搜索框输入数据
baidu.find_element_by_id('su').click() #点击百度一下按钮
from selenium import webdriver #导入selenium的webdriver模块
dianshang=webdriver.Chrome() #初始化webdriver
dianshang.get('http://101.133.169.100/yuns/index.php') #打开浏览器输入url
dianshang.find_element_by_class_name('but1').send_keys('男装')
dianshang.find_element_by_class_name('but2').click()#点击搜索按钮
from selenium import webdriver #导入selenium的webdriver模块
baidu=webdriver.Chrome() #初始化webdriver
baidu.get('https://zhidao.baidu.com/') #打开浏览器输入url
baidu.find_element_by_class_name('i-ask-link').click() #点击我要提问按钮
from selenium import webdriver #导入selenium的webdriver模块
dianshang=webdriver.Chrome() #初始化webdriver
dianshang.get('http://101.133.169.100/yuns/index.php') #打开浏览器输入url
dianshang.find_element_by_link_text('登录').click() #点击登录按钮
from selenium import webdriver #导入selenium的webdriver模块
dianshang=webdriver.Chrome() #初始化webdriver
dianshang.get('http://101.133.169.100/yuns/index.php') #打开浏览器输入url
dianshang.find_element_by_link_text('秒杀').click() #点击秒杀按钮
from selenium import webdriver #导入selenium的webdriver模块
dianshang=webdriver.Chrome() #初始化webdriver
dianshang.get('http://101.133.169.100/yuns/index.php') #打开浏览器输入url
dianshang.find_element_by_link_text('男装女装').click() #点击男装女装按钮
from selenium import webdriver #导入selenium的webdriver模块
dianshang=webdriver.Chrome() #初始化webdriver
dianshang.get('http://101.133.169.100/yuns/index.php') #打开浏览器输入url
dianshang.find_element_by_partial_link_text('夏天').click() #点击夏天最热按钮
from selenium import webdriver #导入selenium的webdriver模块
dianshang=webdriver.Chrome() #初始化webdriver
dianshang.get('http://101.133.169.100/yuns/index.php') #打开浏览器输入url
dianshang.find_element_by_partial_link_text('整点秒').click() #点击整点秒杀按钮
from selenium import webdriver #导入selenium的webdriver模块
dianshang=webdriver.Chrome() #初始化webdriver
dianshang.get('http://101.133.169.100/yuns/index.php') #打开浏览器输入url
dianshang.find_element_by_partial_link_text('阿里推出').click() #点击阿里推出88VIP卡按钮
# xpath绝对路径
# 电商系统点击秒杀按钮,使用xpath绝对路径定位
from selenium import webdriver #导入selenium的webdriver模块
dianshang=webdriver.Chrome() #初始化webdriver
dianshang.get('http://101.133.169.100/yuns/index.php')
dianshang.find_element_by_xpath("/html/body/div[3]/div/div/a[2]").click()
# 电商系统搜索女装,使用xpath绝对路径定位
from selenium import webdriver #导入selenium的webdriver模块
dianshang=webdriver.Chrome() #初始化webdriver
dianshang.get('http://101.133.169.100/yuns/index.php')
dianshang.find_element_by_xpath("/html/body/div/div/div/div/form/input[1]").send_keys('女装')
dianshang.find_element_by_xpath("/html/body/div/div/div/div/form/input[2]").click()
# xpath相对路径
# 百度搜索优快云,使用xpath相对路径
from selenium import webdriver
import time
baidu=webdriver.Chrome()
baidu.get('http://www.baidu.com')
time.sleep(2)
baidu.find_element_by_xpath("//input[@name='wd']").send_keys('优快云')
baidu.find_element_by_xpath("//input[@type='submit']").click()
# 如果属性不唯一,可以通过两个属性一起定位
# 博客园网站搜索框搜索测试,通过两个属性一起定位
from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get('https://www.cnblogs.com/')
driver.find_element_by_xpath("//input[@name='w' and @id='zzk_search_input']").send_keys('测试')
driver.find_element_by_xpath("//button[@type='submit' and @id='zzk_search_button' ]").click()
# 博客园网站点击精华按钮,通过两个属性一起定位
from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get('https://www.cnblogs.com/')
driver.find_element_by_xpath("//li[@id='sidenav_pick' and @class='sidenav-item ']").click()
# 某个控件属性包含某部分值定位
# 博客园网站搜索框输入自动化,通过placeholder属性中包含的“代码改变”定位
from selenium import webdriver
driver=webdriver.Chrome()
driver.get('https://www.cnblogs.com/')
driver.find_element_by_xpath("//input[contains(@placeholder,'代码改变')]").send_keys('自动化')
# 博客园网站点击精华按钮,通过title属性中包含的“精”定位
from selenium import webdriver
driver=webdriver.Chrome()
driver.get('https://www.cnblogs.com/')
driver.find_element_by_xpath("//a[contains(@title,'精')]").click()
# 博客园网站点击候选按钮,通过title属性中包含的“候”定位
from selenium import webdriver
driver=webdriver.Chrome()
driver.get('https://www.cnblogs.com/')
driver.find_element_by_xpath("//a[contains(@title,'候')]").click()
# 根据文本信息定位,*代表所有标签
# 博客园网站点击新闻按钮,通过文本信息“新闻”定位
from selenium import webdriver
driver=webdriver.Chrome()
driver.get('https://www.cnblogs.com/')
driver.find_element_by_xpath("//a[text()='新闻']").click()
# 博客园网站点击专区按钮,通过文本信息“专区”定位
from selenium import webdriver
driver=webdriver.Chrome()
driver.get('https://www.cnblogs.com/')
driver.find_element_by_xpath("//a[text()='专区']").click()
# 博客园网站点击班级按钮,通过文本信息“班级”定位,*代表所有标签
from selenium import webdriver
driver=webdriver.Chrome()
driver.get('https://www.cnblogs.com/')
driver.find_element_by_xpath("//*[text()='班级']").click()
# 博客园网站点击博问按钮,通过文本信息“博问”定位,*代表所有标签
from selenium import webdriver
driver=webdriver.Chrome()
driver.get('https://www.cnblogs.com/')
driver.find_element_by_xpath("//*[text()='博问']").click()
#
# 自身没有特殊属性,往父级找
# 博客园网站点击精华按钮,通过父级找特殊属性继续写相对路径
from selenium import webdriver
driver=webdriver.Chrome()
driver.get('https://www.cnblogs.com/')
driver.find_element_by_xpath("//div[@id='side_nav']/ul/li[1]/a/span").click()
# 博客园网站点击精华按钮,通过父级找特殊属性继续写相对路径
from selenium import webdriver
driver=webdriver.Chrome()
driver.get('https://www.cnblogs.com/')
driver.find_element_by_xpath("//ul[@class='sidenav']/li[1]/a").click()
# 博客园网站点击新闻按钮,通过父级找特殊属性继续写相对路径
from selenium import webdriver
driver=webdriver.Chrome()
driver.get('https://www.cnblogs.com/')
driver.find_element_by_xpath("//ul[@id='nav_left']/li[3]/a").click()
# 从子级找父级,返回上一级用/..
# 博客园网站点击我评按钮,通过子级找父级写相对路径
from selenium import webdriver
driver=webdriver.Chrome()
driver.get('https://www.cnblogs.com/')
driver.find_element_by_xpath("//a[@title='我评论过的博文']/..").click()
#
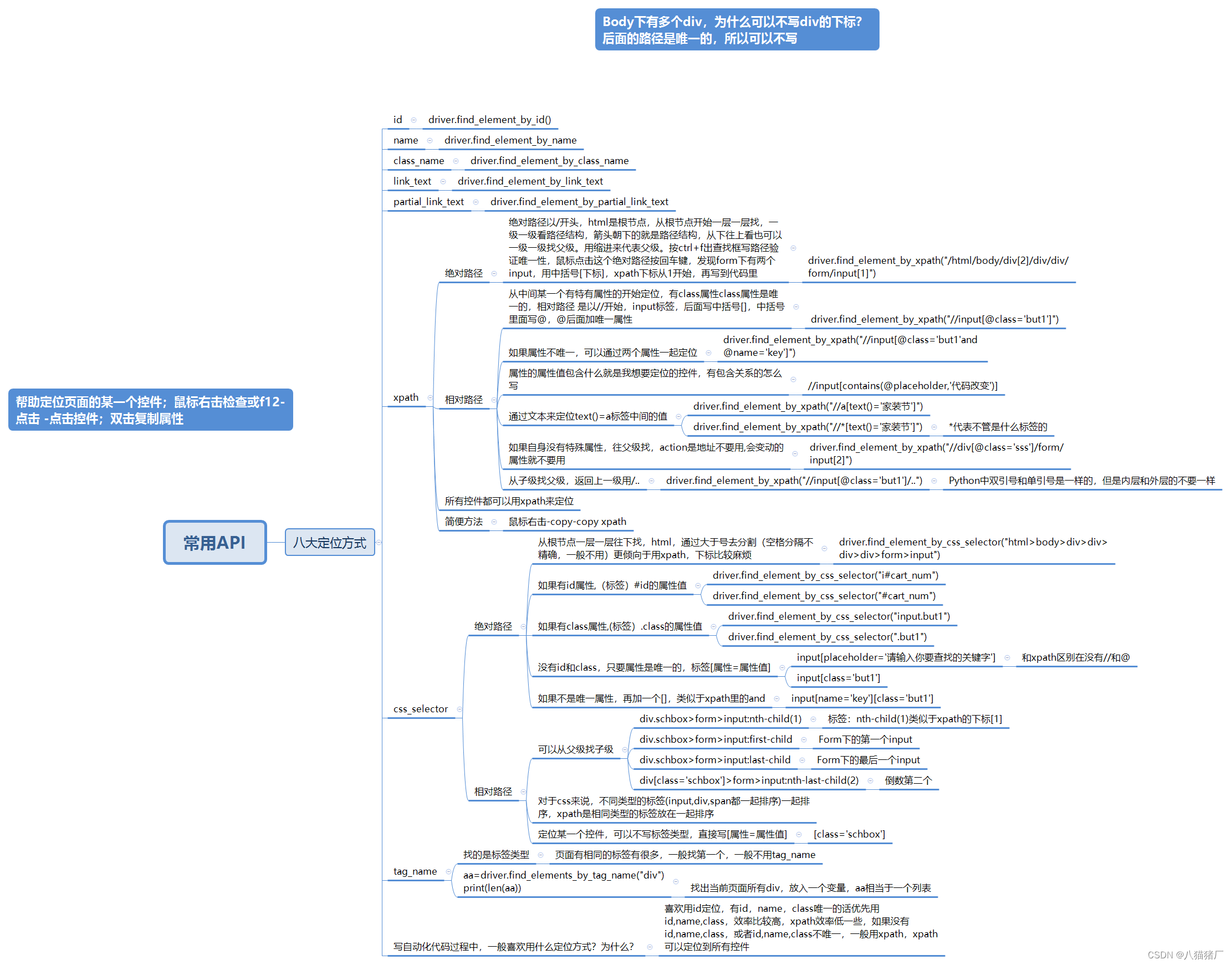
# css绝对路径
# 电商系统点击登录按钮,用css绝对路径定位
from selenium import webdriver #导入selenium的webdriver模块
dianshang=webdriver.Chrome() #初始化webdriver
dianshang.get('http://101.133.169.100/yuns/index.php')
dianshang.find_element_by_css_selector("html>body>div>div>div>div>div>p>a").click()
# 电商系统点击关于我们按钮,用css绝对路径定位
from selenium import webdriver #导入selenium的webdriver模块
dianshang=webdriver.Chrome() #初始化webdriver
dianshang.get('http://101.133.169.100/yuns/index.php')
dianshang.find_element_by_css_selector("html>body>div:nth-child(10)>div>div>div>dl:nth-child(1)>dd>a").click()
# 电商系统点击免费注册按钮,用css绝对路径定位
from selenium import webdriver #导入selenium的webdriver模块
dianshang=webdriver.Chrome() #初始化webdriver
dianshang.get('http://101.133.169.100/yuns/index.php')
dianshang.find_element_by_css_selector("html>body>div:nth-child(1)>div:nth-child(1)>div:nth-child(2)>a:nth-child(3)").click()
# css相对路径有id属性,也可以不写标签
# 博客园网站点击专区按钮,用css方法id属性定位
from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get('https://www.cnblogs.com/')
time.sleep(2)
driver.find_element_by_css_selector("a#nav_brandzone").click()
# 博客园网站点击专区按钮,用css方法id属性定位,不写标签
from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get('https://www.cnblogs.com/')
time.sleep(2)
driver.find_element_by_css_selector("#nav_brandzone").click()
# 博客园网站点击精华按钮,用css方法id属性定位
from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get('https://www.cnblogs.com/')
time.sleep(2)
driver.find_element_by_css_selector("li#sidenav_pick").click()
# 博客园网站点击候选按钮,用css方法id属性定位,不写标签
from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get('https://www.cnblogs.com/')
time.sleep(2)
driver.find_element_by_css_selector("li#sidenav_candidate").click()
# 如果有class属性,(标签).class的属性值,也可以不写标签
# 博客园网站点击发现按钮,用css方法id和class属性
from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get('https://www.cnblogs.com/')
time.sleep(2)
driver.find_element_by_css_selector("ul#nav_left>li.dropdown>div.dropdown-button").click()
# 博客园网站点击发现按钮,用css方法id和class属性,不写标签
from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get('https://www.cnblogs.com/')
time.sleep(2)
driver.find_element_by_css_selector("#nav_left>.dropdown>.dropdown-button").click()
# 博客园网站点击博客园图标,用css方法id和class属性
from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get('https://www.cnblogs.com/')
time.sleep(2)
driver.find_element_by_css_selector("ul#nav_left>li.navbar-branding").click()
# 没有id和class,只要属性是唯一的,标签[属性=属性值],可以不写标签类型
# 博客园网站搜索框输入111,用css定位
from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get('https://www.cnblogs.com/')
time.sleep(2)
driver.find_element_by_css_selector("input[placeholder='代码改变世界']").send_keys("111")
# 博客园网站点击发现按钮,用css定位
from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get('https://www.cnblogs.com/')
time.sleep(2)
driver.find_element_by_css_selector("ul[id='nav_left']>li[class='dropdown']>div[class='dropdown-button']").click()
# 博客园网站点击精华按钮,用css定位
from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get('https://www.cnblogs.com/')
time.sleep(2)
driver.find_element_by_css_selector("li#sidenav_pick>[title='精华区博文']").click()
# 如果不是唯一属性,再加一个[],类似于xpath里的and
# 博客园网站点击订阅按钮,用css通过两个属性一起定位
from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get('https://www.cnblogs.com/')
time.sleep(2)
driver.find_element_by_css_selector("li[id='sidenav_subscription'][class='sidenav-item ']").click()
# 博客园网站搜索框输入222,用css通过两个属性一起定位
from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get('https://www.cnblogs.com/')
time.sleep(2)
driver.find_element_by_css_selector("input[name='w'][id='zzk_search_input']").send_keys('222')
# 标签:nth-child()下标
# 博客园网站点击注册按钮,用css方法找标签的下标定位
from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get('https://www.cnblogs.com/')
time.sleep(2)
driver.find_element_by_css_selector("li#navbar_login_status>a:nth-child(5)").click()
#
# input:first-child 第一个input
# 博客园网站点击博客园图标,用css方法找标签的第一个下标定位
from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get('https://www.cnblogs.com/')
time.sleep(2)
driver.find_element_by_css_selector("ul#nav_left>li:first-child").click()
# input:last-child最后一个input
# 博客园网站点击发现按钮,用css方法找标签的最后一个下标定位
from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get('https://www.cnblogs.com/')
time.sleep(2)
driver.find_element_by_css_selector("ul#nav_left>li:last-child").click()
# input:nth-last-child(2)倒数第二个input
# 博客园网站点击怀旧按钮,用css方法找标签的倒数第二个下标定位
from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get('https://www.cnblogs.com/')
time.sleep(2)
driver.find_element_by_css_selector("ul#nav_left>li:nth-last-child(2)>a").click()
#浏览器
from selenium import webdriver
import time
driver = webdriver.Chrome()
#打开悟空系统
driver.get("http://101.133.169.100:8088/index.html")
#设置窗体长1200宽720
driver.set_window_size(1200,800)
time.sleep(5)
#窗体设置最大化
driver.maximize_window()
time.sleep(5)
#获取浏览器title,网页标签的名字
title=driver.title
print(title)
#获取当前页面URL
url=driver.current_url
print(url)
#刷新浏览器
driver.refresh()
time.sleep(5)
#回退浏览器
driver.back()
time.sleep(5)
#前进浏览器
driver.forward()
time.sleep(5)
#关闭浏览器
driver.quit()
#动作事件
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("http://101.133.169.100:8088/index.html")
#输入框输入内容:用户名输入框输入111
driver.find_element_by_xpath("//input[@type='text']").send_keys("111")
time.sleep(5)
#清空输入框内容:清空用户名输入框内容
driver.find_element_by_xpath("//input[@type='text']").clear()
time.sleep(5)
#点击控件:点击登录按钮
driver.find_element_by_css_selector(".el-form-item__content>button").click()
#属性方法获取
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("http://101.133.169.100:8088/index.html")
#获取控件尺寸:获取用户名输入框尺寸,输出长和宽
size = driver.find_element_by_xpath("//input[@type='text']").size
print(size)
#获取输入框默认值:获取用户名输入框中的默认值
at = driver.find_element_by_xpath("//input[@type='text']").get_attribute("placeholder")
print(at)
#获取文本框信息:获取悟空CRM系统文本框信息
text = driver.find_element_by_css_selector('.title').text
print(text)
# 判断控件是否加载完成:判断用户名输入框是否加载完成,输出加载结果,结果为布尔类型,True/Flase
dis = driver.find_element_by_xpath("//input[@type='text']").is_displayed()
print(dis)
#如果用户名输入框加载完成,向用户名输入框中输入111,如果没有加载完成输入222
if dis==True:
driver.find_element_by_xpath("//input[@type='text']").send_keys("111")
#输入内容查看输入框回显值:获取用户名输入框中的回显值,固定传value
value=driver.find_element_by_xpath("//input[@type='text']").get_attribute('value')
print(value)
time.sleep(5)
else:
time.sleep(5)
driver.find_element_by_xpath("//input[@type='text']").send_keys("222")
driver.quit()
#鼠标事件
from selenium import webdriver
#先导入鼠标事件的类
from selenium.webdriver.common.action_chains import ActionChains
import time
driver = webdriver.Chrome()
driver.get("https://www.huodongxing.com/login")
time.sleep(2)
#定位活动行网站上的全国按钮
ele = driver.find_element_by_css_selector('.hdx-feature-head-bottom-new>.auto-width>div>.city-select>p')
time.sleep(2)
#鼠标悬浮
ActionChains(driver).move_to_element(ele).perform()
time.sleep(2)
#右击控件
ActionChains(driver).context_click(ele).perform()
time.sleep(2)
#双击控件
ActionChains(driver).double_click(ele).perform()
#点击按钮进行验证
driver.find_element_by_css_selector(".geetest_radar_tip_content").click()
time.sleep(2)
#定位拖拽控件,将控件向x方向偏移50,y方向不偏移
source= driver.find_element_by_css_selector(".geetest_slider_button")
ActionChains(driver).drag_and_drop_by_offset(source,50,0).perform()
time.sleep(3)
#定位拖拽控件,将控件拖到另一个控件的位置
target= driver.find_element_by_css_selector(".geetest_feedback")
ActionChains(driver).drag_and_drop(source,target)
# 键盘事件+等待时间
from selenium import webdriver
import time
#导入键盘事件的类
from selenium.webdriver.common.keys import Keys
#导入等待时间的类
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
ele=WebDriverWait(driver,10,0.5).until(EC.presence_of_element_located((By.XPATH, "//input[@id='kw']")))
ele.send_keys("软件测试")
driver.maximize_window()
# 退格:将百度搜索框输入的软件测试文字删除一个字
driver.find_element_by_xpath("//input[@id='kw']").send_keys(Keys.BACK_SPACE)
# 隐式等待时间:最大等待5s,按实际等待时间处理
driver.implicitly_wait(5)
# 空格:在百度搜索框中输入空格
driver.find_element_by_xpath("//input[@id='kw']").send_keys(Keys.SPACE)
# ctrl:复制百度搜索框中的内容并粘贴
driver.find_element_by_xpath("//input[@id='kw']").send_keys(Keys.CONTROL,'a')
driver.find_element_by_xpath("//input[@id='kw']").send_keys(Keys.CONTROL,'c')
# 需要鼠标点击一下控件才能继续ctrl+v,否则看不出效果
driver.find_element_by_xpath("//input[@id='kw']").click()
driver.find_element_by_xpath("//input[@id='kw']").send_keys(Keys.CONTROL,'v')
# 回车
driver.find_element_by_xpath("//input[@id='kw']").send_keys(Keys.ENTER)
#强制等待时间
time.sleep(2)
driver.quit()
# 切换句柄/焦点+截图
# 打开新的窗体时,如果句柄或者焦点不在新的窗体,没有办法定位新窗体中的控件
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
#截图,图片保存以png格式,格式为图片保存路径/图片名称.png,图片存储路径必须要存在的路径
driver.get_screenshot_as_file("D:/test.png")
driver.maximize_window()
# 获取所有句柄
print(driver.window_handles)
# 获取当前句柄信息
print(driver.current_window_handle)
driver.find_element_by_css_selector("div[id='s-top-left']>a:nth-child(2)").click()
# 获取所有句柄,输出的列表,与之前未打开新窗口时比对
print(driver.window_handles)
# 获取当前句柄信息
print(driver.current_window_handle)
# 切换句柄,用列表形式,python中以0开头
driver.switch_to.window(driver.window_handles[1])
# 获取当前句柄信息,查看句柄是否切换成功
print(driver.current_window_handle)
time.sleep(2)
driver.quit()
# alert弹框处理
# alert弹框的处理练习
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get(r'file:\D:\测试\课程\web端ui自动化\testAlert.html')
#调出弹框
driver.execute_script("prom()")
time.sleep(5)
# 给输入框传入数据
driver.switch_to.alert.send_keys("测试")
time.sleep(5)
# 获取文字信息
print(driver.switch_to.alert.text)
time.sleep(5)
# 点击正向按钮(确定)
driver.switch_to.alert.accept()
time.sleep(5)
# 点击反向按钮(取消)
# driver.switch_to.alert.dismiss()
driver.quit()
# 切换iframe(在html里加了另一个html,有基层iframe就要切换几次)
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://mail.163.com/")
driver.maximize_window()
time.sleep(8)
# 第一种方式:有id或者name属性,如果id和name不会变化,跟id或者name对应的属性值
#driver.switch_to.frame("x-URS-iframe")
#第二种方式:通用方法,通过xpath切换iframe:先用xpath定位iframe,切换到该iframe,再输入内容
dd = driver.find_element_by_xpath("//div[@id='loginDiv']/iframe")
driver.switch_to.frame(dd)
driver.find_element_by_name('email').send_keys("111")
# 返回上一层frame
# driver.switch_to.parent_frame()
# 切换到最外层
# driver.switch_to.default_content()
time.sleep(2)
driver.quit()
# 下拉选择框
from selenium import webdriver
from selenium.webdriver.support.select import Select
import time
driver = webdriver.Chrome()
#打开写成网站
driver.get("https://www.ctrip.com/?sid=155952&allianceid=4897&ouid=index")
driver.maximize_window()
#定位房间数按钮
s=driver.find_element_by_id("J_roomCountList")
# 通过文本信息选择
Select(s).select_by_visible_text("2间")
time.sleep(2)
# 通过索引选择,0是第一个
Select(s).select_by_index(0)
time.sleep(2)
# 通过value选择,每一个选项都有对应value值
Select(s).select_by_value("2")
time.sleep(2)
driver.quit()
#时间控件
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://www.ctrip.com/?sid=155952&allianceid=4897&ouid=index")
driver.maximize_window()
# 普通时间控件,需按格式传日期内容
ele=driver.find_element_by_id('HD_CheckIn')
ele.clear()
ele.send_keys("2021-05-20")
# 特殊时间控件,有readonly属性,需要先移除readonly属性,再按格式传日期内容
# 有id属性
#js="document.getElementById('HD_CheckIn').removeAttribute('readonly')"
#有name属性
#js="document.getElementByName('HD_CheckIn').removeAttribute('readonly')"
#没有id和name,传标签类型
#js="document.getElementByTagName('input').removeAttribute('readonly')"
# #执行js
# driver.execute_script(js)
# driver.find_element_by_name('HD_CheckIn').send_keys("2021-05-19 23:50:50")
time.sleep(2)
driver.quit()
# 实现滚动条的处理
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://www.hao123.com/")
driver.maximize_window()
# 滚动到页面最底部
# 定义js,给一个较大的值
js = "var q=document.documentElement.scrollTop=10000"
# 执行js
driver.execute_script(js)
time.sleep(2)
# 滚到最顶部
#定义js,值给0
js = "var q=document.documentElement.scrollTop=0"
# 执行js
driver.execute_script(js)
time.sleep(2)
#滚动到窗体的高度的50%
driver.execute_script("window.scrollTo(0,document.body.scrollHeight*0.5)")
time.sleep(2)
# 根据当前滚动条位置向上滚200
driver.execute_script("window.scrollBy(0,-200)")
time.sleep(2)
driver.quit()
#批量运行casetestrunner.py代码:
#导入unittest框架,time,os,sys模块
import unittest
import time
import os,sys
#导入report包里的HTMLTesRunner这个类,用来生成报告
from report import HTMLTestRunner
#定义两个变量,sys.arg[0]拿到的是D:/测试/课程/06web端ui自动化/Uiframe0test/testrunner.py完整的路径
# 获取当前py文件路径地址,并进行路径分割(分割成dirname是目录路径和filename文件名称是py文件名字)
dirname,filename=os.path.split(os.path.abspath(sys.argv[0]))
print(dirname,filename)
case_path = ".\\case\\"
result = dirname+"\\report\\"
#定义一个方法
def Creatsuite():
#定义单元测试容器
#初始化unittest.testsuite的对象,testsuite是测试套件,存储多个test方法
testunit = unittest.TestSuite()
#定搜索用例文件的方法,在case_path中查找所有py文件,放入discover里
discover = unittest.defaultTestLoader.discover(case_path, pattern='*.py', top_level_dir=None)
#将测试用例加入测试容器中
#把所有py文件遍历一遍,把所有的test方法都拿出来
for test_suite in discover:
#先执行一次拿到第一个py文件,py文件的所有test方法加载到test_suite里,再执行一次遍拿到第二个py文件,再把第二个py文件里的test方法放到test_suite里
for casename in test_suite:
testunit.addTest(casename)
#print testunit
return testunit
#定义一个变量,调用creatsuite方法,所有py文件中的test方法
test_case = Creatsuite()
#获取系统当前时间
now = time.strftime('%Y-%m-%d-%H_%M_%S', time.localtime(time.time()))
day = time.strftime('%Y-%m-%d', time.localtime(time.time()))
#定义报告存放路径,日期的文件路径,支持相对路径
tdresult = result + day
if os.path.exists(tdresult): # 检验文件夹路径是否已经存在
#定义今天日期年月日时分秒的result的html报告的名称
filename = tdresult + "\\" + now + "_result.html"
#打开文件,以二进制形式写内容
fp = open(filename, 'wb')
#定义测试报告,把执行结果放入runner里
runner = HTMLTestRunner.HTMLTestRunner(stream=fp,
title='测试报告',
description='执行情况:')
#运行测试用例
runner.run(test_case)
fp.close() #关闭报告文件
else:
os.mkdir(tdresult) # 创建测试报告文件夹
filename = tdresult + "\\" + now + "_result.html"
fp = open(filename, 'wb')
#定义测试报告
runner = HTMLTestRunner.HTMLTestRunner(stream=fp,
title='Selenium测试报告',
description='执行情况:')
#运行测试用例
runner.run(test_case)
fp.close() #关闭报告文件


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









