



 本文介绍了Pandas库中的核心数据结构Series和DataFrame,详细讲解了它们的创建、索引与切片、属性以及数据处理方法。通过实例展示了如何利用Pandas进行数据操作,包括布尔索引、缺失值处理和排序。此外,还探讨了DataFrame与ndarray的区别,并提供了相关方法的使用示例。
本文介绍了Pandas库中的核心数据结构Series和DataFrame,详细讲解了它们的创建、索引与切片、属性以及数据处理方法。通过实例展示了如何利用Pandas进行数据操作,包括布尔索引、缺失值处理和排序。此外,还探讨了DataFrame与ndarray的区别,并提供了相关方法的使用示例。
作为一个初学者,能力有限,知识栈太浅,只能当做参考,并不是权威解答,更多的还是要自己动手敲代码实现,同时希望看到这篇blog的人可以能够不吝赐教,指出当中存在的问题。
pandas是机器学习中非常重要的一个工具,pandas是一个很强大的数据处理工具,主要用于机器学习中特征工程阶段的数据处理。
Series和DataFrame是pandas的两种重要数据结构,而DataFrame是由Series构成的。Series在pandas中表示为带索引的一维数据;dataframe则是pandas的多维数据
1.series数据的创建
如上所述,Series是pandas里的一种数据组织方式,可以将其看做是一维的数组,或是表格中的一列。
import pandas as pd # 导入pandas库
pd.Series([1,2,3,4,5]) # 创建series数据,不一定非要列表,也可以是元组或者是字典
pd.Series([1,2,3,4,5],index=list("abcde")) # index:设置索引,类似于字典里的key,我们可以通过这个索引来取series中的值
pd.Series((1,2,3,4)) # 用元组创建series
temp_dict = {"name":"xioaming","age":18,"sex":"man"} # 用字典创建series,当用字典创建series,会将key做为索引
Series数据的基本格式:
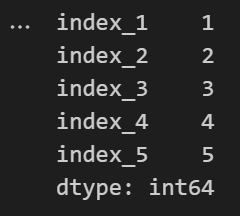
2.series的索引和切片
Series既可以用行标签索引,也可以用下标进行索引
- pandas里面很多方法用的是中括号,例如loc,iloc等,百度后才明白是符号的重写。在pandas学习的过程中它的属性,小括号,中括号非常容易弄混记错,千万不要弄晕了
data["name"] # 通过用行标签name进行取值
data["age"]
data[0] # 也可以通过下标索引取值。取索引下标为0的值,即第0行
data[1]
data[:2] # 切片获取0-2行的数据
data[[0,1]] # 也是切片,需要注意的是这里用的是两对中括号,如果我们只索引一个数据就可以用一对中括号,表示一维数据,用两个中括号就表示的是二维数据
data[["name","sex"]] # 效果同上,只不过用的不是下标,而是index标签
3.series的属性
data.index # 获取index标签值
data.values # 返回series的值 , 返回的是ndarray类型的数据
data.astype("string") # 将data转换成string类型的数据
4.DataFrame
DataFrame是非常非常适合机器学习的数据结构,列索引就是特征,一列就是一个特征,pandas里的值就是特征值,而行索引就是我们获取到的样本数据集,一行就是一个样本。
DataFrame的创建,及行列索引
data = pd.DataFrame(np.arange(12).reshape(3,4)) # 创建dataframe数据
data.index # 显示data的行索引标签
data.index = ["a","b","c"] # 修改行索引
~~data.index[0] = "f"~~ # 错误的修改方式,行列索引只能整体的全部更换,即不能单独换行索引中的一个,而是所有的行索引
data.columns # 显示data的列索引 因为series是一维的,所以不存在列索引
data.columns = ["one","two","three","four"] # 修改列索引
pd.DataFrame(np.arange(12).reshape(3,4),index=["a","b","c"]) # 也可以在定义dataframe时就定好行索引,列索引
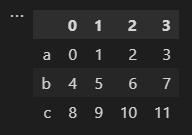
DataFrame和ndarray的区别:
DataFrame:
ndarray:
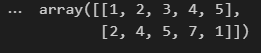
ndarray只是最基本的多维数组格式,而且里面的数据都要是同一类型,而DataFrame的数据格式可以不一样,存在行索引,列索引
DataFrame的属性和方法
# 属性
data.index # 显示data的行索引
data.dtypes # 显示每行的数据类型
data.shape # 显示data的大小
data.values # 显示data的值,就是dnarray格式,只是没了行索引和列索引
data.T # 将DataFrame转置
# 方法
data.info() # 显示data的概览信息
data.tail() # 显示尾部的几行数据
data.head() # 显示顶部的几行数据 在里面传参数,head(3)表示显示三行
索引和切片
data["one"] # 用列索引,索引单列数据
data["one"]["c"] # 先索引单列数据,再进行行索引
data[:2] # 切片,取前2行的数据
data[:2]["one"] # 先切片,取前两行;再索引,取切片后的,索引值为"one"的列的数据
# loc 和 iloc 的使用
data.loc["b","one"] # loc只能传索引标签获取数据,参数逗号前面的是行,后面是列,获取b行one列 需要注意的是loc和iloc都是用中括号,而不是小括号
data.loc[["a","c"],:] # 也是标签索引,但获取a,c多行所有列的数据
data.iloc[1,:] # 和loc不一样的是iloc只能用下标进行索引,其他的都相同 这里取得是第一行的数据
# 布尔索引
data[data>10] # 找出data的所有数据中 >10 的数据,其他<=10的数据,会显示成 NaN
data[data["one"]>130] # 找出one列中>130的数据
赋值
data.one # 居然可以直接通过 .列索引 获取该列数据
data.one = 123 # 将整列赋为123
data.iloc[0,0] = 124 # iloc索引位置后赋值
data.iloc[[0,1],0] = 129,221 # 也可以通过解包赋值
data
缺失值处理
缺失值处理在机器学习中是非常重要的一个工作,我们获取到的数据往往并不是都能获取到,当面临缺失值时可以试试以下的办法
# 判断data中是否有NaN
data.isnull() # 当元素不是nan时,显示的是false
np.any(data.isnull()) # 当数据太多时,isnull展现不出所有的结果,所以这个方法就非常有用,any表示只要有一个结果为true就返回true
# NaN处理方法一:直接删掉
data.dropna(axis=0) # 删除有NaN的行
data.dropna(subset=["one"],inplace=True) # 移除指定的列中出现了NaN值所在的整行 inplace:就地移除
# NaN处理方法二:填充
data.fillna(data.median) # 为data填充中位数
data["one"].fillna(data["one"].median,inplace=True) # 将data中列索引是one的那一列中的nan填充为该列的中位数
排序
# 对内容进行排序
data.sort_values(by="one",ascending=True) # by:按one字段排序
data["one"].sort_values(ascending=True) # 按one字段排序,和上面不同的是,排序后返回的只有one这一列,而上面返回的是DataFrame中所有的数据
# 对索引进行排序
data.sort_index(ascending=False)

















 9402
9402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









