







贝叶斯定理


朴素贝叶斯

朴素贝叶斯的几种模型
1.多项式模型
该模型常用于文本分类,特征是单词,值是单词的出现次数。

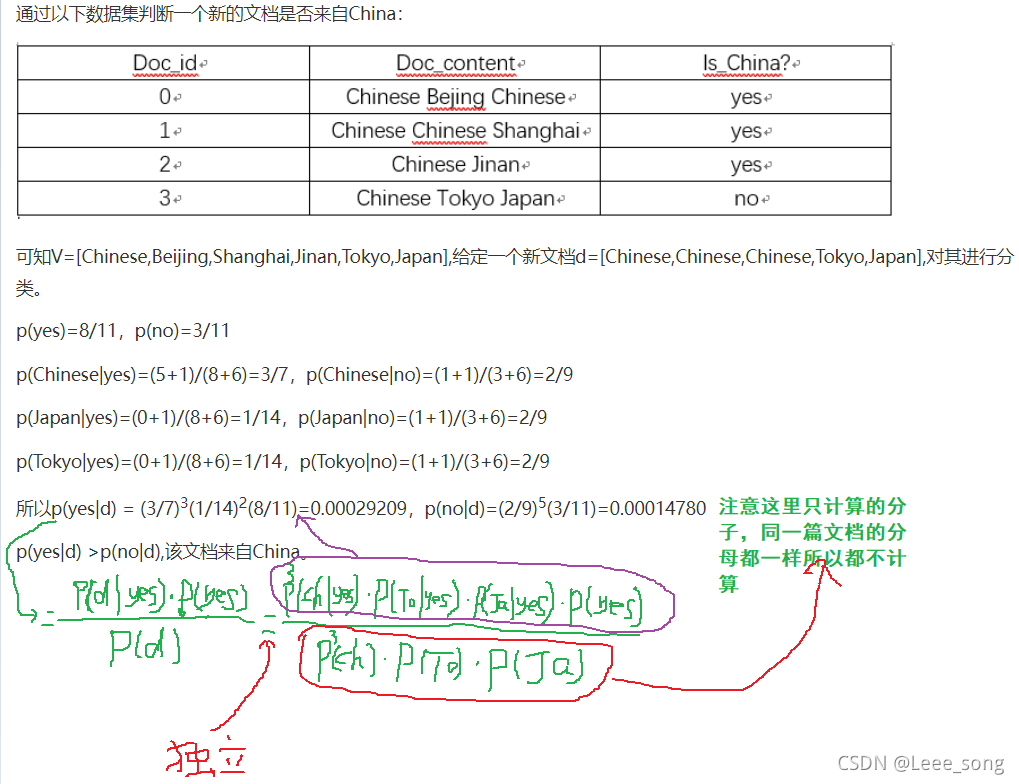
2.伯努利模型
在伯努利模型中,每个特征的取值是布尔型的,即true和false,或者1和0。在文本分类中,就是一个特征有没有在一个文档中出现。

3.高斯模型
处理连续的特征变量,应该采用高斯模型。
高斯分布(正态分布)的概率密度公式如下:
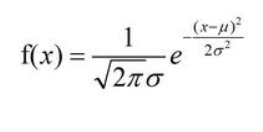
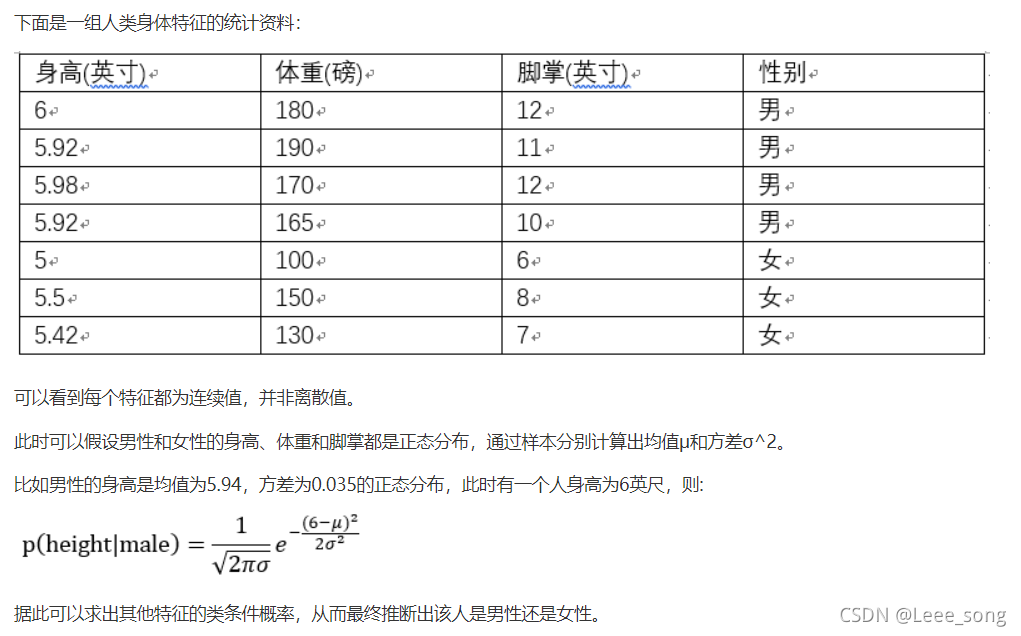
当数据为连续的特征变量时,我们只需要根据训练数据求得该特征期望和方差,然后代入上面的公式,就能够判断测试数据在该特征下属于某一类的概率是多少。
# 导入算法包以及数据集
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report,confusion_matrix
from sklearn.naive_bayes import MultinomialNB,BernoulliNB,GaussianNB #分别是三种模型
# 载入数据
iris = datasets.load_iris()
x_train,x_test,y_train,y_test = train_test_split(iris.data, iris.target)
model = GaussianNB()
model.fit(x_train,y_train)
print(classification_report(mul_nb.predict(x_test),y_test))
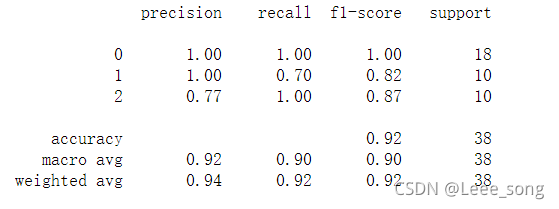
结果:
词袋模型BoW
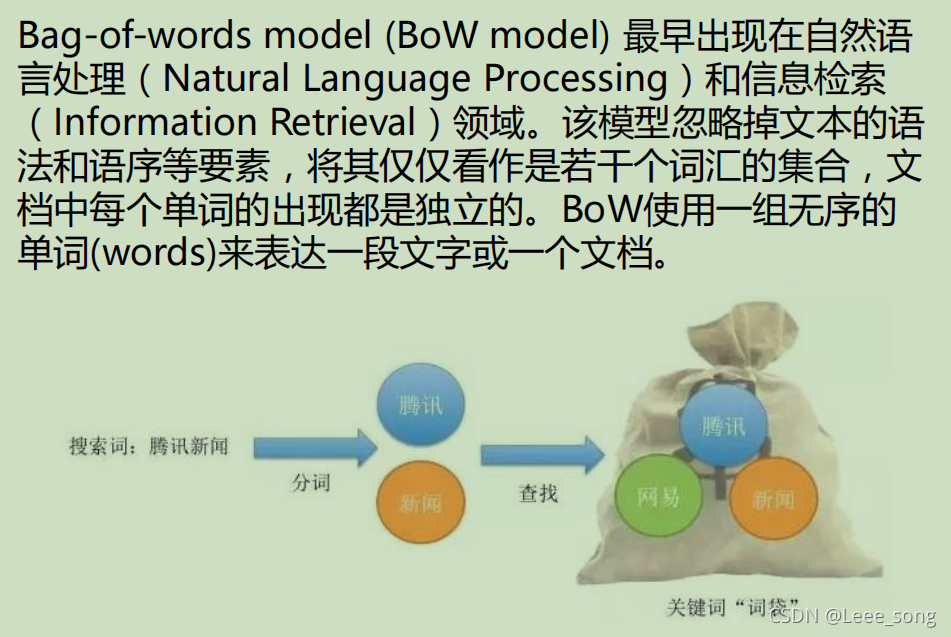

TF-IDF


利用TF-IDF是为朴素贝叶斯筛选重要词汇:

利用TF-IDF实现新闻分类
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn import model_selection
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import TfidfVectorizer
news = fetch_20newsgroups(subset='all')
x_train,x_test,y_train,y_test = train_test_split(news.data,news.target)
mul_nb = MultinomialNB() #朴素贝叶斯多项式模型
vector1 = CountVectorizer() #只考虑词汇在文本中出现的频率,属于词袋模型特征。
vector1_data = vector1.fit_transform(x_train)
scores1 = model_selection.cross_val_score(mul_nb, vector1_data, y_train, cv=3, scoring='accuracy')
vector2 = TfidfVectorizer()#除了考量某词汇在文本出现的频率,还关注包含这个词汇的所有文本的数量,属于Tfidf特征。
vector2_data = vector2.fit_transform(x_train)# 会生成训练集中每个词的TF-IDF的值
scores2 = model_selection.cross_val_score(mul_nb, vector2_data, y_train, cv=3, scoring='accuracy')
def get_stop_words():
result = set()
for line in open('stopwords_en.txt', 'r').readlines():
result.add(line.strip())
return result
# 加载停用词
stop_words = get_stop_words()
vector3 = TfidfVectorizer(stop_words=stop_words)
vector3_data = vector3.fit_transform(x_train)
scores3 = model_selection.cross_val_score(mul_nb, vector3_data, y_train, cv=3, scoring='accuracy')
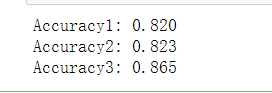
print("Accuracy1: %0.3f" % (scores1.mean()))
print("Accuracy2: %0.3f" % (scores2.mean()))
print("Accuracy3: %0.3f" % (scores3.mean()))


















 1133
1133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









