







Decoupling Representation and Classifier for Long-Tailed Recognition [ICLR2020]
文章目录
two-stage 解耦表征学习+分类
- 解耦表征学习和分类器学习,简单高效,不用设计采样策略和平衡损失,记忆单元等。
- 发现类别不均衡也能学到高质量的表征 类别均衡数据集上学到的表征在调整分类器后也可以很好的分类长尾数据
- 长尾数据学习的主要挑战是头部类主导训练过程
- 一句话:仅仅通过解耦表征学习和分类器利用baseline模型(不额外特殊设计)在长尾视觉识别任务上达到sota,其中表征学习阶段基于长尾数据集,re-sample策略尝试了instance-balanced, class-balanced, square-root以及progressively-balanced方法;分类器学习阶段采用了4种分类器调整方案,分别为cRT(基于class-balanced sampling 在10个epoch左右finetune线性分类器的权重,表征学习层freeze),NCM(算出training set 中每个类的平均特征值存下来,测试时针对每个sample仅需计算其特征值与离线计算好的特征坐最近搜索即可,不用分类头),τ-normalized (对分类头的权重做归一化,归一化的程度可以由超参数t控制,这是基于经验观察:即wj权重的绝对值大小与nj即j类的数量成正相关,做权重归一化可以降低被分类为头部类的可能性,即增大了尾部类在决策空间中的地盘)LWS(将上一方法中的温度系数t作为一个可学习的参数,而不再是超参数,这样就可以直接在训练集中学习,不需验证集去选超参数)。
- 其中places_LT数据集上的模型使用了在imagenet上预训练的模型。
- 问题:
- Instance-balanced的采样结果理论上与随机采样是一致的,但是效果为什么会好,为什么不直接随机采样?
- 猜测:每一个epoch中采用instance-balance,保证每一个epoch中符合全数据集的数据分布;而随机采样(顺序采样)则不能在每一个epoch中保证
- 启示:
- 把表征学习和分类头解耦,看成两个部分,可解释性更好
- re-sample方法
细节
采样策略
- Instance-balanced sampling
- Class-balanced sampling
- Progressively-balanced sampling
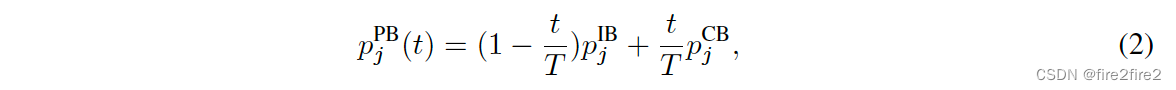
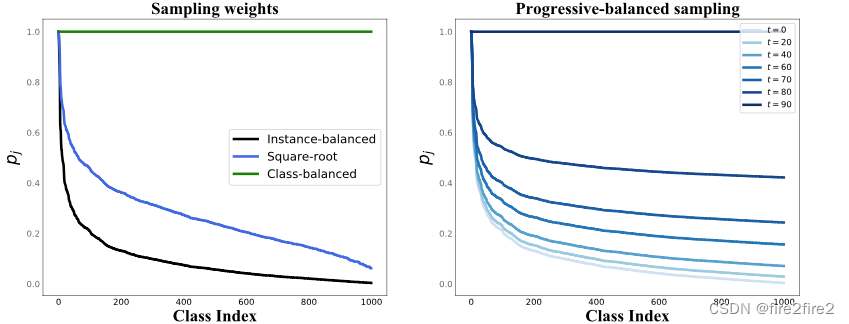
权重调整
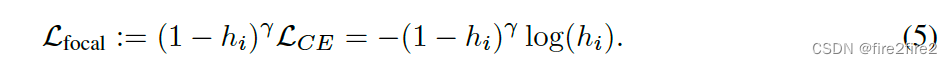
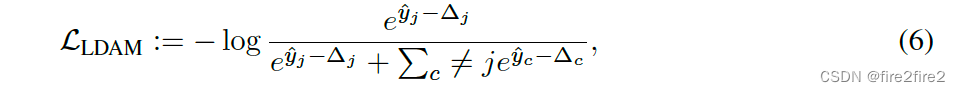
分类器调整
- Classifier Re-training (cRT):re-train the classifier with class-balanced sampling
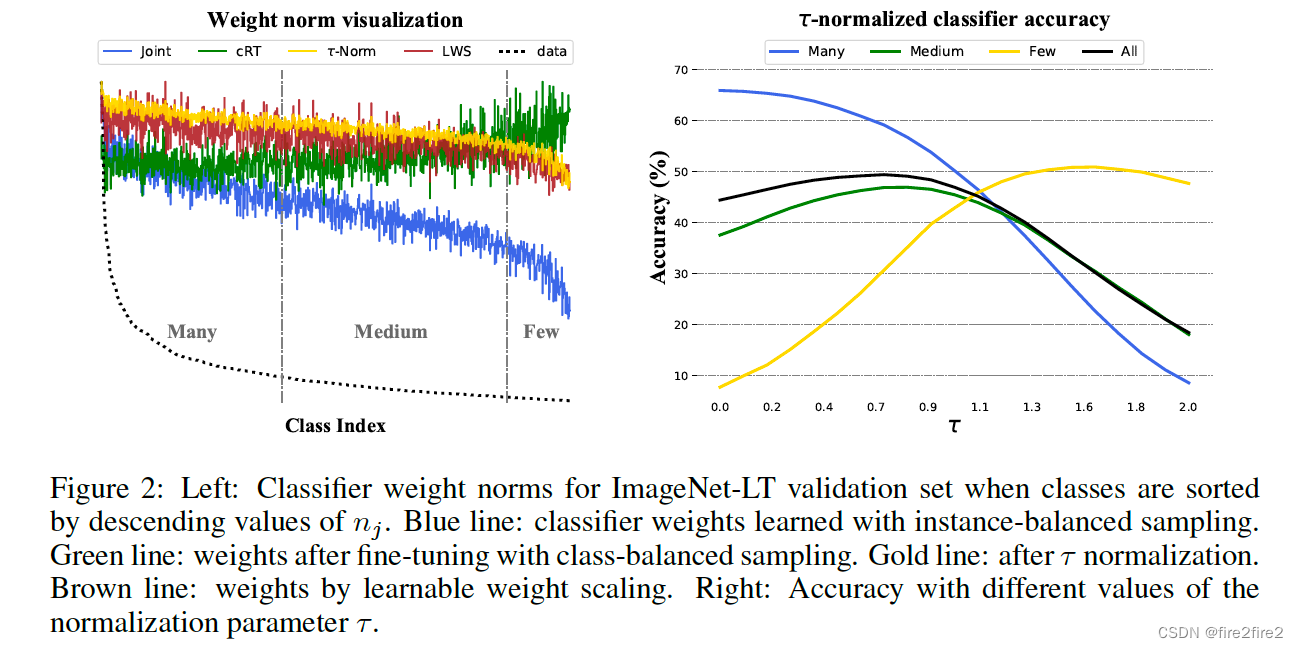
- t-normalized classifier (t -normalized):出发点为分类器对head类的权重值一般较大,降低head类对应的神经元的weight就可以降低对head类预测的偏向。
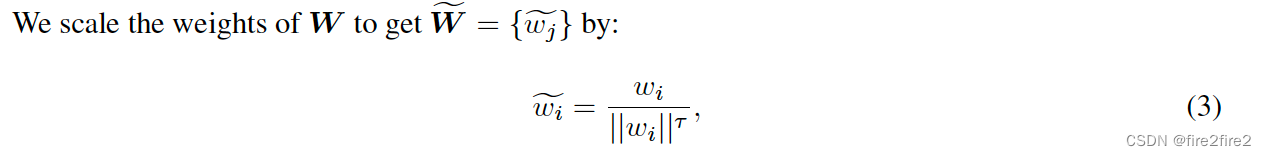
以下实验也证明了这个想法:
- Learnable weight scaling (LWS):上面的norm方法中的t为超参数,这里LWS中作为可学习的参数。
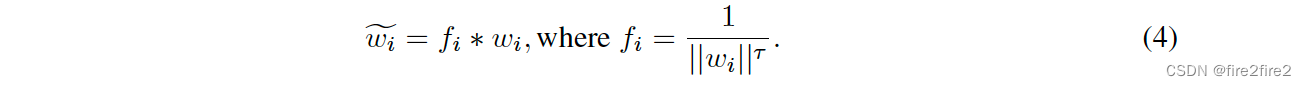
- Nearest Class Mean classifier (NCM):求出每个类的聚类中心,再与聚类中心算相似度进行分类。
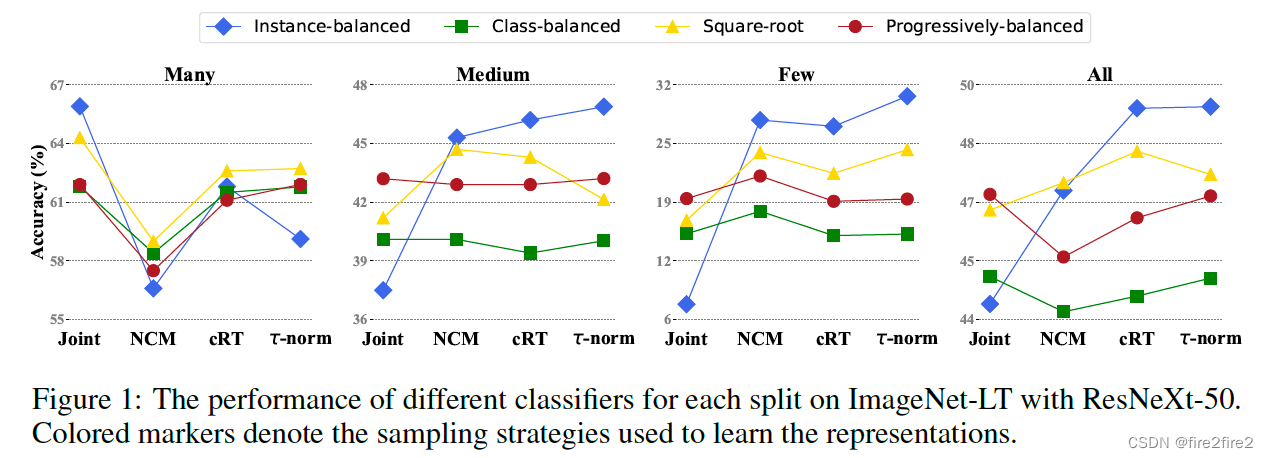
效果
总结
- 思想:解耦后,表征学习学到合理的特征后,只需调整分类器的划分边界bias即可对长尾数据实现较好的分类。
- 采用instance-balanced去学习表征效果最好
- 相较于joint方法,4种分类器解耦方法在many类上的acc均下降
- all,few和medium采用t-norm调整分类器效果最好

















 5920
5920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









