







前言
在BEV感知方案中,将图像特征转为BEV特征,是关键的一步,这过程也称为2D视图变换。
本文介绍Fast-Ray方法,在Fast-BEV中被提出的,它是一种轻量级并且易于部署的视图转换方法,用于快速推理。
通过将多视图2D图像特征沿着相机射线投影到3D体素上,来获得BEV特征。此外,提出了查找表和多视图到单体素操作,优化了在车载平台上的处理过程。
1、背景和现有方案存在问题
1.1 从2D图像特征进行3D感知的挑战
1. 目前先进的BEV方法或者使用基于查询的转换,或者使用隐式/显式基于深度的转换。
2. 但这些方法难以部署在车载芯片上,并且推理速度慢。
3. 基于查询的转换方法通常需要专用芯片来支持。
4. 而基于深度的转换方法往往需要速度不友好的体素池化操作,甚至在多线程CUDA核心上也不是最优解,且在资源有限或不支持CUDA加速推理库的芯片上运行不便。
1.2 基于查询的转换(Query-Based Transformation)——代表论文BEVformer
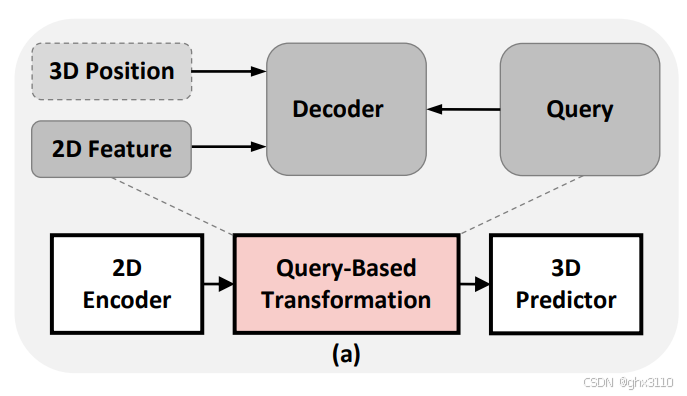
这种方法使用注意力机制来从2D特征获取3D BEV特征。用公式表示:
![]()
1. 其中Fbev(x,y,z) 是BEV空间中的3D特征;
2. q、k、v分别代表查询(query)、键(key)、值(value);
3. q查询和k键是通过特征转换从输入2D特征 F2D(u,v) 中生成,其中 u 和 v 是2D图像的坐标;
4. Pxyz 是3D空间中某点的坐标。基于查询的变换使用注意力机制,来关联2D图像的位置和3D空间的位置;
5. 注意力操作在部署时对某些计算平台并不友好,这限制了这些方法的实际应用。
BEVFormer的原理及细节,之后在总结。
1.3 基于深度估计的转换 (Depth-Based Transformation)——代表论文LSS
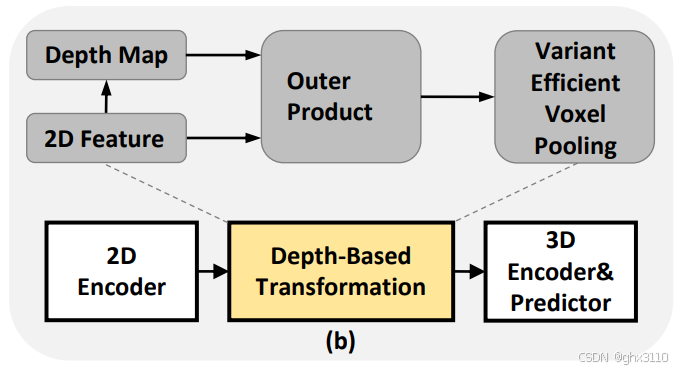
这种方法计算2D特征和预测深度的外积,来获取3D BEV特征,用公式表示:
![]()
1. F2D(u,v) 是从2D图像中提取的特征。D(u,v) 表示从2D特征预测的深度。
2. 运算符 ⊗ 表示外积,它结合了2D图像特征和深度信息。
3. 外积的结果是一个丰富的特征向量,其中包含了原始2D图像特征和深度信息。
4. 然后通过 Pool 函数对这些特征进行体素池化操作,将它们映射到3D空间中的位置 (x,y,z)。
5. 可以通过并行化设计,提高GPU平台上的速度。但计算速度和特征维度较大时的资源需求限制了其在较小或者资源受限的处理器上的应用。
2、Fast-Ray原理与思路
假设在图像到BEV(2D到3D)视图转换期间,相机射线沿深度分布是均匀的,作者提出了一种名为Fast-Ray的转换方法。
Fast-Ray通过利用查找表(Look-Up-Table)和多视图到单体素操作(Multi-View to One-Voxel),优化了计算流程并减少了推理时间,有效加快了BEV转换的速度。
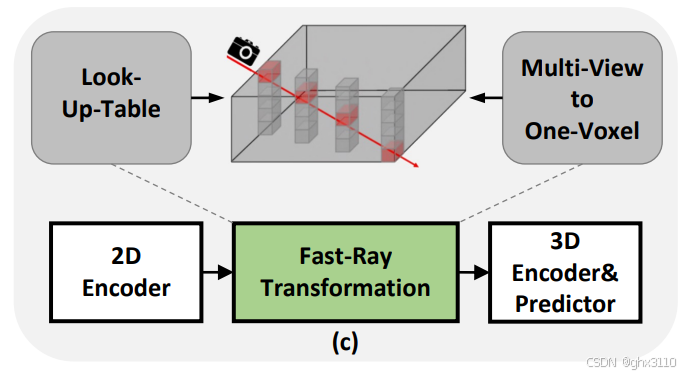
这种方法预先计算图像到三维体素索引(使用查找表)来加速投影时间,并允许所有相机投影到相同的密集体素(多视图到单体素)。
Fast-Ray目的是减少从图像空间到体素空间转换的延迟。
通过预先计算投影索引并将其作为静态查找表存储,这种方法能显著提高转换速度,从而提高整体效率。
此外,通过将所有摄像机视图的特征投影到同一个三维体素特征中(多视图到单体素),避免了昂贵的体素聚合操作。
这种方法与之前依赖CUDA并行计算的方法不同,Fast-Ray转换在CPU上也可以实现高速计算,因此非常适合部署。
如下图所示,展示了BEV视图中离散体素填充的两种不同方法:
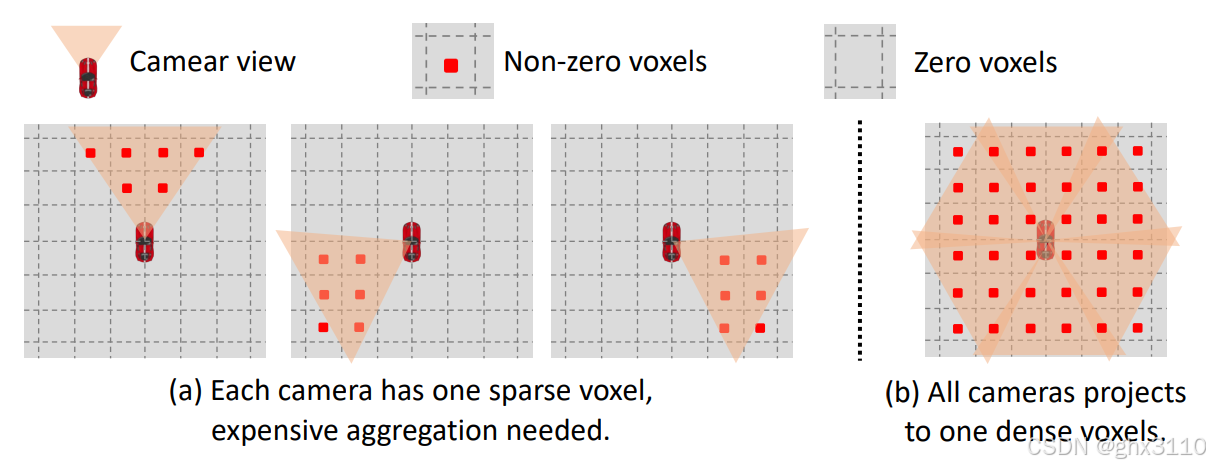
(a) 基础视图变换:
1. 在基本的视图变换中,每个摄像头都有一个稀疏体素,意味着大多数体素位置都是空的(只有约17%的位置是非零的)。
2. 这种情况下,需要一个昂贵的聚合操作来结合来自各个摄像头的稀疏体素。
(b) Fast-BEV提出的方法:所有相机特征的投影都汇集到一个密集的三维体素上
1. Fast-BEV提议让所有摄像头都投影到一个密集的体素上,避免了昂贵的体素聚合过程。
2. 在图b中,可以看到更多的体素被填充(红色代表非零体素),这显示了一种更加高效的数据合并方式,因为不需要在后处理中合并多个稀疏体素集。
3、Fast-Ray关键点
这里有三个关键点:
查找表(Look-Up-Table, LUT):为了快速从2D像素映射到3D体素,使用了一个查找表。这个表预先计算了从2D图像空间到3D体素空间的映射关系,从而在运行时减少计算量,加快处理速度。
多视角到单体素(Multi-View to One-Voxel):将来自多个相机视角的信息整合到单个三维体素特征中。这样做的目的是为了充分利用多个相机提供的信息,同时保持三维体素数据的紧凑性,避免生成过于稀疏的体素空间。
沿相机射线的均匀深度分布:这是一个简化的假设,它假定从相机出发的每一条射线在深度上的分布是均匀的。这使得可以在没有精确深度信息(例如,从激光雷达或深度相机获得的数据)的情况下,对空间进行简化的3D建模。
4、关键点——查找表(Look-Up-Table)
视图变换是从2D图像空间到3D BEV空间转换特征的关键组成部分。
1. 查找表用于映射2D图像空间中的像素到3D体素空间中的位置;
2. 前提假设,认为光线沿着射线的深度分布是均匀的;
3. 利用这一假设,一旦获得摄像头的内部参数和2D到3D的投影参数,就能够简单地计算图像2D特征点和3D体素特征点之间的矩阵映射。
4. 此过程不涉及学习参数,便于计算对应矩阵。
简介:
1. 构建查找表LUT,它与3D体素空间的尺寸相同,并通过相机参数矩阵projection计算出每个体素单元对应的2D像素坐标。
2. 如果得到的2D像素坐标是合法的,那么它们就会被填充到LUT中,建立一个与数据无关的索引映射。
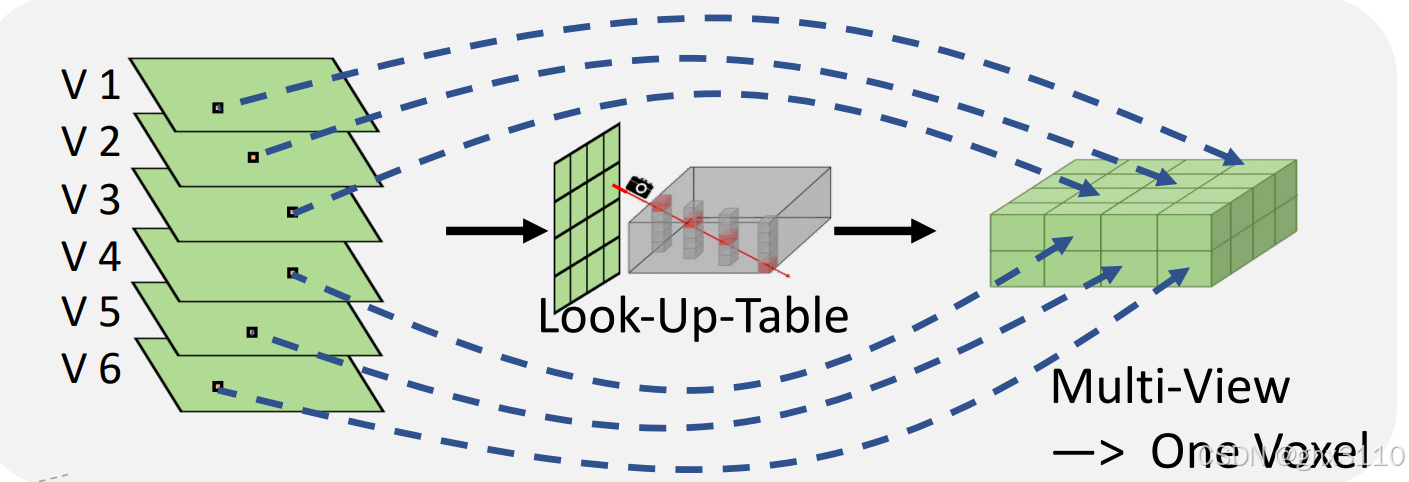
简单来说,3D体素空间,默认设定分辨率为200x200x6,能得到空间中每个三维坐标(x, y, z)
其中,6表示高度方向(从地面向上)被划分为6个体素层。
这个数字代表在从摄像头到对象的垂直范围内,空间被分成了多少层,每层都是体素网格的一个水平切片。
然后基于相机的内外参,将三维坐标(x, y, z)投影到图像中,得到映射关系了,形成映射表。
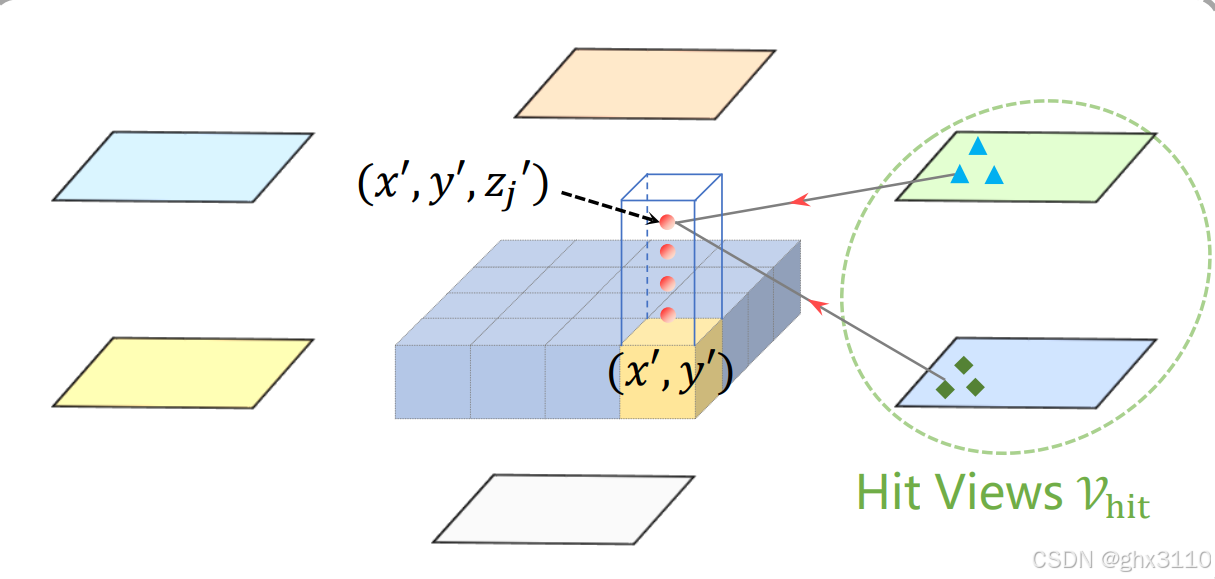
构建查找表的算法流程:
1. 输入:摄像头参数矩阵 projection,包含了进行2D到3D坐标转换所需的摄像头内参和外参。
2. 输出:查找表 LUT,用于在推理过程中快速查找每个体素对应的2D图像中的像素位置。
3. 算法步骤:
1)算法开始遍历体素空间,体素空间的大小由 volume_size 定义。
2)对每个体素的位置 offset,初始化 LUT 为 (-1, -1, -1),意味着初始时没有有效的映射。
3)接着遍历所有图像 img,img_size 定义了有多少图像(即摄像头数量)。
4)对于每个图像,计算3D坐标 offset 对应的2D像素坐标 (x, y, z),通过 projection 矩阵实现。
5)如果计算出的2D坐标 (x, y) 在图像的尺寸范围内(0 ≤ x < w 并且 0 ≤ y < h)且对应的深度 z 大于0,则将这个坐标和图像索引 img 存入 LUT,这样 LUT[offset] 就包含了从3D到2D映射的信息。
6)一旦为某个体素 offset 找到了一个有效映射,就停止对当前体素的进一步搜索。
查找表的特点:
1. 它不依赖于与数据相关的深度信息,因为摄像头位置和它们的内外参参数在感知系统构建时就已确定,并且对于每次输入都是相同的。
2. 因此,无需为每次输入重新计算投影索引,而是可以预先计算固定的投影索引并将其作为静态查找表存储起来。
3. 在推理(inference)过程中,可以通过查询这个查找表来获得投影索引,这是一个低成本的操作。
4. 无论是处理单帧还是多帧图像,都可以轻松预先计算相机的内外参数,并根据这些参数预先对齐到当前帧。
C++示例代码:
// 在CPU上构建查找表(LUT)的函数,将体积数据的体素映射到一系列图像上
void build_LUT_CPU(vector<int32_t> n_voxels, Tensor voxel_size, Tensor origin,
Tensor projection, int32_t n_images, int32_t height, int32_t width, int32_t n_channels,
std::shared_ptr<int32_t>& LUT, std::shared_ptr<int32_t>& valid, std::shared_ptr<float>& volume) {
// 投影矩阵的维度:6 x 3 x 4 (N, 3, 4)
// 从n_voxels向量中提取X、Y、Z轴上的体素维度。
int n_x_voxels = n_voxels[0];
int n_y_voxels = n_voxels[1];
int n_z_voxels = n_voxels[2];
// 获取体素大小的指针,并提取具体尺寸
float* voxel_sizep = (float*)voxel_size.get_data();
float size_x = voxel_sizep[0];
float size_y = voxel_sizep[1];
float size_z = voxel_sizep[2];
// 获取原点位置的指针,并提取具体坐标
float* originp = (float*)origin.get_data();
float origin_x = originp[0];
float origin_y = originp[1];
float origin_z = originp[2];
// 计算总体素数
int nrof_voxels = n_x_voxels * n_y_voxels * n_z_voxels;
// 从智能指针获取查找表(LUT)和有效标记数组的原始指针
int32_t* LUTp = LUT.get();
int32_t* validp = valid.get();
// 辅助向量,用于计算和存储转换结果
std::vector<float> ar(3);
std::vector<float> pt(3);
size_t offset = 0; // LUT中的偏移量
float count = 0.0; // 用于计数
// 遍历每个体素
for (int zi = 0; zi < n_z_voxels; ++zi) {
for (int yi = 0; yi < n_y_voxels; ++yi) {
for (int xi = 0; xi < n_x_voxels; ++xi) {
auto current_lut = &LUTp[offset * 2];
*current_lut = -1; // 初始设置为-1,表示无效映射
*(current_lut + 1) = 0; // 第二个值用于存储映射信息,初始为0
// 遍历每个图像,尝试找到当前体素在这些图像中的映射
for (int img = 0; img < n_images; img++) {
// 计算体素在世界坐标系中的位置
pt[0] = (xi - n_x_voxels / 2.0f) * size_x + origin_x;
pt[1] = (yi - n_y_voxels / 2.0f) * size_y + origin_y;
pt[2] = (zi - n_z_voxels / 2.0f) * size_z + origin_z;
// 使用投影矩阵将体素坐标转换为图像坐标
for (int i = 0; i < 3; ++i) {
ar[i] = ((float*)projection.get_data())[((img * 3) + i) * 4 + 3];
for (int j = 0; j < 3; ++j) {
ar[i] += ((float*)projection.get_data())[(img * 3 + i) * 4 + j] * pt[j];
}
}
// 计算投影后的图像坐标
int x = round(ar[0] / ar[2]);
int y = round(ar[1] / ar[2]);
float z = ar[2];
// 检查图像坐标是否有效
if ((x >= 0) && (y >= 0) && (x < width) && (y < height) && (z > 0)) {
*current_lut = img; // 记录图像索引
*(current_lut + 1) = y * width + x; // 记录图像内的具体位置
count+=1;
validp[offset] = 1; // 标记为有效
break; // 找到有效映射后停止搜索
}
}
++offset; // 处理下一个体素
}
}
}
}5、关键点——多视角到单体素(Multi-View to One-Voxel)
基于预先计算的查找表LUT,将多视图到单个三维体素中,进行视图转换。
算法流程:
输入:包括来自多个相机的2D图像特征(features)和预先计算的查找表(LUT)。
输出:算法输出是一个3D体素特征体积(volume),这是3D BEV空间的一个表示。
处理流程:
1. 遍历3D体素特征体积(volume)中的每个体素(由offset索引)。
2. 使用查找表(LUT)找到每个体素在2D图像中对应的像素坐标(img, x, y)。
3. 如果这个坐标是有效的(即该像素在图像的边界内),那么从2D图像特征(features[img][x][y])中提取相应的特征,并将它填充到3D体素特征体积中相应的offset位置。
4. 这个过程对每个体素重复执行,直到整个3D体素特征体积被填充。
C++示例代码:
// 根据查找表(LUT)将从2D图像中提取的特征回投影到3D体积中
void backproject_LUT_CPU(Tensor features, std::shared_ptr<int32_t> LUT, std::shared_ptr<float> volume,
vector<int32_t> n_voxels) {
// 从特征张量获取图像的数量、高度、宽度和通道数
int32_t n_images = features.get_shape().d[0];
int32_t height = features.get_shape().d[1];
int32_t width = features.get_shape().d[2];
int32_t n_channels = features.get_shape().d[3];
// 从提供的向量中获取3D体积的维度(X、Y、Z轴上的体素数)
int n_x_voxels = n_voxels[0];
int n_y_voxels = n_voxels[1];
int n_z_voxels = n_voxels[2];
// 获取指向特征数据和体积数据的原始指针
float* featuresp = (float*)features.get_data();
float* volumep = volume.get();
// 计算3D体积中总的数据点数量(注意体积*2是因为LUT的每个条目都是成对出现的)
size_t volume_count = n_x_voxels * n_y_voxels * n_z_voxels * 2;
// 计算每次迭代中需要复制的数据字节数
size_t copy_size_per_iter = n_channels * sizeof(float);
// 获取LUT的原始指针
int32_t* LUTp = LUT.get();
// 遍历LUT中的每个条目,以将特征从2D图像回投影到3D体积中
for (size_t offset = 0; offset < volume_count; offset=offset+2) {
// 从LUT中获取当前体素对应的图像索引和目标像素位置
int img = LUTp[offset];
int target = LUTp[offset+1];
// 检查图像索引是否有效
if (img >= 0) {
// 计算源数据指针:指向特征张量中对应图像的对应像素的特征向量
float* src = featuresp + img * height * width * n_channels + target * n_channels;
// 计算目标数据指针:指向3D体积中对应体素的特征向量
float* dst = volumep + offset/2 * n_channels;
// 将特征数据从源复制到目标
memcpy(dst, src, copy_size_per_iter);
}
}
}
















 424
424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









