







1. 引入
传统的神经网络就像这种全连接网络,每个输入都和中间的隐藏层进行连接,然后输出。但这种网络,完全没有时序特点,无法深度挖掘具有时序特点的数据的特征。例如:x1 = ‘我的手机坏了’,x2 = ‘想买一个256g的苹果’。那么在全连接网络中,就很难理解‘256g的苹果’是真实的苹果还是手机了。
于是,就又了RNN(循环精神网络)。
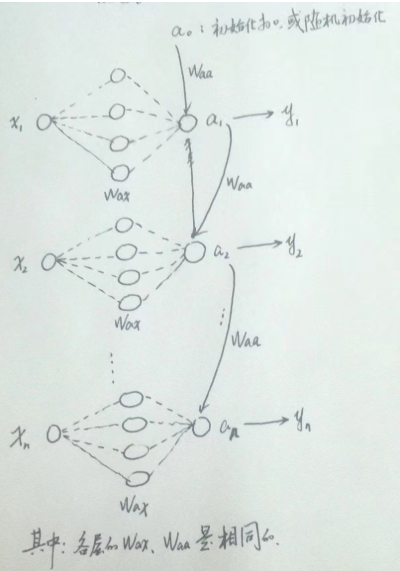
2. RNN简介
RNN网络会在下一个x中输入前一个网络的输出,不废话,直接上图,以下是我自己理解的图:
这个是很多网上经典的图:
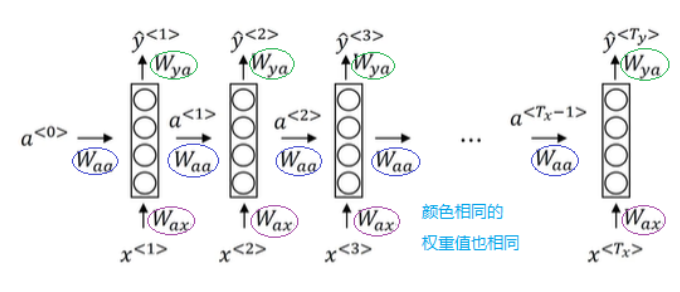
这张图是转载的一篇博文的,关于RNN这篇博文也写得非常好,关于RNN的讲解
计算公式如下:
a
t
=
f
(
W
a
a
a
t
−
1
+
W
a
x
x
t
+
b
)
a_t = f(W_{aa}a_{t-1} + W_{ax}x_t + b)
at=f(Waaat−1+Waxxt+b)
其中,
(1)
a
t
a_t
at表示当前时间的输出,
a
t
−
1
a_{t-1}
at−1表示前一段时间的输出,
x
t
x_t
xt表示当前时间的输入;
(2) W a a W_{aa} Waa表示对于 a t − 1 a_{t-1} at−1的权重(需要训练调优), W a x W_{ax} Wax表示对于 x t x_{t} xt的权重(需要训练调优), b b b表示偏执,也需要训练调优。
3. 对于输入数据的解释
之前对于RNN的输入
x
x
x到底表示什么意思,我一直不太理解,知道有一天看到一个OCR相关的文章才豁然开朗。以下根据自己的理解举一个例子,如有不对,还请各位评论区指出。例子如下:
例如,
Step1: 使用onehot编码(当然也可以使用embedding编码),我的中文字典是:
d
i
c
=
[
′
我
′
,
′
的
′
,
′
手
′
,
′
机
′
,
′
坏
′
,
′
了
′
,
′
想
′
,
′
换
′
,
′
个
′
,
′
苹
′
,
′
果
′
]
dic = ['我','的','手','机','坏','了', '想','换','个','苹','果']
dic=[′我′,′的′,′手′,′机′,′坏′,′了′,′想′,′换′,′个′,′苹′,′果′]
Step2: 而我需要使用RNN进行理解的句子是(理解最后这个”苹果“是指手机,还是水果):
我的手机坏了,想换个苹果。
我的手机坏了,想换个苹果。
我的手机坏了,想换个苹果。
Step3: 那么,每个字对应的one-hot编码为:
我:
10000000000
我: 10000000000
我:10000000000
的:
01000000000
的:01000000000
的:01000000000
.
.
.
...
...
果:
00000000001
果:00000000001
果:00000000001
Step4: 现在,我们需要对上面的句子进行”词划分“,划分规则应该是有一定的方法,我这边就按照语句定吧,如:
我的 手机 坏了, 想 换个 苹果
Step5: 那么对应RNN图中的x1, x2…xn, 应该为:
x
1
=
′
我
的
′
=
10000000000
01000000000
x1 = '我的' = 10000000000 \,\, 01000000000
x1=′我的′=1000000000001000000000
x
2
=
′
手
机
′
=
00100000000
00010000000
x2 = '手机' = 00100000000 \,\, 00010000000
x2=′手机′=0010000000000010000000
.
.
.
...
...
x
4
=
′
想
′
=
00000010000
00000000000
x4 = '想' = 00000010000 \,\, 00000000000
x4=′想′=0000001000000000000000
.
.
.
...
...
注意:每一个xi都要一样长,即按照最长的词进行编码,如果不够,用0凑。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









