




1.下载jdk 1.8
2.下载scala ,我的版本是2.11.12,因为spark会显示支持的scala版本
3.下载hadoop,我用的是2.8.5版本,一定要注意bin文件中下载好winutils.exe
4.下载spark 2.3.0,我用2.4.0怎么都不成功,也不知道为啥
好了,准备工作完成了,主要是在环境变量的配置方面。右键‘我的电脑’——>属性——>高级系统设置,打开环境变量。
在系统变量中,加入
JAVA_HOME:(D:\java),
CLASSPATH:%JAVA_HOME%\lib;%JAVA_HOME%\lib\tools.jar
HADOOP_HOME?:\hadoop\hadoop-2.8.5
SPARK_HOME:C:\spark\spark-2.3.0-bin-hadoop2.7
PYTHONPATH:%SPARK_HOME%\python\lib\py4j;%SPARK_HOME%\python\lib\pyspark;C:\Anaconda3;
接着,在PATH里面添加
%JAVA_HOME%\bin;D:\hadoop\hadoop-2.8.5;D:\scala\bin;%SPARK_HOME%\bin;%SPARK_HOME%\sbin
添加完成后,打开pycharm
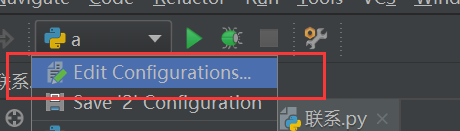
点击Edit Configurations,在Environment variables里面添加
PYTHONPATH:C:\spark\spark-2.3.0-bin-hadoop2.7\python,即spark安装目录下的python文件夹
SPARK_HOME:C:\spark\spark-2.3.0-bin-hadoop2.7
至此,在pycharm中就可以运行pyspark了


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









