







 EM算法是一种用于估计含有隐变量的概率模型参数的迭代方法。当面对既有观测变量又有隐变量的概率模型时,由于无法直接求解对数似然函数的最大值,EM算法通过期望(E)和最大化(M)两个步骤逐步逼近最大似然估计。在E步中,计算隐变量的期望值;在M步中,更新参数以最大化期望值函数。通过不断迭代,直到对数似然函数的增大幅度小于某个阈值,从而得到模型参数的估计。
EM算法是一种用于估计含有隐变量的概率模型参数的迭代方法。当面对既有观测变量又有隐变量的概率模型时,由于无法直接求解对数似然函数的最大值,EM算法通过期望(E)和最大化(M)两个步骤逐步逼近最大似然估计。在E步中,计算隐变量的期望值;在M步中,更新参数以最大化期望值函数。通过不断迭代,直到对数似然函数的增大幅度小于某个阈值,从而得到模型参数的估计。
文章目录
EM算法——估计含有隐变量的概率模型的参数
含有隐变量的概率模型
通过极大化对数似然函数求解概率模型参数
设有概率模型,X表示样本变量, Θ \Theta Θ表示其参数。
我们知道这个概率模型的形式,又有很多的样本数据(X取值已知),但是却不知道概率模型的具体参数值( Θ \Theta Θ取值未知),用什么办法求出 Θ \Theta Θ呢?
早在朴素贝叶斯模型的笔记里就知道:当一个概率模型参数未知,但有一系列样本数据时,可以采用极大似然估计法来估计它的参数。
该概率模型的学习目标是极大化其对数似然函数:

此时,根据X直接极大化 L L ( Θ ∣ X ) LL(\Theta|X) LL(Θ∣X)来求 Θ \Theta Θ的最优取值即可。此处的X必须是完全数据,也就是样本数据所有变量的值都是可见且完整的情况下,才可以通过直接极大化对数似然函数来求解参数的值。
含有隐变量的对数似然函数
有的时候,概率模型既含有可以看得见取值的观测变量,又含有直接看不到的隐变量(Hidden Variable,又称潜在变量 Latent Variable)。
设有概率模型,X表示其观测变量集合,Z表示其隐变量集合, Θ \Theta Θ表示该模型参数。
注意:X和Z和在一起被称为完全数据(Complete-data),仅有X成为不完全数据(Incomplete-data)。
要对 Θ \Theta Θ进行极大似然估计,就是要极大化 Θ \Theta Θ相对于完全数据的对数似然函数——隐变量Z存在时的对数似然函数为:

我们无法通过观测获得隐变量的取值,样本数据不完全,这种情况下,直接用极大似然估计,就不行了,需要用EM算法。
EM算法基本思想
EM(期望最大化,Expectation-Maximization)算法,是一种用于对含有隐变量的概率模型的参数,进行极大似然估计的迭代算法。
近似极大化
EM算法的基本思想是:近似极大化——通过迭代来逐步近似极大化。我们有一个目标函数: a r g m a x f ( θ ) arg maxf(\theta) argmaxf(θ).
然而,由于种种原因,我们对于当前这个要求极大值的函数本身的形态并不清楚,因此无法通过诸如求导函数并令其为零(梯度下降)等方法来直接探索目标函数极大值,也就上不能直接优化 f ( θ ) f(\theta) f(θ)
但是我们可以采用一个近似的方法。
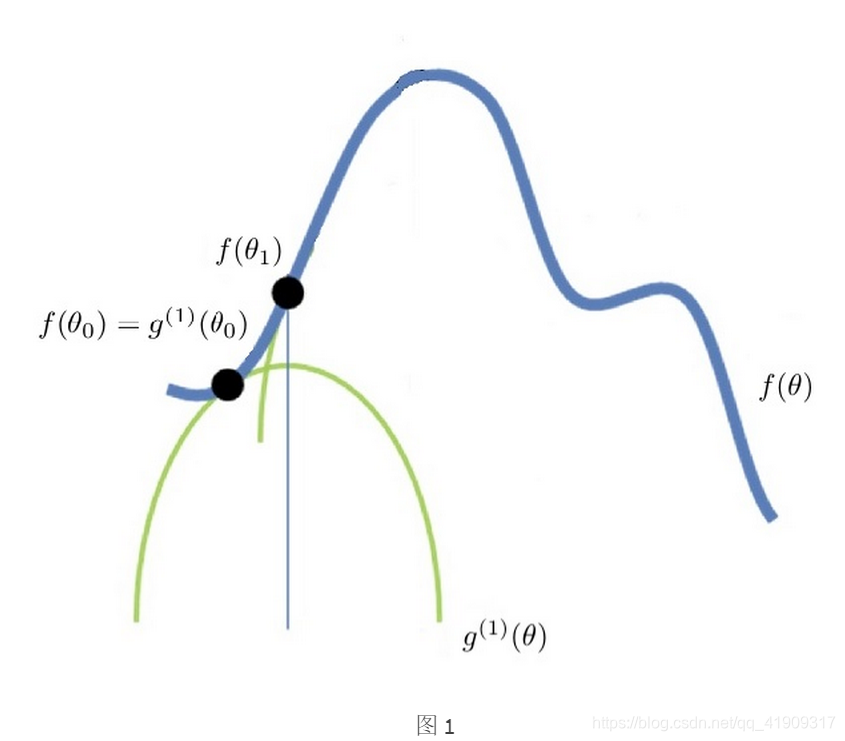
首先构造一个我们确定可以极大化的函数 g ( 1 ) ( θ ) g^{(1)}(\theta) g(1)(θ),并确保:
- f ( θ ) ≥ g ( 1 ) ( θ ) f(\theta)\ge g^{(1)}(\theta) f(θ)≥g(1)(θ);
- 存在一个点 θ 0 \theta_0 θ0, f ( θ 0 ) f(\theta_0) f(θ0)和 g ( 1 ) ( θ 0 ) g^{(1)}(\theta_0) g(1)(θ0)在 θ 0 \theta_0 θ0点相交,即: f ( θ 0 ) ≥ g ( 1 ) ( θ 0 ) f(\theta_0)\ge g^{(1)}(\theta_0) f(θ0)≥g(1)(θ0);
- θ 0 \theta_0 θ0不是 g ( 1 ) ( θ ) g^{(1)}(\theta) g(1)(θ)的极大值点。
在这种情况下,我们极大化 g ( 1 ) ( θ ) g^{(1)}(\theta) g(1)(θ),得到 g ( 1 ) ( θ ) g^{(1)}(\theta) g(1)(θ)的极大值点 θ 1 \theta_1 θ1,即: m a x g ( 1 ) ( θ ) = g ( 1 ) ( θ 1 ) maxg^{(1)}(\theta)=g^{(1)}(\theta_1) maxg(1)(θ)=g(1)(θ1)
由1、2、3可知:
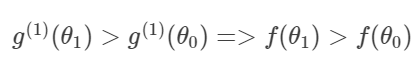
可见,极大化 g ( 1 ) ( θ ) g^{(1)}(\theta) g(1)(θ)的过程,就相当于沿着 θ \theta θ方向,向着 f ( θ ) f(\theta) f(θ)的极大值前进了一步,见图:
然后,再构造一个函数 g ( 2 ) ( θ ) g^{(2)}(\theta) g(2)(θ)&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









