







 本文详细解析策略梯度中的Baseline概念,介绍了其在降低方差和加速收敛中的作用,展示了添加Baseline后的策略梯度和蒙特卡洛近似,并讨论了常见Baseline的选择及其影响。关键在于理解为何引入基线,以及如何选择合适的b以提高训练效率。
本文详细解析策略梯度中的Baseline概念,介绍了其在降低方差和加速收敛中的作用,展示了添加Baseline后的策略梯度和蒙特卡洛近似,并讨论了常见Baseline的选择及其影响。关键在于理解为何引入基线,以及如何选择合适的b以提高训练效率。
策略梯度的推导:

策略梯度中的Baseline:
策略梯度中常用Baseline方法来降低方差,可以使得收敛更快。Baseline可以是一个函数b,该函数是什么都可以,但就是不能依赖于动作A。
下面是Baseline的一个重要等式推导,灰色部分是用链式法则展开,
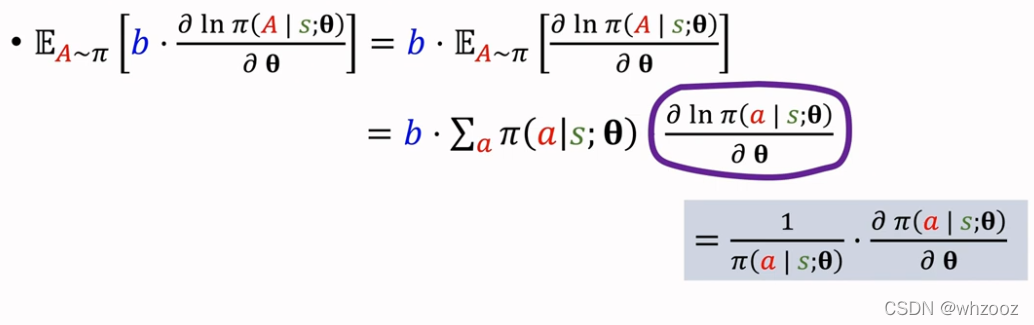
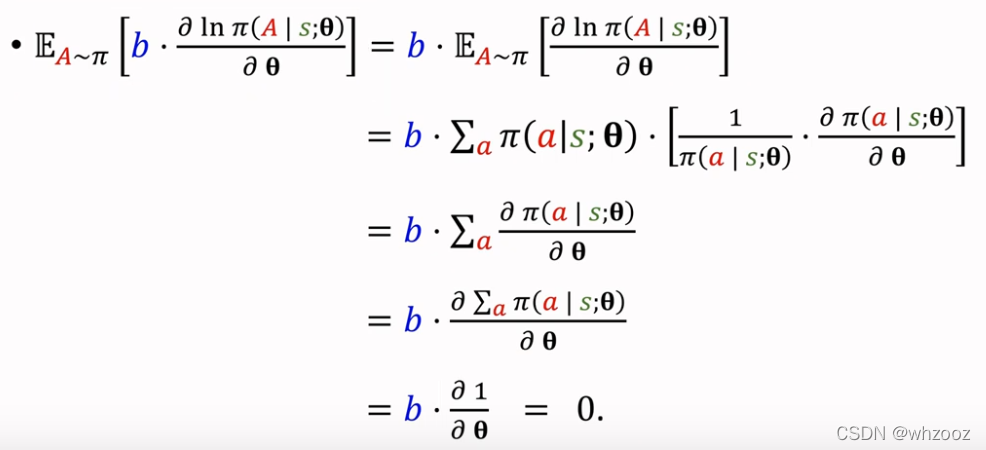
添加Baseline后的策略梯度:
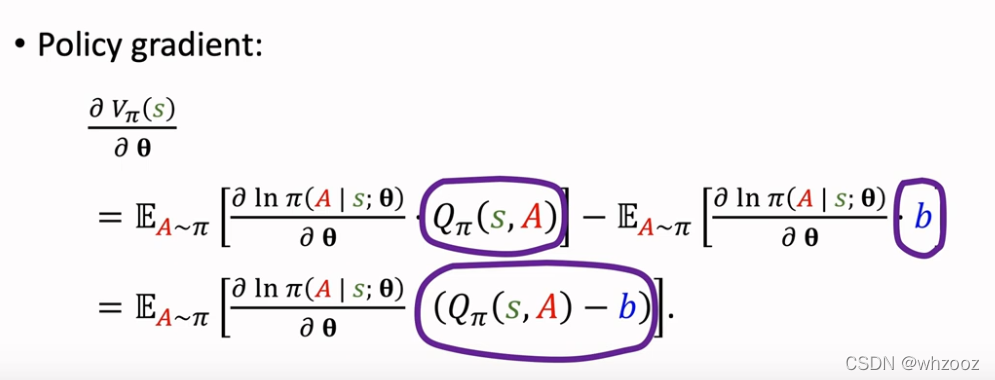
引入b既然等于0为什么要引入呢?原因是神经网络中的策略梯度并不是按照这个公式计算,而是这个公式的蒙特卡洛近似,如果选取的b合适,那么就会使得蒙特卡洛的方差变小,使得收敛的更快。
策略梯度中常用Baseline方法来降低方差,可以使得收敛更快。Baseline可以是一个函数b,该函数是什么都可以,但就是不能依赖于动作A。
下面是Baseline的一个重要等式推导,灰色部分是用链式法则展开,
引入b既然等于0为什么要引入呢?原因是神经网络中的策略梯度并不是按照这个公式计算,而是这个公式的蒙特卡洛近似,如果选取的b合适,那么就会使得蒙特卡洛的方差变小,使得收敛的更快。
 2284
2284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























