







1. Java集合的定义
背景:由于Java数组存储数据时存在一些缺点,1、数组创建后长度不可变;2、数组中存储的元素类型必须保持一致;当需要存储的数据不满足这两种情况时,就不能使用数组存储,因此出现一种新的存储方式(集合)来解决这两个问题。【注:数组创建的两种方式,int[] a = new int[]{1,2,3,4}; (2)int[] aa = new int[6]; //创建数组存储int基本数据类型】
含义:在Java编程语言下,对于数据存储方式的一种统称。它的优势表现在:1、集合可以动态改变容量的大小;2、集合存放的类型可以不止一种(在不使用泛型时,添加的类型是Object)。
注意:数组和集合都可以存储引用数据类型和基本数据类型,集合在存储基本数据类型时会自动装箱变成对象(JDK1.5新特征)。这里说明一下,Java所存在的缺点是为了保证可以高效快速的访问所存储的元素。
2. Java集合的组成
Java集合框架主要分为两种:Collection接口和Map接口,如下图,接下来分别介绍它们的特点,以及各自的组成部分。
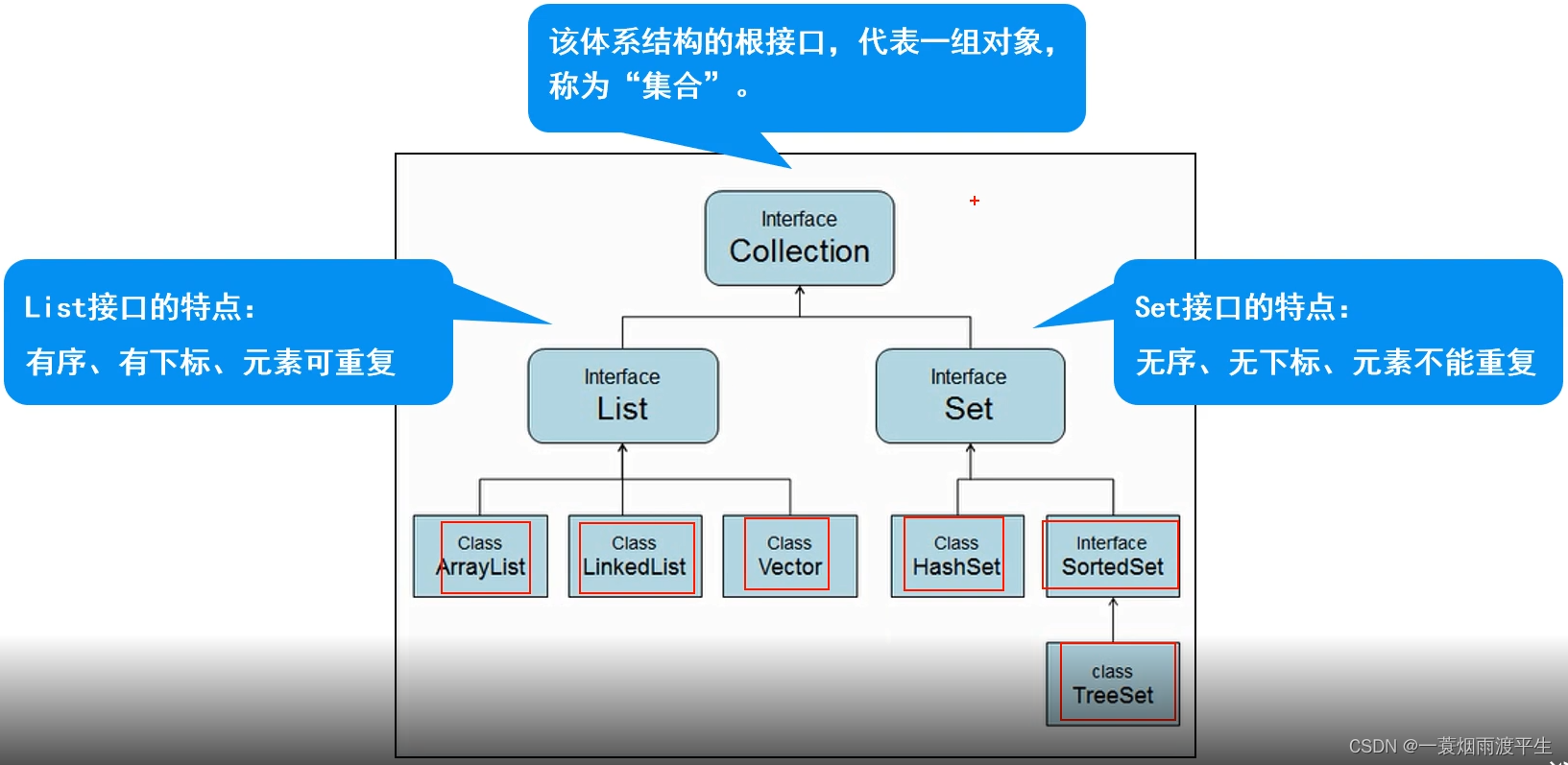
2.1 Collection接口
Collection接口主要包括List接口和Set接口。
- List接口下的实现类(ArrayList、LinkedList、Vector(可不掌握))存储有序、可重复性的数据,
- Set接口下的实现类(HashSet、TreeSet)存储无序、不可重性的数据。
【无序性:存储的数据在底层数组中并非按照数据索引的顺序添加,而是根据数据的哈希值来确定。不可重复性:保证添加的元素按照equals判断时不能返回true,即相同的元素只能添加一个】
2.1.1 List接口相关内容
List接口实现类有ArrayLIst和LinkedList,主要存储有序、可重复性的数据。
那么对于有序、可重复性的数据存储时,什么时候使用ArrayList/LinkedList?
- ArrayList:底层由数组(Array)支持,查找快,添加、删除慢;
- LinkedList:底层由链表(Linked)支持,查找慢,添加、删除快;
ArrayList是基于数组实现的,那么它怎么动态改变容量大小呢?
这里需要提到ArrayList的扩容机制。在创建ArrayList时,初始数组容量为0,当添加第一个元素时,才真正分配容量为10的数组给它,后面每一次添加都要判断容量是否可以存储,当容量不足以添加时,会以原容量1.5倍进行扩容。
ArrayList部分代码如下:
private static final int DEFAULT_CAPACITY = 10; //定义默认初始容量为10
private static final Object[] EMPTY_ELEMENTDATA = {}; //定义一个空数组,
//当没有元素时,赋予空数组,当添加第一个元素时,扩充一个容量为10的数组
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
//扩容机制
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length; //初始elementData.length等于10
int newCapacity = oldCapacity + (oldCapacity >> 1); //oldCapacity >> 1 表示缩小一倍
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity); //将之前的数组赋值到新数组上
}
【注:在IDEA中,Ctrl+鼠标左击可以看相关接口的源码,Ctrl+Alt+←是返回到上次点击的接口】
LinkedList部分代码如下:
/**
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first; //头结点,指向链表第一个节点
/**
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last; //尾结点,指向链表最后一个节点
//节点定义
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element; //当前节点存储的元素
this.next = next; //后继节点(当前节点的后一个节点)
this.prev = prev; //前驱节点(当前节点的前一个节点)
}
}
2.1.2 Set接口相关内容
Set接口实现类有HashSet和TreeSet,主要存储无序性、不可重复性的数据。
HashSet:底层由哈希表(Hash:数组+链表+红黑树:Java1.9)支持,实现基于HashMap类,具体过程在HashMap中介绍。
【注:红黑树的限制条件低于平衡二叉树,它要求:1、根节点是黑色;2、每个叶子节点(NULL)是黑色;3、每个红色节点的两个子节点一定都是黑色;4、任意一节点到每个叶子节点的路径都包含数量相同的黑节点。平衡二叉树条件是一棵树的两个子树的高度差的绝对值不超过1,并且左右两个子树都是平衡二叉树,而红黑树是根到叶子的最长路径不多于最短路径的两倍长。】
public HashSet() {
map = new HashMap<>();
}
简单介绍HashSet在添加元素的过程中如何保证无序性和不可重复性,以存储元素a为例:
- 无序性:当存储元素a时,它所存放的位置是根据该元素所在类的HashCode()方法,计算元素a的哈希值,然后根据哈希值映射到对应位置下标。
- 不可重复性:在存储元素a时,会先判断它所存储的位置是否为空,如果是空的,直接保存;如果不为空,再计算该元素所在类的equals方法,如果equals为true,则认为这两个数是重复的,拒绝元素a存储,如果equals为false,则形成链表,存储该元素a。
可以理解成HashCode是用来确定元素存放数组位置的下标,而equals是用来确定在同一位置是否存在相同的数。
举个例子,如下,p1和p2都叫a,通过HashCode计算后所存出的数组位置下标相同,此时要去计算它们的equals【注意:此时的equals是需要我们重写的,然后我们定义姓名和年龄都相同时,equals才返回true】,由于它们的年龄不同,一个是11,一个是22,因此这两个数都是可以存储的。
import java.util.HashSet;
import java.util.Objects;
class Person1{
String name;
int age;
public Person1(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Person1)) return false;
Person1 person1 = (Person1) o;
return age == person1.age && Objects.equals(name, person1.name);
}
}
public class HashSetTest {
public static void main(String[] args) {
Person1 p1 = new Person1("a",11);
Person1 p2 = new Person1("a",22);
Person1 p3 = new Person1("1",11);
HashSet<Person1> hashSet = new HashSet<Person1>();
hashSet.add(p1);
hashSet.add(p2);
hashSet.add(p3);
System.out.println(p1.equals(p2));
System.out.println(p1.equals(p3));
}
}
TreeSet:底层由红黑树(Tree)支持,实现基于TreeMap类,具体过程在TreeMap中介绍。
public TreeSet() {
this(new TreeMap<E,Object>());
}
TreeSet添加元素的不可重复性在于它的排序方式,排序方式分为两种:自然排序和定制排序
1、自然排序方式需要实现Comparable接口,依据compareTo比较添加元素是否相同(返回0是相同元素),不再依据equals判断。
import java.util.Iterator;
import java.util.TreeSet;
class Person1 implements Comparable<Person1> {
String name;
int age;
public Person1(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Person1)) return false;
Person1 person1 = (Person1) o;
return age == person1.age && Objects.equals(name, person1.name);
}
@Override
public int compareTo(Person1 o) {
//比较姓名相同时它们就相等
int a = this.name.compareTo(o.name);
return a;
}
@Override
public String toString() {
return "Person1{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
public class TreeSetTest {
public static void main(String[] args) {
TreeSet<Person1> treeSet = new TreeSet<>();
Person1 p1 = new Person1("abc",11);
Person1 p2 = new Person1("abc",22);
Person1 p3 = new Person1("cc",22);
treeSet.add(p1);
treeSet.add(p2);
treeSet.add(p3);
//遍历的两种方式
System.out.println("方式一");
for(Object obj: treeSet){
System.out.println(obj);
}
System.out.println("方式二");
Iterator iterator = treeSet.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}
}
/*
输出结果:
方式一
Person1{name='abc', age=11}
Person1{name='cc', age=22}
方式二
Person1{name='abc', age=11}
Person1{name='cc', age=22}
*/
2、定制排序方式在创建TreeSet容器时就重写Comparator中compare方法,用来比较添加的元素是否相同。
import java.util.Comparator;
import java.util.Iterator;
import java.util.TreeSet;
public class TreeSetTest {
public static void main(String[] args) {
TreeSet<Person1> treeSet = new TreeSet<>(new Comparator<Person1>() {
@Override //当年龄相同时,这两个对象相同
public int compare(Person1 o1, Person1 o2) {
return o1.age-o2.age;
}
});
// TreeSet<Person1> treeSet = new TreeSet<>();
Person1 p1 = new Person1("abc",11);
Person1 p2 = new Person1("abc",22);
Person1 p3 = new Person1("cc",22);
treeSet.add(p1);
treeSet.add(p2);
treeSet.add(p3);
for(Object obj: treeSet){
System.out.println(obj);
}
}
}
关于Collection接口的总结,Collection接口主要分为List接口和Set接口:
1、List接口主要由ArrayList类和LinkedList类实现,用来存储有序、可重复性的数据。
1)ArrayList查找快,添加、删除慢;初始为0,添加是容量为10,扩容是原数组的1.5倍。
2)LinkedList查找慢,添加、删除快; 2、Set接口主要有HashSet类和TreeSet类实现,用来存储无序、不可重复性数据。
1)HashSet基于HashMap实现,TreeSet基于TreeMap实现,它们都有各自的方法来保证不可重复性。
2)HashSet不可重复性先通过HashCode来确定元素存放数组位置的下标,再通过equals来确定在同一位置是否存在相同的数,只有当HashCode和equals都相同时,这个元素就不能被插入。一般情况equals都会被重写。
3)TreeSet不可重复性有两种方式体现,第一种是自然排序方式,即该类(插入元素的当前类)实现Comparable接口,重写compareTo方法,当返回0时表示这两个数相同,不可插入;第二种是定制排序方式,即在创建TreeSet类时,new一个Comparator方法,重写其中的compare方法,当返回0时表示这两个数相同,不可插入。
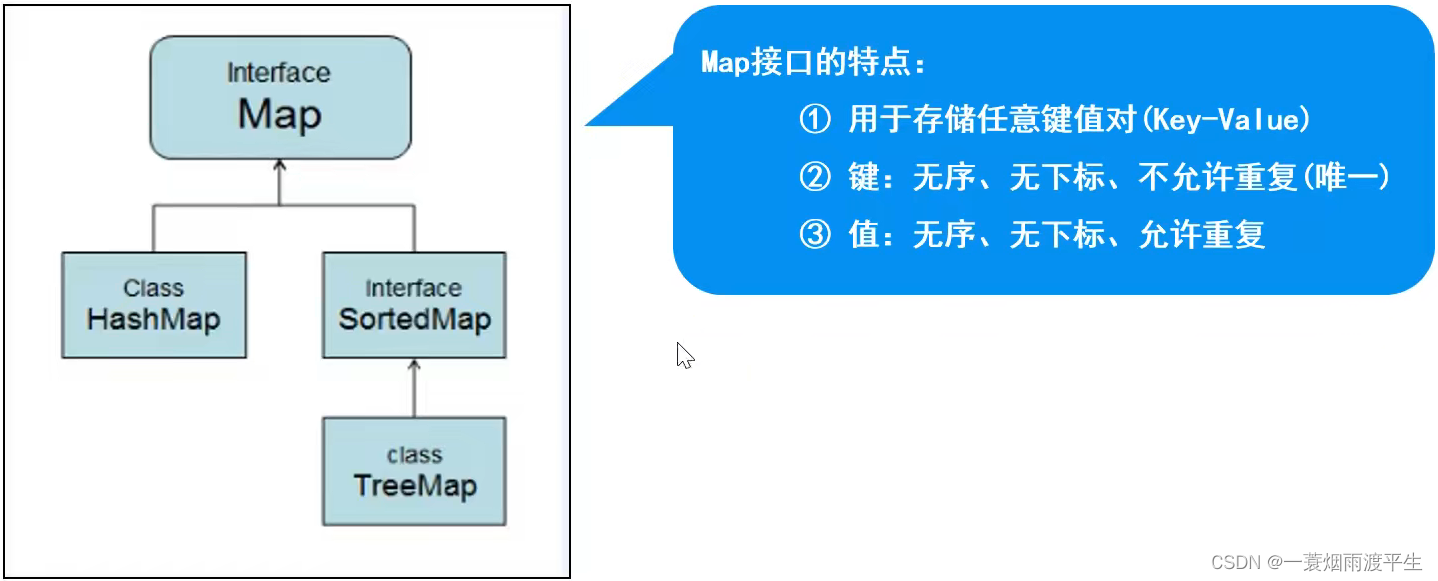
2.2 Map接口
Map接口的特点:
1、用于存储任意键值对(Key-Value); 2、Key:无序、不可重复 3、Value:无序、可重复
通过下面代码理解Map的特点:
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class MapTest {
public static void main(String[] args){
//创建Map集合
Map<String,String> map = new HashMap<>();
//1.添加元素
map.put("aa","11");
map.put("bb","22");
map.put("cc","33");
map.put("aa","44"); //当添加key相等的键值对时,会覆盖之前键值对的value
System.out.println("Map中的元素个数:" + map.size());
System.out.println(map.toString());
//Map的两种遍历方式
System.out.println("方式一");
for(String key: map.keySet()){
System.out.println(key + " "+ map.get(key));
}
System.out.println("方式二");
Set<Map.Entry<String,String>> entries = map.entrySet();
for(Map.Entry<String,String> entry : entries){
System.out.println(entry.getKey() + " " + entry.getValue());
}
}
/* 遍历输出
aa 44 (将之前的aa 11)中的11被44覆盖了
bb 22
cc 33
*/
}
Map接口主要由HashMap类和TreeMap类实现。
2.2.1HashMap
- HashMap:线程不安全,效率高,JDK1.7之前基于数组+链表实现,JDK1.8基于数组+链表+红黑树实现。JDK1.8相较于JDK1.7的一些改变如下:
1)当new HashMap()时,底层没有创建一个长度为16的数组,此时长度为0;
2)JDK1.8底层的数组是Node[],而非是Entry[];
3)首次添加数据时,底层会创建一个长度为16的数组;
4)当数组的索引位置上的元素个数【即链表长度】大于8且当前数组长度大于64时,此时索引位置上的所有数据将改为红黑树【即将链表存储改成红黑树存储】,
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
static final float DEFAULT_LOAD_FACTOR = 0.75f;
static final int TREEIFY_THRESHOLD = 8;
static final int MIN_TREEIFY_CAPACITY = 64;
//new HashMap时,oldThr==0;
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); //16*0.75 =12
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
//当添加数据时,如果长度超过12时,数组长度扩充为原来的两倍
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
注意,使用HashMap时,需要重写当前添加数据类中Key的equals方法和HashCode方法,案例如下:
import java.util.HashMap;
public class HashMapTest {
public static void main(String[] args) {
//创建集合
HashMap<Person1,String> ph = new HashMap<>();
//添加元素
Person1 p1 = new Person1("aa",11);
Person1 p2 = new Person1("bb",22);
Person1 p3 = new Person1("cc",33);
ph.put(p1,"冬");
ph.put(p2,"夏");
ph.put(p3,"秋");
Person1 p4 = new Person1("aa",11);
ph.put(p4,"冬");
/*
当你添加p4元素时,发现仍然可以添加成功,为什么呢?这不是破坏了HashMap中Key不可重复性原则吗?
答:不可重复性原则是根据equlas来判断的,在没有重写时,equals比较的是地址值,而不是我们想要的内容,
如果想按自己的方式比较是否等于,需要在Person1类中重写equals方法和HashCode方法。
*/
System.out.println("集合元素个数:" + ph.size());
System.out.println(ph.toString());
}
}
【补充:HashMap线程不安全,运行效率快,允许用null作为Key或者是Value;ConcurrentHashMap线程安全,采用锁分段技术,就是将数组分成几个小的片段segment,每个片段都有锁存在,那么在插入元素时就需要先获取segment锁再在这个片段上进行插入。】
2.2.2TreeMap
- TreeMap:基于红黑树实现的,在添加数据时,需要进行排序。
排序的方法和之前说的TreeSet一样,有两种方法,自然排序和定制排序;
自然排序要求添加的数据实现Comparable接口,重写compareTo方法;
定制排序要求在创建TreeMap时,重写Comparator中compare方法。
3. Collections工具类
Collections不属于Java的集合框架,它是集合类的一个工具类。此类不能被实例化,服务于Java的Collection框架。
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class CollectionsTest {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(11);
list.add(14);
list.add(3);
list.add(8);
list.add(66);
//sort排序 默认从小到大
System.out.println("排序之前:" + list.toString());
Collections.sort(list);
System.out.println("排序之后:" + list.toString());
//binarySearch 二分查找 返回负数则没有
int i = Collections.binarySearch(list,14);
System.out.println(i);
//reverse 反转
Collections.reverse(list);
System.out.println("反转之后:" + list);
}
}
4.总结:
1、Java集合的概念:存储对象的容器;
2、Java集合分为Collection接口和Map接口,而Collections工具类用以服务Java集合;
3、Collection接口由List接口和Set接口组成,其中List接口由ArrayList、LinkedList、Vector类实现,List存储的数据有序、可重复;Set接口由HashSet和TreeSet类实现,Set存储的数据无序、不可重复;
4、Map接口由HashMap和TreeMap类实现,其中Key值无序、不可重复,Value无序、可重复。


















 387
387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











