







目录
一、统计出每个月,每个用户的累积访问次数
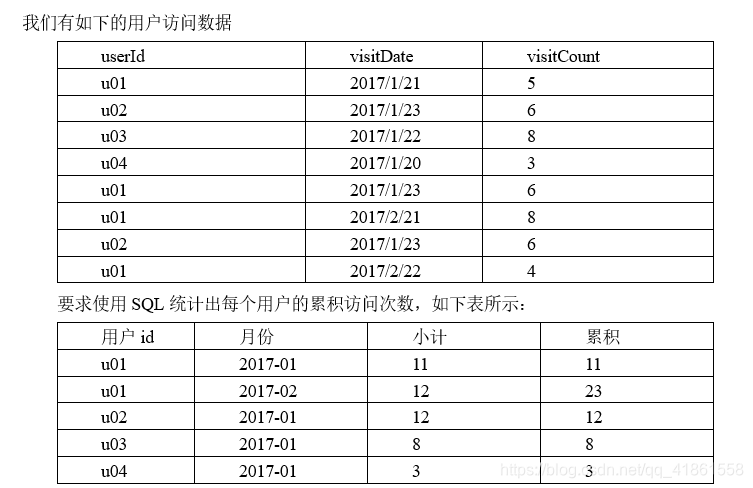
select
userid,visitdate,
sum_count,sum(sum_count) over(partition by userid order by visitdate)
from
(select userid,visitdate,sum(visitcount) sum_count
from
(select userid,
date_format(regexp_replace(visitdate,'/','-'),'yyyy-MM') visitdate,
visitcount
from action) t1
group by
userid,
visitdate) t2;解析:最里面select查询转换时间格式,第二个查询实现每个userid,每个月的visitcount求和,最外层窗口函数实现累加。
二、店铺的UV、TopN统计
有50W个京东店铺,每个顾客访问任何一个店铺的任何一个商品时都会产生一条访问日志,访问日志存储的表名为visit,访客的用户id为user_id,被访问的店铺名称为shop,请统计:
u1 a
u2 b
u1 b
u1 a
u3 c
u4 b
u1 a
u2 c
u5 b
u4 b
u6 c
。。。。。。建表:
create table visit(user_id string,shop string) row format delimited fields terminated by '\t';功能需求:
1、每个店铺的UV(访客数)
方式一distinct(不推荐):
select shop,count(distinct(user_id)) uv from visit group by shop;可以实现功能,但是distinct是针对整个表去重,当数据量很大的时候,reducer的任务太重。
方式二:
select shop,count(*)
from
(select shop,user_id
from visit
group by shop,user_id) t1
group by shop;里面的group by 两个字段实现去重
2、每个店铺访问次数top3的访客信息。输出店铺名称、访客id、访问次数
select shop,user_id,ct
from
(select *,row_number() over(partition by shop order by ct desc) rk
from
(select shop,user_id,count(user_id) ct
from visit
group by shop,user_id)t1)t2
where rk<=3;注意点:1)having必须与group by一同使用,所以having rk<=3 错误
2)where rk <=3,row_number是虚拟列,所以作为子循环再嵌套一层查询
最终结果:
a u5 3
a u1 3
a u2 2
b u4 2
b u1 2
b u5 1
c u2 2
c u6 1
c u3 1如果并列成绩超过3,根据业务需求考虑用rank()函数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2671
2671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









