







MySQL牛客篇
目录
- MySQL牛客篇
- SQL2
- SQL18
- SQL37 对first_name创建唯一索引uniq_idx_firstname
- SQL38 针对actor表创建视图actor_name_view
- SQL39 针对上面的salaries表emp_no字段创建索引idx_emp_no
- SQL40 在last_update后面新增加一列名字为create_date
- SQL 41 触发器
- SQL42
- SQL44
- SQL46 创建外键约束
- SQL48 将所有获取奖金的员工当前的薪水增加10%
- SQL12
- SQL35
- SQL36
- SQL51 查找字符串 10,A,B 中逗号,出现的次数cnt
- SQL52 获取Employees中的first_name
- SQL53 按照dept_no进行汇总
- `LIMIT`AND `OFFSET`
- SQL57 使用含有关键字exists查找未分配具体部门的员工的所有信息。
- SQL63 刷题通过的题目排名
- SQL73 考试分数(二)
- SQL85 实习广场投递简历分析(二)
- SQL87 最差是第几名(一)
- SQL88
- SQL90
SQL2
SELECT * FROM employees
ORDER BY hire_date DESC LIMIT 1 OFFSET 2;#(跳过前两个,选择一个)
# 等价于 LIMIT 2 , 1;
LIMIT 子句(OFFSET)
要检索查询返回的行的一部分,请使用LIMIT和OFFSET子句。
语法
SELECT
column_list
FROM
table1
ORDER BY column_list
LIMIT row_count OFFSET offset;
在这个语法中,
row_count确定将返回的行数。OFFSET子句在开始返回行之前跳过偏移行。OFFSET子句是可选的。 如果同时使用LIMIT和OFFSET子句,OFFSET会在LIMIT约束行数之前先跳过偏移行。
SQL18
获取当前薪水第二多的员工的emp_no以及其对应的薪水salary
步骤一:自连接并筛选s1.salary <= s2.salary的行
SELECT * FROM salaries AS s1
JOIN salaries AS s2 ON s1.salary <= s2.salary
| 10004 | 74057 | 2001-11-27 | 9999-01-01 | 10001 | 88958 | 2002-06-22 |
| 10003 | 43311 | 2001-12-01 | 9999-01-01 | 10001 | 88958 | 2002-06-22 |
| 10002 | 72527 | 2001-08-02 | 9999-01-01 | 10001 | 88958 | 2002-06-22 |
| 10001 | 88958 | 2002-06-22 | 9999-01-01 | 10001 | 88958 | 2002-06-22 |
| 10003 | 43311 | 2001-12-01 | 9999-01-01 | 10002 | 72527 | 2001-08-02 |
| 10002 | 72527 | 2001-08-02 | 9999-01-01 | 10002 | 72527 | 2001-08-02 |
| 10003 | 43311 | 2001-12-01 | 9999-01-01 | 10003 | 43311 | 2001-12-01 |
| 10004 | 74057 | 2001-11-27 | 9999-01-01 | 10004 | 74057 | 2001-11-27 |
| 10003 | 43311 | 2001-12-01 | 9999-01-01 | 10004 | 74057 | 2001-11-27 |
| 10002 | 72527 | 2001-08-02 | 9999-01-01 | 10004 | 74057 | 2001-11-27 |
步骤二:查找第二多的工资是多少
SELECT s1.salary FROM salaries AS s1
JOIN salaries AS s2 ON s1.salary <= s2.salary
GROUP BY s1.salary
HAVING COUNT(s2.salary) = 2
步骤三:完善外层查询后的最终代码
SELECT employees.emp_no, salaries.salary,
employees.last_name, employees.first_name
FROM employees JOIN salaries ON
employees.emp_no = salaries.emp_no
WHERE salaries.salary = (
SELECT s1.salary FROM salaries AS s1
JOIN salaries AS s2 ON s1.salary <= s2.salary
GROUP BY s1.salary
HAVING COUNT(s2.salary) = 2
)
SQL37 对first_name创建唯一索引uniq_idx_firstname
对first_name创建唯一索引uniq_idx_firstname
MySQL中四种方式给字段添加索引
关于MySQL中给字段创建索引的四种方式:
- 添加主键
ALTER TABLE tbl_name ADD PRIMARY KEY (col_list);
该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL。
- 添加唯一索引
ALTER TABLE tbl_name ADD UNIQUE index_name (col_list);
这条语句创建索引的值必须是唯一的。
- 添加普通索引
ALTER TABLE tbl_name ADD INDEX index_name (col_list);
添加普通索引,索引值可出现多次。
- 添加全文索引
ALTER TABLE tbl_name ADD FULLTEXT index_name (col_list);
该语句指定了索引为 FULLTEXT ,用于全文索引。
- PS: 附赠删除索引的语法:
DROP INDEX index_name ON tbl_name;
或者
ALTER TABLE tbl_name DROP INDEX index_name;
ALTER TABLE tbl_name DROP PRIMARY KEY;
SQL38 针对actor表创建视图actor_name_view
CEATE VIEW 创建视图
- 直接在视图名的后面用小括号创建视图中的字段名
create view actor_name_view (first_name_v,last_name_v) as
select first_name ,last_name from actor
- 在select后面对列重命名为视图的字段名
create view actor_name_view as
select first_name as first_name_v
,last_name as last_name_v
from actor
SQL39 针对上面的salaries表emp_no字段创建索引idx_emp_no
针对上面的salaries表emp_no字段创建索引idx_emp_no
强制索引
select *
from salaries
force index (idx_emp_no)
where emp_no=10005
SQL40 在last_update后面新增加一列名字为create_date
在last_update后面新增加一列名字为create_date
题目描述:现在在last_update后面新增加一列名字为create_date, 类型为datetime, NOT NULL,默认值为’2020-10-01 00:00:00’
alter table添加表列的语法:
ALTER TABLE table_name
ADD column_name datatype;
所以这道题的答案:
alter table actor
add create_date datetime not null default "2020-10-01 00:00"
SQL 41 触发器
构造一个触发器audit_log
方法:构造触发器
CREATE TRIGGER audit_log
AFTER INSERT ON employees_test
FOR EACH ROW
BEGIN
INSERT INTO audit VALUES(new.id,new.name);
END
在MySQL中,创建触发器语法如下:
CREATE TRIGGER trigger_name
trigger_time trigger_event ON tbl_name
FOR EACH ROW
trigger_stmt
其中:
- trigger_name:标识触发器名称,用户自行指定;
- trigger_time:标识触发时机,取值为 BEFORE 或 AFTER;
- trigger_event:标识触发事件,取值为 INSERT、UPDATE 或 DELETE;
- tbl_name:标识建立触发器的表名,即在哪张表上建立触发器;
- trigger_stmt:触发器程序体,可以是一句SQL语句,或者用 BEGIN 和 END 包含的多条语句,每条语句结束要分号结尾。
SQL42
错误方法:
DELETE FROM titles_test
WHERE id NOT IN(
SELECT MIN(id)
FROM titles_test
GROUP BY emp_no);
MySQL中不允许在子查询的同时删除表数据(不能一边查一边把查的表删了)
正确方法
DELETE FROM titles_test
WHERE id NOT IN(
SELECT * FROM(
SELECT MIN(id)
FROM titles_test
GROUP BY emp_no)a); -- 把得出的表重命名那就不是原表了(机智.jpg
SQL44
将id=5以及emp_no=10001的行数据替换成id=5以及emp_no=10005
REPLACE的使用
REPLACE不支持WHERE子句- MySQL使用
PRIMARY KEY或UNIQUE KEY索引来要确定表中是否存在新行 - 如果给定行数据不存在,那么MySQL
REPLACE语句会插入一个新行。 - 如果给定行数据存在,则
REPLACE语句首先删除旧行(区别与UPDATE,若只REPLACE某行的部分数据,则其余数据未空值),然后插入一个新行。 在某些情况下,REPLACE语句仅更新现有行。
-- 方法一:利用id冲突后会将该段记录覆盖之前的
REPLACE INTO titles_test VALUES (5, 10005, 'Senior Engineer', '1986-06-26', '9999-01-01')
-- 方法二:精确打击
UPDATE titles_test SET emp_no = REPLACE(emp_no,10001,10005) WHERE id = 5
SQL46 创建外键约束
SQL 46) -ADD CONSTRAINT FOREIGN KEY 创建外键约束
方法:创建外键
ALTER TABLE audit
ADD CONSTRAINT FOREIGN KEY (emp_no)
REFERENCES employees_test(id);
创建外键语句结构:
ALTER TABLE <表名>
ADD CONSTRAINT FOREIGN KEY (<列名>)
REFERENCES <关联表>(关联列)
SQL48 将所有获取奖金的员工当前的薪水增加10%
更新数据
update salaries
set salary=salary*1.1
where to_date="9999-01-01"
注意 很多时候会用到SELECT,而SELECT的同时不能UPDATE,因此要创建子查询(临时表)
update salaries
set salary=salary*1.1
where to_date="9999-01-01" and emp_no in
(
select emp_no
from emp_bonus
)
SQL12
(注意: Mysql与Sqlite select 非聚合列的结果可能不一样)
若代码如下:
SELECT dept_emp.*, salaries.*
FROM dept_emp LEFT JOIN salaries
ON dept_emp.emp_no = salaries.emp_no
GROUP BY dept_no
ORDER BY dept_emp.dept_no
输入为:
drop table if exists `dept_emp` ;
drop table if exists `salaries` ;
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
INSERT INTO dept_emp VALUES(10001,'d001','1986-06-26','9999-01-01');
INSERT INTO dept_emp VALUES(10002,'d001','1996-08-03','9999-01-01');
INSERT INTO dept_emp VALUES(10003,'d004','1995-12-03','9999-01-01');
INSERT INTO dept_emp VALUES(10004,'d004','1986-12-01','9999-01-01');
INSERT INTO dept_emp VALUES(10005,'d003','1989-09-12','9999-01-01');
INSERT INTO dept_emp VALUES(10006,'d002','1990-08-05','9999-01-01');
INSERT INTO dept_emp VALUES(10007,'d005','1989-02-10','9999-01-01');
INSERT INTO dept_emp VALUES(10009,'d006','1985-02-18','9999-01-01');
INSERT INTO dept_emp VALUES(10010,'d006','2000-06-26','9999-01-01');
INSERT INTO salaries VALUES(10001,88958,'2002-06-22','9999-01-01');
INSERT INTO salaries VALUES(10002,72527,'2001-08-02','9999-01-01');
INSERT INTO salaries VALUES(10003,43311,'2001-12-01','9999-01-01');
INSERT INTO salaries VALUES(10004,74057,'2001-11-27','9999-01-01');
INSERT INTO salaries VALUES(10005,94692,'2001-09-09','9999-01-01');
INSERT INTO salaries VALUES(10006,43311,'2001-08-02','9999-01-01');
INSERT INTO salaries VALUES(10007,88070,'2002-02-07','9999-01-01');
INSERT INTO salaries VALUES(10009,95409,'2002-02-14','9999-01-01');
INSERT INTO salaries VALUES(10010,94409,'2001-11-23','9999-01-01');
则输出为:
| 10001 | d001 | 1986-06-26 | 9999-01-01 | 10001 | 88958 | 2002-06-22 | 9999-01-01 |
| 10002 | d001 | 1996-08-03 | 9999-01-01 | 10002 | 72527 | 2001-08-02 | 9999-01-01 |
| 10006 | d002 | 1990-08-05 | 9999-01-01 | 10006 | 43311 | 2001-08-02 | 9999-01-01 |
| 10005 | d003 | 1989-09-12 | 9999-01-01 | 10005 | 94692 | 2001-09-09 | 9999-01-01 |
| 10003 | d004 | 1995-12-03 | 9999-01-01 | 10003 | 43311 | 2001-12-01 | 9999-01-01 |
| 10004 | d004 | 1986-12-01 | 9999-01-01 | 10004 | 74057 | 2001-11-27 | 9999-01-01 |
| 10007 | d005 | 1989-02-10 | 9999-01-01 | 10007 | 88070 | 2002-02-07 | 9999-01-01 |
| 10009 | d006 | 1985-02-18 | 9999-01-01 | 10009 | 95409 | 2002-02-14 | 9999-01-01 |
| 10010 | d006 | 2000-06-26 | 9999-01-01 | 10010 | 94409 | 2001-11-23 | 9999-01-01 |
使用聚合函数MAX
SELECT dept_emp.*, salaries.*, MAX(salary)
FROM dept_emp LEFT JOIN salaries
ON dept_emp.emp_no = salaries.emp_no
GROUP BY dept_no
ORDER BY dept_emp.dept_no
则输出为:
| 10001 | d001 | 1986-06-26 | 9999-01-01 | 10001 | 88958 | 2002-06-22 | 9999-01-01 | 88958 |
| 10006 | d002 | 1990-08-05 | 9999-01-01 | 10006 | 43311 | 2001-08-02 | 9999-01-01 | 43311 |
| 10005 | d003 | 1989-09-12 | 9999-01-01 | 10005 | 94692 | 2001-09-09 | 9999-01-01 | 94692 |
| 10003 | d004 | 1995-12-03 | 9999-01-01 | 10003 | 43311 | 2001-12-01 | 9999-01-01 | 74057 |
| 10007 | d005 | 1989-02-10 | 9999-01-01 | 10007 | 88070 | 2002-02-07 | 9999-01-01 | 88070 |
| 10009 | d006 | 1985-02-18 | 9999-01-01 | 10009 | 95409 | 2002-02-14 | 9999-01-01 | 95409 |
会看到不是聚合列的dept_emp.emp_no会和 salary 不匹配。
我的最终代码
#第二步:将第一步得到的“部门最高薪水表”和“员工表”、“新水表”连接
SELECT dept_emp.dept_no, dept_emp.emp_no,X.maxSalary
FROM dept_emp JOIN salaries
ON dept_emp.emp_no = salaries.emp_no
JOIN(
#第一步:找每个部门的最高薪水
SELECT dept_no, MAX(salary) AS maxSalary
FROM dept_emp JOIN salaries
ON dept_emp.emp_no = salaries.emp_no
GROUP BY dept_no) AS X
#第三步:完成整个逻辑
ON dept_emp.dept_no = X.dept_no
WHERE salaries.salary = X.maxSalary
ORDER BY dept_no
SQL35
mysql中常用的三种插入数据的语句:
insert into表示插入数据,数据库会检查主键,如果出现重复会报错;replace into表示插入替换数据,需求表中有Primary Key,- 或者
unique索引,如果数据库已经存在数据,则用新数据替换,如果没有数据效果则和insert into一样;insert ignore表示,如果中已经存在相同的记录,则忽略当前新数据;
insert ignore into actor values("3","ED","CHASE","2006-02-15 12:34:33");
SQL36
MYSQL创建数据表的三种方法:
- 常规创建
create table if not exists 目标表- 复制表格
create 目标表 like 来源表- 将table1的部分拿来创建table2
create table if not exists actor_name
(
first_name varchar(45) not null,
last_name varchar(45) not null
)
select first_name,last_name
from actor
或者
CREATE TABLE actor_name -- 创建表
(first_name varchar(45) NOT NULL,
last_name varchar(45) NOT NULL);
INSERT INTO actor_name -- 插入数据
SELECT first_name,last_name
FROM actor;
SQL51 查找字符串 10,A,B 中逗号,出现的次数cnt
length函数和replace函数的应用
SELECT LENGTH('10,A,B') - LENGTH(REPLACE('10,A,B',',','')) AS cnt
SQL52 获取Employees中的first_name
right函数的应用(取最后边开始的若干字符)
SELECT first_name FROM employees
ORDER BY RIGHT(first_name, 2)
SQL53 按照dept_no进行汇总
GROUP_CONCAT函数的应用(按GROUP BY合并字段)
SELECT dept_no, GROUP_CONCAT(emp_no) AS employees FROM dept_emp
GROUP BY dept_no
LIMITAND OFFSET
limit x,yx:偏移量 y:要获取的个数
limit 5,5; 偏移量为5,取5条记录
2.limit y offset x
limit 5 offset 5; 取5条记录,偏移量为5
SQL57 使用含有关键字exists查找未分配具体部门的员工的所有信息。
使用含有关键字exists查找未分配具体部门的员工的所有信息。
EXISTSVSIN
题目描述:使用含有关键字exists查找未分配具体部门的员工的所有信息。
EXISTS语句:执行employees.length次
指定一个子查询,检测行的存在。遍历循环外表,然后看外表中的记录有没有和内表的数据一样的。匹配上就将结果放入结果集中。
select *
from employees
where not exists
(
select emp_no
from dept_emp
where employees.emp_no=dept_emp.emp_no
)
IN语句:只执行一次
确定给定的值是否与子查询或列表中的值相匹配。in在查询的时候,首先查询子查询的表,然后将内表和外表做一个笛卡尔积,然后按照条件进行筛选。所以相对内表比较小的时候,in的速度较快。
select *
from employees
where emp_no not in
(
select emp_no
from dept_emp
)
两者详细资料(Sql 语句中 IN 和 EXISTS 的区别及应用):https://blog.youkuaiyun.com/wqc19920906/article/details/79800374
SQL63 刷题通过的题目排名
方法一:
窗口函数
语法:
函数名([参数]) over(partition by [分组字段] order by [排序字段] asc/desc rows/range between 起始位置 and 结束位置)
函数解读:
函数分为两个部分:
第一部分是函数名称,开窗函数的数量较少,只有11个窗口函数+聚合函数(所有聚合函数都可以用作开窗函数),根据函数性质,有的要写参数,有的不需要写参数;
第二部分是over语句,over()是必须要写的,里面有三个参数,都是非必须参数,根据需求选写:
1.第一个参数是 partition by +分组字段,将数据根据此字段分成多份,如果不加partition by参数,那会把整个数据当做一个窗口。
2.第二个参数是 order by +排序字段,每个窗口的数据要不要进行排序。
3.第三个参数 rows/range between 起始位置 and 结束位置,这个参数仅针对滑动窗口函数有用,是在当前窗口下分出更小的子窗口。
其中起始位置和结束位置可写:
- current row 边界是当前行
- unbounded preceding 边界是分区中的第一行
- unbounded following 边界是分区中的最后一行
- expr preceding 边界是当前行减去expr的值
- expr following 边界是当前行加上expr的值。rows是基于行数,range是基于值的大小,到讲解到滑动窗口函数时再详细介绍。
row_number()是没有重复值的排序(即使两个记录相等也是不重复的),可以利用它来实现分页,如1,2,3,4
dense_rank()是连续排序,两个第二名仍然跟着第三名,如1,2,2,3
rank() 是跳跃排序,两个第二名下来就是第四名,如1,2,2,4
SELECT id, number, dense_rank() over
(ORDER BY number DESC) `rank`
FROM passing_number
ORDER BY `rank`, id
lag()
其他窗口函数:LAG()函数从同一结果集中的当前行访问上一行的数据。
窗口函数的别名似乎不能出现在where中
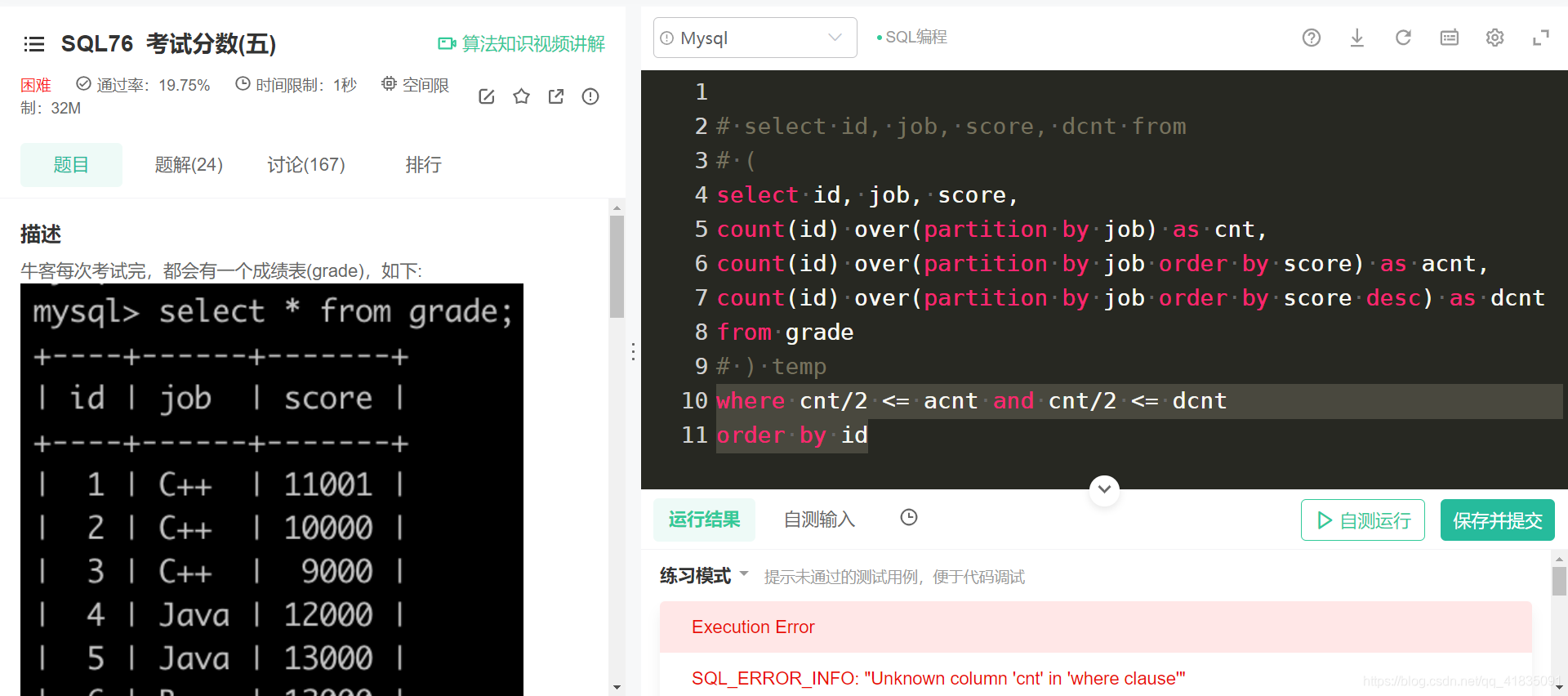
但是将该表作为过渡,似乎又可以
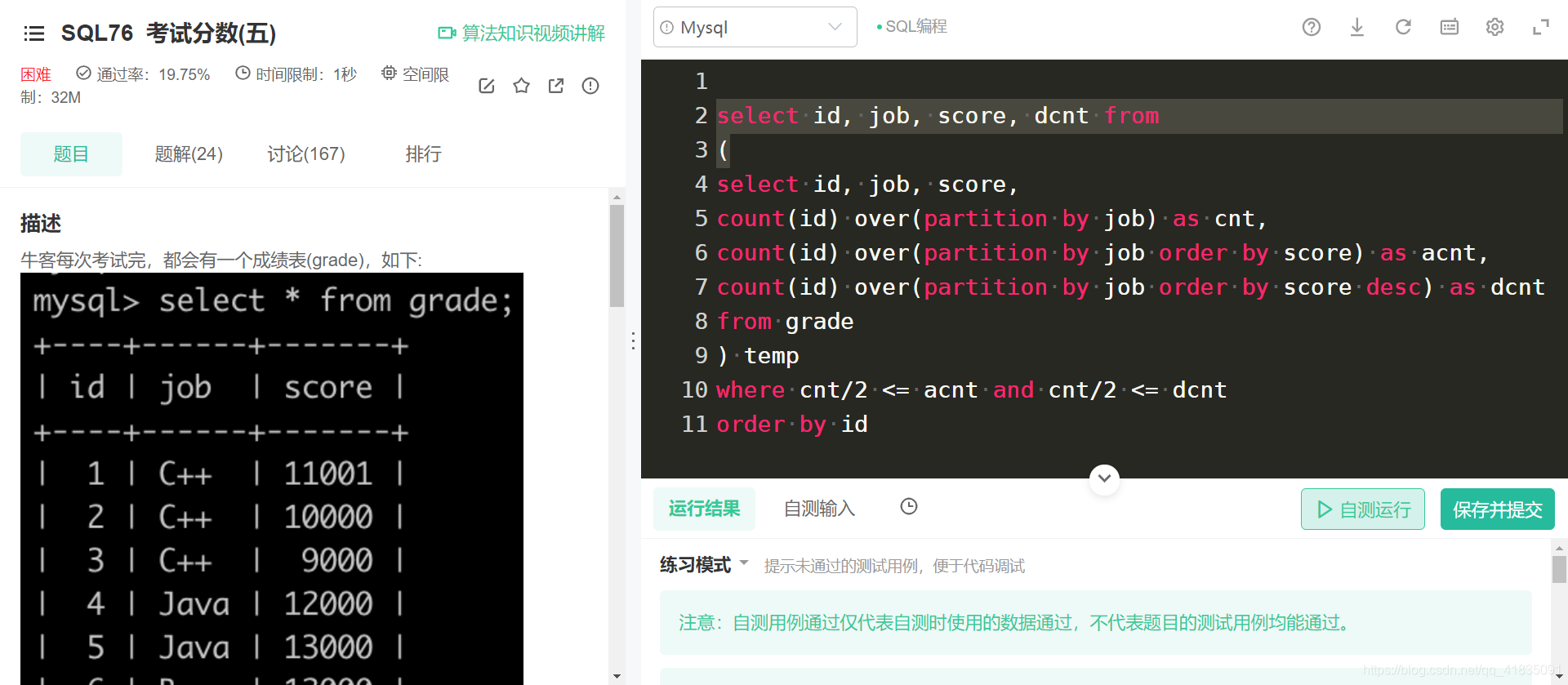
方法二:自连接
首先要通过题目降序,id升序,那么sql应该为:
select a.id,a.number
from passing_number a order by a.number desc, a.id asc;
要得到通过题目的排名,比如你通过了8分,,你同学a也通过了8分,找到大于等于你的成绩,一个9分,一个8分,一个8分,去重复,就一个9,一个8,count一下总数,第2名,如果有三个同学通过了7个呢,同理,9,8,8,7,7,7 后面比这个少的,已经死在了筛选条件,去重,9,8,7,count=3,所以sql为:
select a.id,a.number,
(select count(distinct b.number) from passing_number b where b.number>=a.number )
from passing_number a order by a.number desc, a.id asc;
联立为:
select a.id,a.number,
(select count(distinct b.number) from passing_number b where b.number>=a.number )
from passing_number a order by a.number desc, a.id asc;
SQL73 考试分数(二)
GROUP BY常见错误使用
原表:
1|C++|11001
2|C++|10000
3|C++|9000
4|Java|12000
5|Java|13000
6|JS|12000
7|JS|11000
8|JS|9999
9|Java|12500
SELECT *, avg(score) FROM grade
GROUP BY job
以上代码的输出为:
1|C++|11001|10000.3333
4|Java|12000|12500.0000
6|JS|12000|10999.6667
聚合函数只会按聚合项显示一条结果,不会有全部的数据!!
SQL85 实习广场投递简历分析(二)
日期函数格式转换
DATE_FORMAT(date,format)
DATE_FORMAT() 函数用于以不同的格式显示日期/时间数据。
date 参数是合法的日期。format 规定日期/时间的输出格式。
可以使用的格式有:
| 常用格式 | 对应描述 |
|---|---|
| %Y | –年,4 位 |
| %m | –月,数值(00-12) |
| %M | –月名 |
| %k | –小时(0-23) |
日期函数详解 转载自:菜鸟教程https://www.runoob.com/sql/func-date-format.html
SQL87 最差是第几名(一)
窗口函数SUM(XX) OVER(ORDER BY XX)
本题出题的题意其实主要是考察sum() over (order by ) 开窗函数,sum(a) over (order by b)的含义是:
例如
a b
1 2
3 4
5 6
按照b列排序,将a依次相加,得到结果,如下:
| a | b | sum(a) over (order by b) |
|---|---|---|
| 1 | 2 | 1 |
| 3 | 4 | 1+3 |
| 5 | 6 | 1+3+5 |
使用窗口函数:
SELECT grade, SUM(number) OVER (ORDER BY grade) AS t_rank
FROM class_grade
GROUP BY grade
ORDER BY grade
巧用表的自连接和运算符代替排序
不使用窗口函数:
步骤一: 连接,做笛卡尔积,筛选T2表中比T1小的
SELECT T1.*, T2.*
FROM class_grade T1
JOIN class_grade T2 ON T2.grade <= T1.grade
ORDER BY T1.grade, T2.grade
结果为:
| T1.grade | T1带来的无用列 | T2.grade | |
|---|---|---|---|
| A | 2 | A | 2 |
| B | 2 | A | 2 |
| B | 2 | B | 2 |
| C | 2 | A | 2 |
| C | 2 | B | 2 |
| C | 2 | C | 2 |
| D | 1 | A | 2 |
| D | 1 | B | 2 |
| D | 1 | C | 2 |
| D | 1 | D | 1 |
步骤二: 按T2.grade分组再求和
SELECT T1.grade, SUM(T2.number) AS t_rank
FROM class_grade T1
JOIN class_grade T2 ON T2.grade <= T1.grade
GROUP BY T1.grade
ORDER BY T1.grade
SQL88
关于中位数
大佬思路:
当某一数的正序和逆序累计
均大于整个序列的数字个数的一半即为中位数.
select grade from
(select grade,
sum(number) over() as total,
sum(number) over(order by grade) as a,
sum(number) over(order by grade desc) as b
from class_grade) temp
where total/2 <= a and total/2 <= b
order by grade
SQL90
创建临时表
可以学一下创建临时表,减少代码量。
with temp as(
select user.id, user.name,
sum(grade_info.grade_num) as grade_sum
from grade_info
left join user
on grade_info.user_id = user.id
group by grade_info.user_id)
后续就可以用’temp’这个表了

















 1517
1517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









