




 本文介绍了一种结合BERT和LSTM的情感分析模型实现过程,包括模型定义、训练及预测等关键步骤,并通过实例展示了如何利用该模型进行中文情感极性判断。
本文介绍了一种结合BERT和LSTM的情感分析模型实现过程,包括模型定义、训练及预测等关键步骤,并通过实例展示了如何利用该模型进行中文情感极性判断。
class是一个生产bert_lstm的工厂,工厂里有一个初始化函数(init)和两个instance method功能函数(forward,init_hidden)
instance method是指工厂里加工初始化后bert_lstm的函数
还有一种class method,是指对工厂进行加工的函数,这里不涉及。
一个bert_lstm需要output_size,n_layers,hidden_dim,bidirectional,lstm,dropout(所有self.的东西)才能被构造
使用instance method,需要知道对哪个bert_lstm进行加工,但是由于还未初始化,所以必须空出一个位置,暂时用self替代,等到给出具体初始化参数后,生成了一个原始的bert_lstm后,再对这个原始bert_lstm进行加工操作。
class bert_lstm(nn.Module):
def __init__(self, hidden_dim, output_size, n_layers, bidirectional=True, drop_prob=0.5):
super(bert_lstm, self).__init__()
drop_prob:训练网络时,将网络神经单元,按一定概率暂时丢弃。具有随机性,用于防止过拟合,一般设置0.5
self.output_size = output_size
self.n_layers = n_layers
self.hidden_dim = hidden_dim
self.bidirectional = bidirectional
# Bert ----------------重点,bert模型需要嵌入到自定义模型里面
self.bert = BertModel.from_pretrained("bert_base_chinese")
for param in self.bert.parameters():
param.requires_grad = True
# LSTM layers
self.lstm = nn.LSTM(768, hidden_dim, n_layers, batch_first=True, bidirectional=bidirectional)
# dropout layer
self.dropout = nn.Dropout(drop_prob)
# linear and sigmoid layers
if bidirectional:
self.fc = nn.Linear(hidden_dim * 2, output_size)
else:
self.fc = nn.Linear(hidden_dim, output_size)
# self.sig = nn.Sigmoid()
def forward(self, x, hidden):
batch_size = x.size(0)
# 生成bert字向量
x = self.bert(x)[0] # bert 字向量
x(一个tensor)经卷积或者池化之后的维度为(batchsize,channels,x,y),取第0个位置的值,即batchsize的值作为batch_size
# lstm_out
# x = x.float()
lstm_out, (hidden_last, cn_last) = self.lstm(x, hidden)
# print("3shape:") #[32,100,768]
# print(lstm_out.shape)
# print(hidden_last.shape) #[4, 32, 384]
# print(cn_last.shape) #[4, 32, 384]
# 修改 双向的需要单独处理
if self.bidirectional:
# 正向最后一层,最后一个时刻
hidden_last_L = hidden_last[-2]
# print("hidden_last_L.shape:")
# print(hidden_last_L.shape) #[32, 384]
# 反向最后一层,最后一个时刻
hidden_last_R = hidden_last[-1]
# print("hidden_last_R.shape:")
# print(hidden_last_R.shape) #[32, 384]
# 进行拼接
hidden_last_out = torch.cat([hidden_last_L, hidden_last_R], dim=-1)
# print("hidden_last_out.shape:")
# print(hidden_last_out.shape,'hidden_last_out') #[32, 768]
else:
hidden_last_out = hidden_last[-1] # [32, 384]
# dropout and fully-connected layer
out = self.dropout(hidden_last_out)
# print('out.shape:')
# print(out.shape) #[32,768]
out = self.fc(out)
return out
调用ConvLSTMCell中的init_hidden函数,得到初始的hidden_state
def init_hidden(self, batch_size):
weight = next(self.parameters()).data
number = 1
if self.bidirectional:
number = 2
if (USE_CUDA):
hidden = (weight.new(self.n_layers * number, batch_size, self.hidden_dim).zero_().float().cuda(),
weight.new(self.n_layers * number, batch_size, self.hidden_dim).zero_().float().cuda()
)
else:
hidden = (weight.new(self.n_layers * number, batch_size, self.hidden_dim).zero_().float(),
weight.new(self.n_layers * number, batch_size, self.hidden_dim).zero_().float()
)
return hidden
根据上述代码,提供参数,可以构造出一个bert_lstm
output_size = 1
hidden_dim = 384 # 768/2
n_layers = 2
bidirectional = True # 这里为True,为双向LSTM
net = bert_lstm(hidden_dim, output_size, n_layers, bidirectional)
预测函数(不属于class bert_lstm)
主要的类是BasicTokenizer,做一些基础的大小写、unicode转换、标点符号分割、小写转换、中文字符分割、去除重音符号等操作,最后返回的是关于词的数组(中文是字的数组)
def predict(net, test_comments):
comments_list = pretreatment(test_comments) # 预处理去掉标点符号
# 转换为字id
tokenizer = BertTokenizer.from_pretrained("bert_base_chinese")
根据bert_base_chinese中的字典vocab.txt,tokenizer(分词器)可以将一个句子分解为单个字,每个字编号,即id
comments_list_id = tokenizer(comments_list, padding=True, truncation=True, max_length=120, return_tensors='pt')
tokenizer_id = comments_list_id['input_ids']
inputs = tokenizer_id
batch_size = inputs.size(0)
# initialize hidden state
h = net.init_hidden(batch_size)
if (USE_CUDA):
inputs = inputs.cuda()
net.eval()
在训练模型时会在前面加上:net.train(),在测试模型时在前面使用:net.eval()
with torch.no_grad():
让tensor进行反向传播时不会自动求导,节约内存。
output = net(inputs, h)
当output是一个元素张量,用item得到元素值。
if output.item() >= 0:
print("预测结果为:正向")
else:
print("预测结果为:负向")
if __name__ == '__main__':
np.random.seed(2020)
torch.manual_seed(2020) # 为CPU设置种子用于生成随机数,以使得结果是确定的
USE_CUDA = torch.cuda.is_available()
if USE_CUDA:
torch.cuda.manual_seed(2020) # 为当前GPU设置随机种子;
path = 'ChnSentiCorp_htl_8000.csv' # 训练集路径
data = pd.read_csv(path, encoding='gbk')
# print(data)
comments_list = pretreatment(list(data['review'].values))#对csv文件中review栏的内容做预处理
lenth = len(comments_list)
print('the length of data set is:',lenth)
print('the raw comments_list:',comments_list)
comments_list[:1]
print('after [:1] :',comments_list)
tokenizer = BertTokenizer.from_pretrained("bert_base_chinese")
comments_list_id = tokenizer(comments_list, padding=True, truncation=True, max_length=200, return_tensors='pt')
#分割数据集为测试集,验证集,训练集,按1.5:1.5:7
X = comments_list_id['input_ids']#x是评论内容
y = torch.from_numpy(data['label'].values).float()#y是label
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=True, stratify=y,
random_state=2020)
X_valid, X_test, y_valid, y_test = train_test_split(X_test, y_test, test_size=0.5, shuffle=True, stratify=y_test,
random_state=2020)
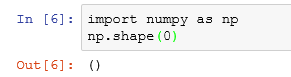
shape函数的作用:LINK
(1)参数是一个数时,返回空:
(2)参数是一维矩阵,返回第一维度的长度:
(3)参数是二维矩阵,返回第一维度和第二维度的长度:

#shape函数读取矩阵形状
X_train.shape
# print(X_train.shape)
y_train.shape
# print(y_train.shape)
# 为验证集,测试集,训练集创建 Tensor datasets
train_data = TensorDataset(X_train, y_train)
valid_data = TensorDataset(X_valid, y_valid)
test_data = TensorDataset(X_test, y_test)
# 每一次加载的数据量
batch_size = 5
# 构建验证集,测试集,训练集的加载器 make sure the SHUFFLE your training data
train_loader = DataLoader(train_data, shuffle=True, batch_size=batch_size, drop_last=True)
valid_loader = DataLoader(valid_data, shuffle=True, batch_size=batch_size, drop_last=True)
test_loader = DataLoader(test_data, shuffle=True, batch_size=batch_size, drop_last=True)
#print('valid_loader', valid_loader)
# 取训练集中的一个batch进行输出检查
dataiter = iter(train_loader)
sample_x, sample_y = dataiter.next()
print('Sample comment size: ', sample_x.size()) # batch_size, seq_length
print('Sample comment: \n', sample_x)# 真实评论内容
print()
print('Sample label size: ', sample_y.size()) # batch_size
print('Sample label: \n', sample_y)# 真实label
# 建立模型
if (USE_CUDA):
print('Training on GPU.')
else:
print('No GPU available, training on CPU.')
# 构造bert_lstm
output_size = 1
hidden_dim = 384 # 768/2
n_layers = 2
bidirectional = True # 这里为True,为双向LSTM
net = bert_lstm(hidden_dim, output_size, n_layers, bidirectional)
# 训练模型
# 学习率,损失函数,优化器
lr = 0.00001
criterion = nn.BCELoss()
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
# 模型训练的参数
epochs = 2
# 步长
print_every = 5
clip = 5 # 梯度剪裁,解决梯度爆炸问题
# 将模型从CPU放入GPU训练
if (USE_CUDA):
net.cuda()
net.train()# 模型训练前要使用train函数,测试前使用eval函数
# 使用划分出的训练集,按照设置的训练次数训练模型
for e in range(epochs):
# initialize hidden state
h = net.init_hidden(batch_size)
counter = 0
# 训练集根据batch值加载训练
for inputs, labels in train_loader:
counter += 1
if (USE_CUDA):
inputs, labels = inputs.cuda(), labels.cuda()
h = tuple([each.data for each in h])
# 删除不必要的加载代码,缓解内存溢出
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
# 把模型的参数梯度设成0
net.zero_grad()
output = net(inputs, h)
# print('label:')
# print(labels.long())
# print(labels.size)
# wang 这些是做测试用的 目的检验模型是否正常训练
'''
print('output', output) # wang
print('output_sigmoid', torch.sigmoid(output.squeeze())) # wang
print('labels', labels) # wang
print('train_max',torch.max(torch.sigmoid(output.squeeze()), 0)[1])
print('pred_max', torch.max(torch.nn.Softmax(dim=1)(output), 1)[1]) 使得在softmax操作之后在dim这个维度相加等于1
'''
'''
out_max = torch.sigmoid(output.squeeze()) #wang
print('out_before', out_max) #wang
out_max=torch.max(out_max) #wang
print('out_after', out_max.item()) #wang
'''
loss = criterion(torch.sigmoid(output.squeeze()), labels.float())
loss.backward()
nn.utils.clip_grad_norm_(net.parameters(), clip)
optimizer.step()
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
# 每一个步长,计算验证集损失
if counter % print_every == 0:
net.eval()
with torch.no_grad():
val_h = net.init_hidden(batch_size)
val_losses = []
for inputs, labels in valid_loader:# 验证集验证
val_h = tuple([each.data for each in val_h])
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
if (USE_CUDA):
inputs, labels = inputs.cuda(), labels.cuda()
output = net(inputs, val_h)
val_loss = criterion(torch.sigmoid(output.squeeze()), labels.float())
# print('loss:')
# print(val_loss)
val_losses.append(val_loss.item())
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
net.train()
print("Epoch: {}/{}...".format(e + 1, epochs),
"Step: {}...".format(counter),
"Loss: {:.6f}...".format(loss.item()),# 训练集的损失
"Val Loss: {:.6f}".format(np.mean(val_losses)))# 验证集的损失
# 测试
test_losses = [] # track loss
num_correct = 0
# init hidden state
h = net.init_hidden(batch_size)
net.eval()
# 计算测试集损失
for inputs, labels in test_loader:
h = tuple([each.data for each in h])
if (USE_CUDA):
inputs, labels = inputs.cuda(), labels.cuda()
output = net(inputs, h)
test_loss = criterion(torch.sigmoid(output.squeeze()), labels.float())
test_losses.append(test_loss.item())
output = torch.nn.Softmax(dim=1)(output)
prediction = torch.max(output, 1)[1]
# print('prediction_type',type(prediction)) #wang
# print('prediction_size', pred.size()) #wang
# compare predictions to true label
correct_tensor = prediction.eq(labels.long().view_as(prediction)) # 将label处理成和prediction相同的形状,即可以比较
correct = np.squeeze(correct_tensor.numpy()) if not USE_CUDA else np.squeeze(correct_tensor.cpu().numpy())# cpu中的tensor可以直接取出来,GPU中的tensor需要先放到CPU 也就是.cpu()那个方法 然后才能取出来
num_correct += np.sum(correct)# 计算正确预测的数量
print("Test loss: {:.3f}".format(np.mean(test_losses)))
# 计算测试集的准确率
test_acc = num_correct / len(test_loader.dataset)
print("Test accuracy: {:.3f}".format(test_acc))
# 测试
comment1 = ['exo私生饭尾随成员进宿舍,公司以后能不能加大监管力度?这都什么事情啊']
predict(net, comment1)
comment2 = ['同期最好的一部电影,真实不虚伪']
predict(net, comment2)
comment3 = ['有一说一,上晚班回来吃上一顿烧烤简直太幸福了']
predict(net, comment3)
comment4 = ['电影很值得,要二刷']
predict(net, comment4)
comment5 = ['警察暴力执法?黑人的命就不是命吗,这个世界还能继续恶臭吗']
predict(net, comment5)
comment6 = ['这家饭店的饭还不错,就是价格有点小高']
predict(net, comment6)
comment7 = ['有没有好心人愿意收养这只猫咪啊,很乖很漂亮的']
predict(net, comment7)
comment8 = ['娱乐圈的风气真的该严整一下了,偷税漏税的人一定不止一个']
predict(net, comment8)
# 模型保存
torch.save(net.state_dict(), './酒店评论二分类_parameters.pth')
output_size = 1
hidden_dim = 384 # 768/2
n_layers = 2
bidirectional = True # 这里为True,为双向LSTM
net = bert_lstm(hidden_dim, output_size, n_layers, bidirectional)
net.load_state_dict(torch.load('./酒店评论二分类_parameters.pth'))# 模型加载
# move model to GPU, if available
if (USE_CUDA):
net.cuda()
comment1 = ['日本要将核污水排入大海,命运共同体不是说着玩的,大多数人只看到了盈利的共同体,但是灾难大家也要一起承担啊!!']
predict(net, comment1)


















 1049
1049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











