







机器学习系列笔记十二: 决策树
文章目录
Intro
以招聘机器学习算法工程师为例子,对于一个应聘者的信息输入,决策的流程可以一个树结构来表示:
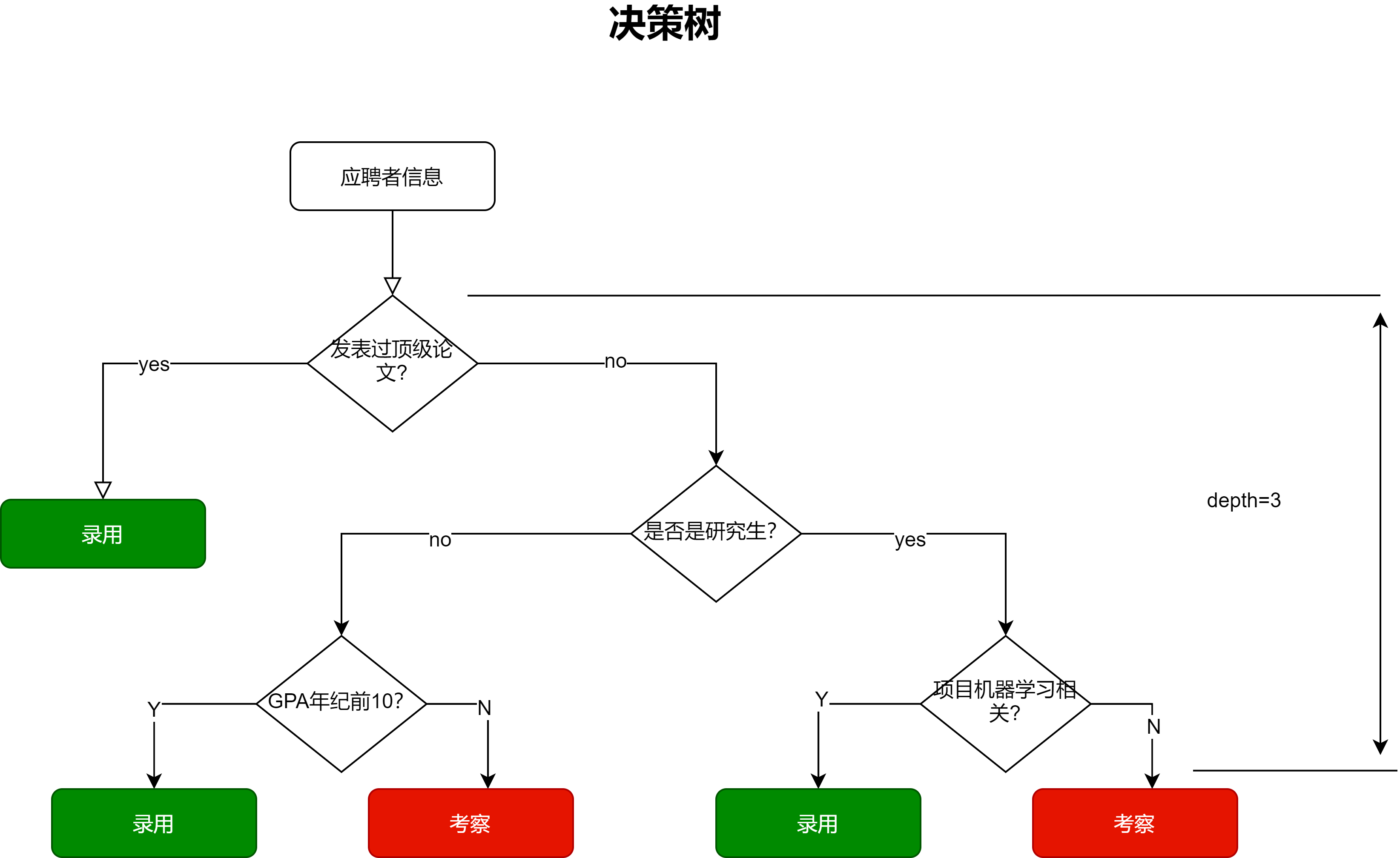
通过多级判断产生多个判断条件作为根节点,多个结果作为叶子节点,这样的过程就叫做决策树。通常我们把决策树的深度定义为获取最终结果的最大所需判断数。在上图中,最多通过三次判断就能将样本(应聘者信息)进行相应的分类,所以该决策树的深度为3.
以使用决策树对鸢尾花分类所得到的决策边界为例:
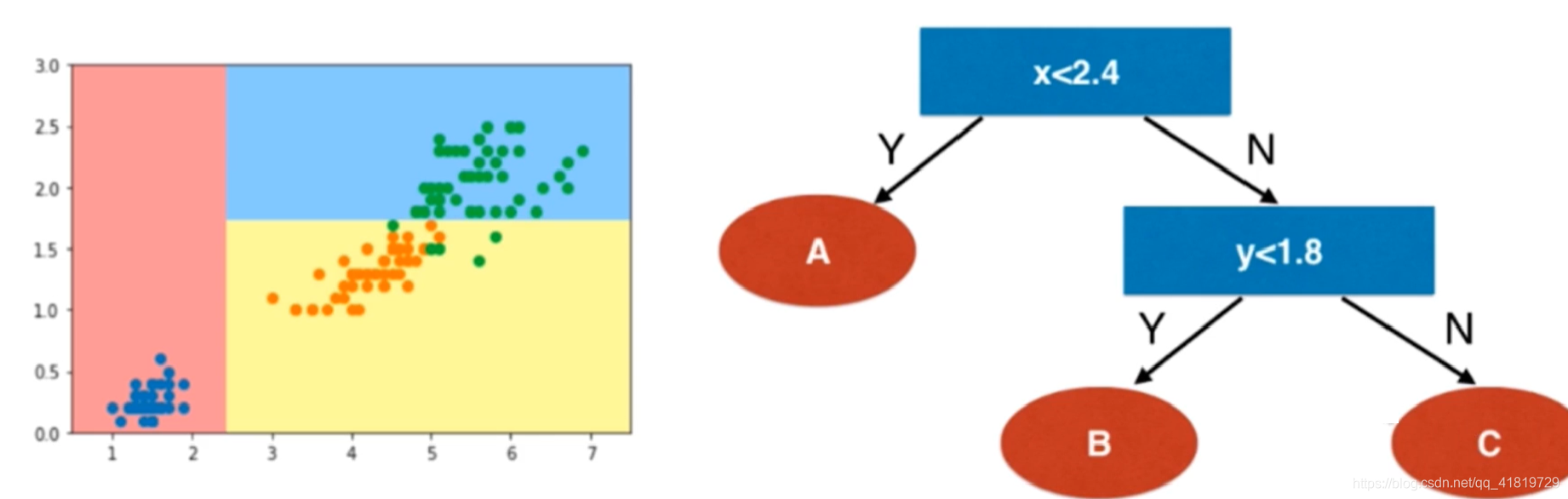
在每一个节点上选择每一个维度以及该维度相应的一个阈值,过程类似于OvR,每次都得出一个分类结果,最后得到所有分类结果。
什么是决策树
- 非参数学习算法
- 可以解决分类问题
- 天然可以解决多分类问题
- 也可以解决回归问题
- 非常好的可解释性
构建决策树的关键问题
根节点是判断条件:if var(左半部分) > val(右半部分)
-
每个根节点在哪个样本特征维度做划分,换言之各个根节点判断条件左半部分怎么设定
-
某个维度在哪个阈值上做划分,换言之判断条件的右半部分如何设定
信息熵
信息熵在信息论中表示随机变量不确定度的度量,在信息论中认为不确定性越低的信息包含的信息量(信息熵)越大。
- 熵越大,数据的不确定性越高
- 熵越小,数据的不确定性越低
熵的计算公式如下:
H = − ∑ i = 1 k p i l o g ( p i ) H=-\sum^k_{i=1}p_ilog(p_i) H=−i=1∑kpilog(pi)
对于只有p1–>A类,p2–>B类,该函数的图像如下:
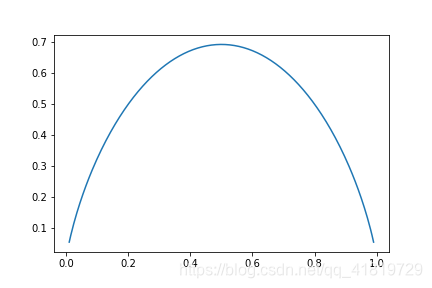
可以看到,当样本是A类或B类相等=0.5时,此时该样本的不确定性最大,信息熵也为最大。
通过对信息熵的使用,可以解决构建决策树的关键问题:对所有的可能划分进行搜索,找到一个最好的划分,使得划分后信息熵最小。
使用信息熵寻找最优划分
使用scikit learn的决策树分类算法
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
import warnings
warnings.filterwarnings("ignore")
iris = datasets.load_iris()
X = iris.data[:,2:]
y = iris.target
# 使用决策树分类器
dt_clf = DecisionTreeClassifier(max_depth=2,criterion="entropy")
dt_clf.fit(X,y)
DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=2,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False,
random_state=None, splitter='best')
绘制决策边界
def plot_decision_boundary(model,axis):
x0,x1 = np.meshgrid(
np.linspace(axis[0],axis[1],int((axis[1]-axis[0])*100)).reshape(-1,1),
np.linspace(axis[2],axis[3],int((axis[3]-axis[2])*100)).reshape(-1,1),
)
X_new = np.c_[x0.ravel(),x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0,x1,zz,linewidth=5,cmap=custom_cmap)
plot_decision_boundary(dt_clf,axis=[0.5,7.5,0,3])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.scatter(X[y==2,0],X[y==2,1])
plt.show()
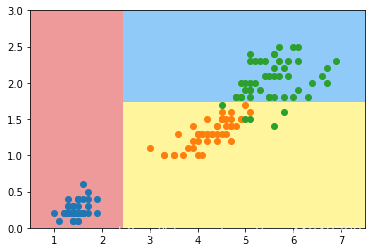
模拟使用信息熵进行划分
from collections import Counter
from math import log
def entropy(y):
counter=Counter(y)
res = 0.0
for num in counter.values():
p = num / len(y)
res += -p * log(p)
return res
def split(X,y,d,value):
"""基于维度d与阈值value进行划分"""
index_a = (X[:,d]<=value)
index_b = (X[:,d]>value)
return X[index_a],X[index_b],y[index_a],y[index_b]
def try_split(X,y):
"""寻找最佳划分"""
best_entropy = float("inf")
best_d,best_v = -1,-1
for d in range(X.shape[1]):
# 可选的阈值是维度d下每两个特征的均值
sorted_index = np.argsort(X[:,d])
for i in range(1,len(X)):
if X[sorted_index[i-1],d]!=X[sorted_index[i],d]:
v = (X[sorted_index[i-1],d]+X[sorted_index[i],d])/2
x_L,x_r,y_L,y_r=split(X,y,d,v)
e = entropy(y_L)+entropy(y_r)
if e < best_entropy:
best_entropy,best_d,best_v=e,d,v
return best_entropy,best_d,best_v
best_entropy,best_d,best_v = try_split(X,y)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









