







 本文详细介绍了如何使用scikit-learn的PCA进行主成分分析,包括基本使用、进阶操作如设置合理的n_components、数据降噪处理及PCA在MNIST数据集上的应用。通过实例展示了PCA在降低模型训练时间、数据可视化和去除噪声方面的优势。
本文详细介绍了如何使用scikit-learn的PCA进行主成分分析,包括基本使用、进阶操作如设置合理的n_components、数据降噪处理及PCA在MNIST数据集上的应用。通过实例展示了PCA在降低模型训练时间、数据可视化和去除噪声方面的优势。
机器学习系列笔记六:主成分分析PCA[下]
文章目录
在上一节,我们自定义实现了PCA主成分分析法,并通过多个测试验证了算法的有效性,当然与scikit-learn或其他机器学习框架封装的PCA算法相比差的很远,但也足以让我们理解PCA的原理。
在这一节,我们就利用scikit-learn框架中所提供的PCA来进行一系列的练习。学习利用框架所提供的工具来是实现主成分分析,并能用于实际的需求。
scikit-learn中的PCA
基本使用
准备数据
import numpy as np
import matplotlib.pyplot as plt
X = np.empty((100,2))
X[:,0] = np.random.uniform(0,100,size=100)
X[:,1] = 0.75 * X[:,0] + 3 + np.random.normal(0,10,size=100)
首先需要从sklearn.decomposition包中导入PCA工具类
from sklearn.decomposition import PCA
其实上一节中PCA的实现是参照着scikit-learn来的,所以使用起来和之前的代码差别不大
pca = PCA(n_components=1)
pca.fit(X)
PCA(copy=True, iterated_power='auto', n_components=1, random_state=None,
svd_solver='auto', tol=0.0, whiten=False)
pca.components_ #求解的n_components个主成分
array([[-0.78373823, -0.62109128]])
transform:根据求解的主成分对数据进行降维
X_reduction = pca.transform(X)
X_reduction.shape
(100, 1)
inverse_transform:根据求解的主成分将降维后的数据恢复为高维状态
X_restore = pca.inverse_transform(X_reduction)
X_restore.shape
(100, 2)
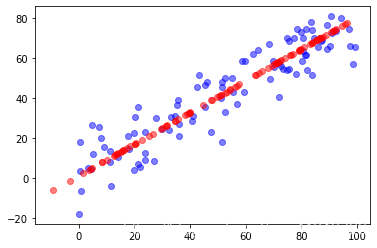
对比恢复后的数据与原始数据
plt.scatter(X[:,0],X[:,1],color="b",alpha=0.5)
plt.scatter(X_restore[:,0],X_restore[:,1],color="r",alpha=0.5)
plt.show()
进阶操作
对比实验
导入真实数据集
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
# 导入手写数据集
digits = datasets.load_digits()
X = digits.data
y = digits.target
分割数据集为测试/训练组
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=666)
X_train.shape
(1347, 64)
- 对原始数据进行训练(KNN算法),看看识别率为多少
%%time
from sklearn.neighbors import KNeighborsClassifier
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train,y_train)
Wall time: 32.7 ms
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=5, p=2,
weights='uniform')
knn_clf.score(X_test,y_test)
0.9866666666666667
可以看到对原始数据不作PCA处理,所耗费的训练时间为17.9 ms,模型识别精度为0.9866666666666667
- 对原始数据进行PCA降维处理,看看识别率为多少
通过PCA.transform()将原始数据降维到2维
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca.fit(X_train)
X_train_reduction = pca.transform(X_train)
X_test_reduction = pca.transform(X_test)
使用同样的KNN算法训练处理后的数据
%%time
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train_reduction,y_train)
Wall time: 1.49 ms
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=5, p=2,
weights='uniform')
knn_clf.score(X_test_reduction,y_test)
0.6066666666666667
可以看到对于通过PCA处理后的数据,KNN模型训练所耗费的训练时间为1.49 ms,将近比利用原始数据训练快了15倍!!!
然而模型识别精度为0.6066666666666667,效果显然不如使用原始数据好,因为在降维过程中丢失了大量的细节特征。
设置合理的n_components
- 通过PCA.explained_variance_ratio_可以查看计算出的主成分轴分别解释原数据的百分比(保留的信息量)
pca.explained_variance_ratio_
array([0.14566817, 0.13735469])
pca = PCA(n_components=X_train.shape[1])
pca.fit(X_train)
pca.explained_variance_ratio_
array([1.45668166e-01, 1.37354688e-01, 1.17777287e-01, 8.49968861e-02,
5.86018996e-02, 5.11542945e-02, 4.26605279e-02, 3.60119663e-02,
3.41105814e-02, 3.05407804e-02, 2.42337671e-02, 2.28700570e-02,
1.80304649e-02, 1.79346003e-02, 1.45798298e-02, 1.42044841e-02,
1.29961033e-02, 1.26617002e-02, 1.01728635e-02, 9.09314698e-03,
8.85220461e-03, 7.73828332e-03, 7.60516219e-03, 7.11864860e- 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









