






 这篇博客探讨了一个强化学习中的路径选择问题,从起点s出发,通过概率分布到达a和b点,最终目标是g点。每条路径有不同的回报和概率。状态价值函数v(s)计算了所有可能轨迹的期望回报,而动作价值函数Q(s,a)考虑了动作带来的即时回报加上后续状态的价值。博客还介绍了如何根据这些函数更新策略,以最大化期望回报。
这篇博客探讨了一个强化学习中的路径选择问题,从起点s出发,通过概率分布到达a和b点,最终目标是g点。每条路径有不同的回报和概率。状态价值函数v(s)计算了所有可能轨迹的期望回报,而动作价值函数Q(s,a)考虑了动作带来的即时回报加上后续状态的价值。博客还介绍了如何根据这些函数更新策略,以最大化期望回报。
考虑这样的一个选路径问题
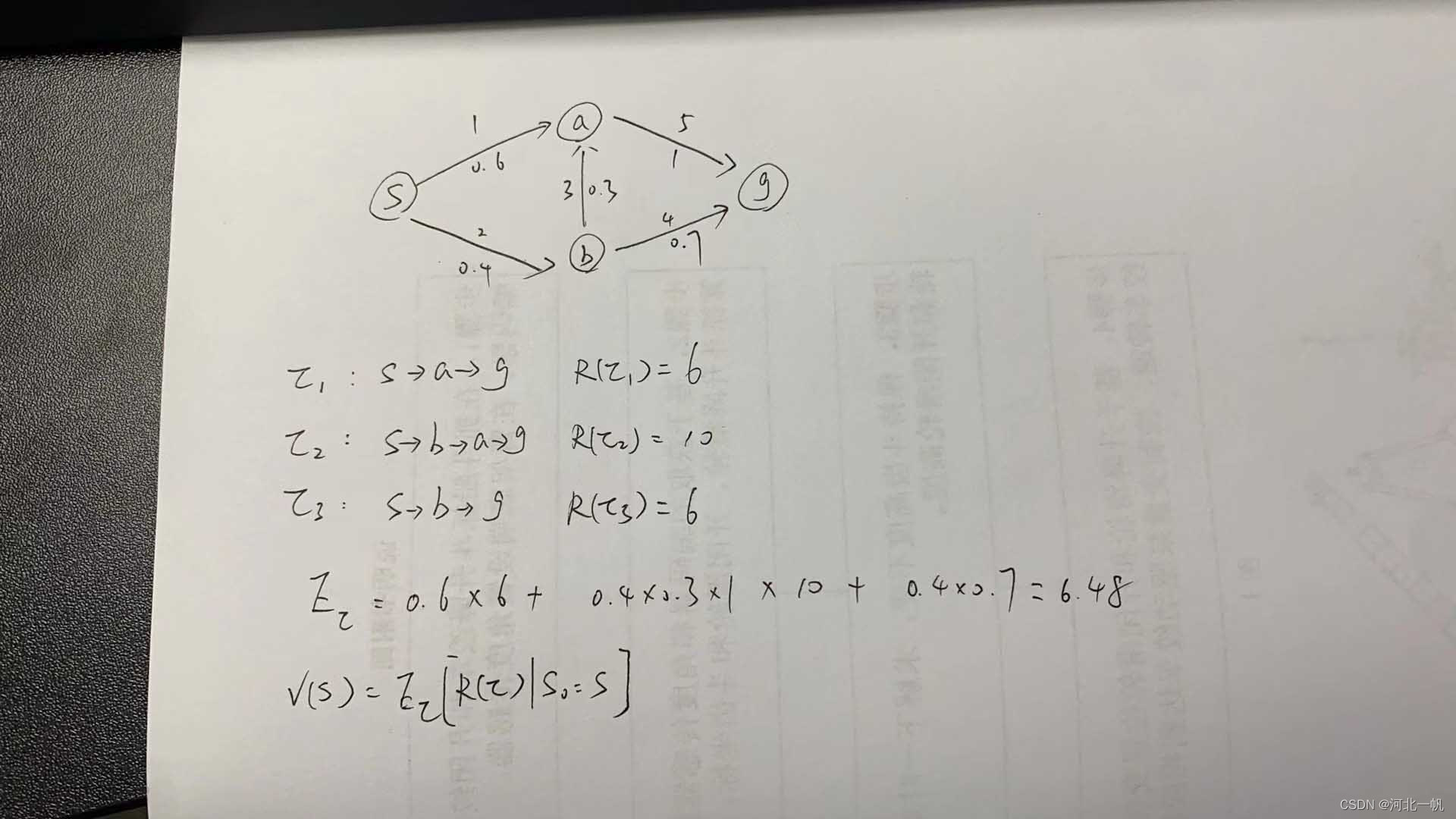
从s点出发,有0.6的概率到a点,0.4的概率到b点,sa路径的回报是1,sb路径的回报是2,后面同理,箭头下面的选择这条路的概率,上面的数字是这条路的回报。目的地是g点。
从s到g一共有3中方式,这三种方式,即在策略下(策略指的就是不同动作的概率,强化学习过程就是让能获得更大奖励的动作的概率增大)的三个轨迹,这三个轨迹的回报分别是6、10、6。
轨迹的回报期望即0.6*6+0.4*0.3*10+0.4*0.7*6=6.48(图片里漏了个6),即为状态s的价值函数v(s)。
同理v(a)=5、v(b)=5.2
状态价值函数的表达式为
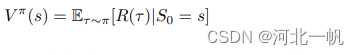
状态s可以采取两个动作,动作a1往a走,动作a2往b走,
动作价值函数Q(s, a1) = 选择该动作得到的回报 + 该动作到达的下一个状态的状态价值函数
即Q(s, a1)=1+v(a)=6 Q(s, a2)=2+v(b)=7.2
s的价值函数与a1、a2两个动作的动作价值函数的关系如下:
状态价值函数 = 动作1概率 * 动作1的动作价值函数 + 动作2概率 * 动作2的动作价值函数 + 动作i概率 * 动作i的动作价值函数
v(s) = 0.6 * 6 + 0.4 * 7.2 = 6.48

















 1627
1627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









