







- Dataset转为DataFrame
必须要导入隐式转换否则会报错(隐式转换在我上一篇中有讲到)
第一种情况:若数据字段不多的话可以直接利用toDF()可以直接转换为DataFrame,如下:
import spark.implicits._
val ds: Dataset[String] = spark.read.textFile("hdfs://192.192.192.24/tmp/tb_order/")
ds.map(x => x.split("\\|")).map(x => (x(0),x(1),x(2),x(3),x(4))).toDF("aa","ss","dd","rr","hh").show()
结果如下:
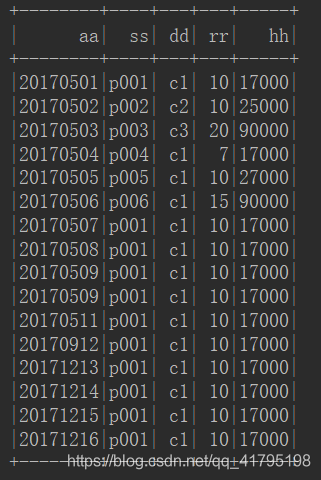
第二种情况,如果你的数据字段较多的情况下,可以使用样例类的方法(因为在元组中字段最多只能有22个,超过22个就不能使用上面的方法)进行转换,如下,我这个有60个字段:
import spark.implicits._
val ds_ls: Dataset[String] = spark.read.textFile("hdfs://192.192.192.24/inceptor1/user/hive/warehouse/ods.db/hive/mz_rkk_ls/")
//将ds_ls转换为dataframe
val frame_ls: DataFrame = ds_ls.map(x => x.split("\\|")).map(x => mz_rkk_ls(x(0), x(1), x(2), x(3), x(4), x(5), x(6), x(7), x(8), x(9), x(10), x(11), x(12), x(13), x(14), x(15), x(16), x(17), x(18), x(19 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 551
551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









