



 本文介绍了如何在Spark中实现RDD到DataFrame和DataSet,以及DataFrame到RDD和DS的转换过程,并通过实例展示了每一步操作。理解这些转换有助于提升数据处理效率和结构化数据管理。
本文介绍了如何在Spark中实现RDD到DataFrame和DataSet,以及DataFrame到RDD和DS的转换过程,并通过实例展示了每一步操作。理解这些转换有助于提升数据处理效率和结构化数据管理。
RDD,DataFrame与DataSet的相互转换
DataFrame相当于在RDD的基础上添加了结构,DataSet相当于在DataFrame的基础上添加了类型
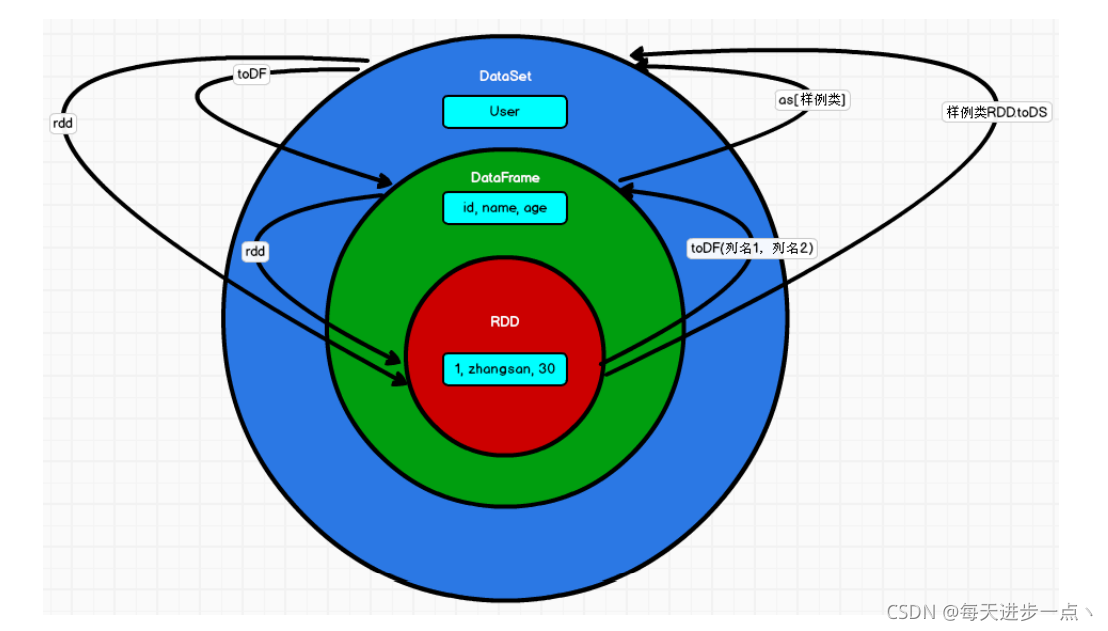
1 rdd->DF,DS
// 创建rdd
scala> val rdd = sc.makeRDD(List(("zhangsan",18)))
rdd: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[23] at makeRDD at <console>:28
scala> rdd.collect().foreach(println)
(zhangsan,18)
// rdd->df rdd.toDF(列名1,列名2,...)
scala> val df = rdd.toDF("name","age")
df: org.apache.spark.sql.DataFrame = [name: string, age: int]
// 打印输出
scala> df.show
+--------+---+
| name|age|
+--------+---+
|zhangsan| 18|
+--------+---+
// rdd->ds 样例类RDD.toDS()
// 创建样例类
case class User(name: String, age: Int)
scala> val rdd1 = rdd.map(data=>User(data._1,data._2))
rdd1: org.apache.spark.rdd.RDD[User] = MapPartitionsRDD[27] at map at <console>:31
scala> val ds = rdd1.toDS()
ds: org.apache.spark.sql.Dataset[User] = [name: string, age: int]
scala> ds.show
+--------+---+
| name|age|
+--------+---+
|zhangsan| 18|
+--------+---+
2 DF->RDD,DS
// df -> RDD df.rdd
scala> val dfToRDD = df.rdd
dfToRDD: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[35] at rdd at <console>:29
scala> dfToRDD.collect().foreach(println)
[zhangsan,18]
// df -> ds ds.as[样例类]
scala> val dfTods = df.as[User]
dfTods: org.apache.spark.sql.Dataset[User] = [name: string, age: int]
scala> dfTods.show
+--------+---+
| name|age|
+--------+---+
|zhangsan| 18|
+--------+---+
3 DS->RDD,DF
// ds -> RDD ds.rdd
scala> val dsToRDD = ds.rdd
dsToRDD: org.apache.spark.rdd.RDD[User] = MapPartitionsRDD[44] at rdd at <console>:29
scala> dsToRDD.collect().foreach(println)
User(zhangsan,18)
// ds -> df ds.toDF
scala> val dsTodf = ds.toDF
dsTodf: org.apache.spark.sql.DataFrame = [name: string, age: int]
scala> dsTodf.show
+--------+---+
| name|age|
+--------+---+
|zhangsan| 18|
+--------+---+


















 706
706

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











