




今天讲一下spark的基本概念:
想要了解spark,首先要了解sparkRDD(弹性分布式数据集)。spark应用程序通过使用spark的转换API可以将RDD封装为一系列具有血缘关系的RDD,也就是DAG。只有通过spark的动作API才会将RDD及其DAG提交到DAGScheduler。RDD负责从数据源迭代读取数据。这样讲可能有点不太明白,就好比RDD是一个装载数据得容器,我们从数据源读取到数据然后放入到RDD中,进行一系列得Transformation算子和Action算子得操作之后,然后RDD再把数据放到指定得数据存储地方。
DAG:有向无环图。这里先简单提一下吧,就是spark使用DAG来反映各RDD之间得依赖关系
Partition:数据分区。就是一个RDD得数据可以划分为多少个分区。spark根据Partition得数量来确定Task得数量
窄依赖:其实就是子RDD和RDD父RDD在父RDD得数据分区内执行。就是没有产生shuffle过程,例如map,filter,union等操作会产生窄依赖
宽依赖:也就是产生shuffle,子RDD对父RDD中得所有数据分区都可能参数依赖。例如,reduceByKey,groupByKey之类的算子
job:用户提交得作业,当RDD和DAG被提交给DAGScheduler调度后,DAGScheduler会将所有RDD中得转换及动作视为一个Job。一个Job由一个到多个Task组成
stage:job得执行阶段。DAGSheduler按照ShuffleDependency作为Stage得划分节点对RDD得DAG进行Stage划分。因此一个job可能被划分为一到多个stage。stage分为shuffleMapStage和ResultStage两种。
Task:具体执行任务,数据到这里就是执行方面了,一个job作业在每一个stage内都会按照RDD得Partition数量,创建多个Task。Task分为ShuffleMapTask和ResultTask两种。ShuffleMapStage中的Task为ShuffleMapTask,而ResultStage中得Task为ResultTask。ShuffleMapTask和ResultTask类似于Hadoop中得Map任务个Reduce任务
整个任务提交的过程如下图:
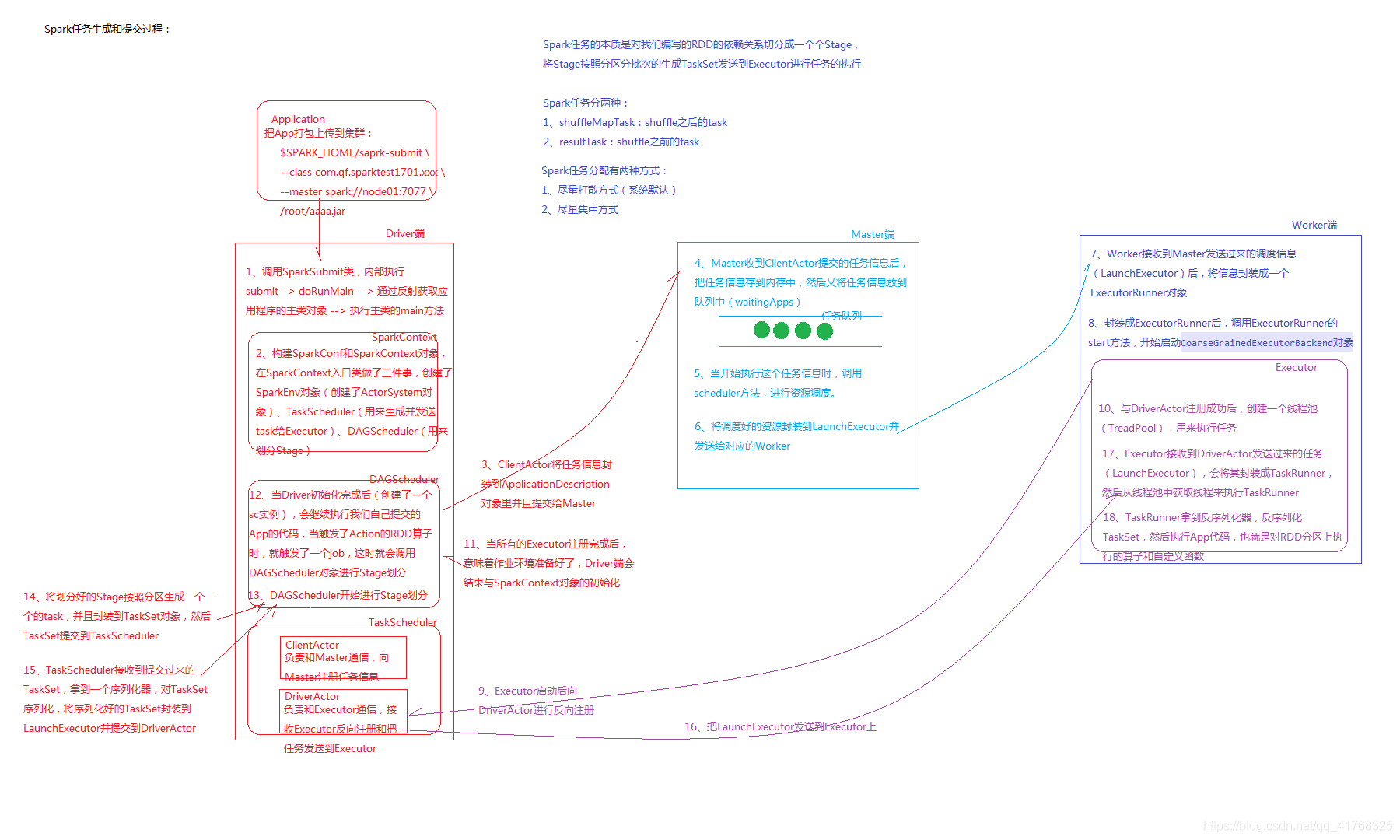
我们用spark处理数据其实就是处理RDD,了解好RDD就可以在开发得时候尽量避免人为的数据偏移。
然后我们再说一下spark核心组件:
spark框架继承了多个组件,位于底层得spark core ,其实现了spark得作业调度,内存管理,与存储系统交互等基本功能,并针对弹性分布式数据集(RDD)提供了丰富的操作。在Spark Core的基础上,spark提供了一系列面向不同应用需求的组件,我们对于大数据的开发会用到两个,sparkSql(离线),sparkStreaming(接近实时),还有两个机器学习的,MLlib,Graphx
在spark2.0之前sprkStreaming是一个接近于实时的流式计算,但是在spark2.0发布之后,也就是2.1版本的时候,据说流式计算可以处理间隙为毫秒级,这样就是更接近于实时计算.
Sparksql是用来操作结构话数据的组件。通过sparksql,用户可以使用sql语句来查询数据,sparksql支持多种数据源类型,不仅提供了,sql接口,而且,还将sql语句融入到了spark应用程序开发过程中.


















 1039
1039

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











