




 本文深入探讨Spark中的DataFrame概念,解析其存储方式与优势,对比Hadoop的MapReduce,强调Scala与Spark在大数据处理中的高效结合。介绍Dataset与DataFrame的特性及应用,以及schema在数据描述中的作用。
本文深入探讨Spark中的DataFrame概念,解析其存储方式与优势,对比Hadoop的MapReduce,强调Scala与Spark在大数据处理中的高效结合。介绍Dataset与DataFrame的特性及应用,以及schema在数据描述中的作用。
这次是随手开始写的笔记,在spark大数据开发中数据不会是规整的出现,大多都是有瑕疵的,比如null值,等等。那么在spark数据是已DataFram的形式存储的,而DataFram是以列的形式存储(element),为什么是列存储,这也是方便我们在日后进行计算,这也是为什么Scala与spark会经常同时出现处理大数据的原因,在大数据处理了的时候,Scala语言提供高效精简的语法,而spark有效的利用他自身的内存式计算和丰富的算子,大大的提升了计算速度。
相对于Hadoop的MR,是有map和reduce两部分组成,而且在map阶段结束的时候,会有一个步是在往本地磁盘写入的一个过程,然后reduce是从本地磁盘读取数据,在进行计算的过程,这样就非常的浪费时间,这里先简单的说了一下MR,在mr中还有shuffle和combin过程,这里今天就不讲了,因为重点是在spark的datafram上面
数据集(Dataset)是分布式数据集合。Dataset是spark1.6中添加的一个新接口,它提供了RDD的优势以及sparksql优化执行引擎的优点。数据集可以被构造从jvm对象,然后使用功能性的转换(map,flatmap,filter等等)。数据集Api在Scala和Java中可用,python没有对DATASET api的支持。
数据框架(DataFrame)是组织命名列的数据集。它在概念上等同于关系数据库中的表,但在引擎下具有更丰富的优化,dataframe可以从多种源构建,例如:结构化数据文件,hive中的表,外部数据库或现有RDD。DataFrame API在Scala,Java,中可用。在Scala和Java中,DataFrame由rows的数据集表示。在Scala中,DataFrame它只是一个类型别名Dataset【row】。而在Java API中,用户需要使用Dataset<row>来表示DataFrame。
其实从上面得话中,大家都应该对DataFrame有了一点概念,DataFrame以列为存储格式,那么就有了schema(数据结构类型),这个时候可能又有人懵了,什么是数据结构类型,这是一个很模糊得一个概念,实际上,schema就是描述数据得一个集合,包含了表,视图,索引,等等。如果把DataFrame看作一个创库,那么schema就是一个个得房间,一个schema代表一个房间,table是房间中得存储柜。*:其实就是描述数据得数据信息
为了能让大家能更加直观得看到schema长什么样子,我从网上截取一段图片给大家看一下:
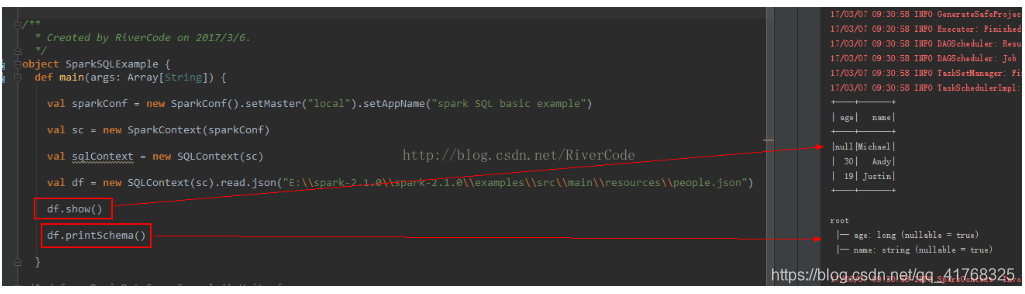
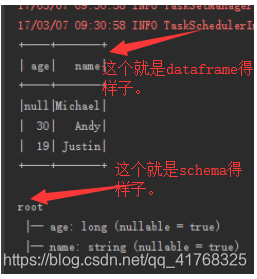
(其实很多刚开始接触spark大数据开发的时候只是停留在spark得大数据计算引擎上面。确实,spark得内存式计算引擎非常得快,关键还是spark得数据结构,和他自身得RDD算子可以让spark更快得计算海量得数据。)
大家看到这两张图的时候,心里应该就明白了是什么意思了。其实讲到这里就有点深入了,但也只是介绍了非常基础得概念,如果想要做spark大数据开发,了解dataframe是非常重要的一件事,对日后得开发有很大得帮助,如果大家想要知道更多关于dataframe得东西,可以去官网,或者其他得博客查看,更深入得知识,当然,我也会在日后将spark得开发经验,和技术分享到这上面来。


















 425
425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











