







 谷歌研究人员提出了BlazeFace,一个专为移动端设计的轻量级人脸检测模型。通过改造mobileNet,使用5x5深度可分离卷积和GPU友好的锚框机制,BlazeFace在保持高性能的同时实现了超高速运行。与MobileNetSSD相比,它在正脸检测任务中表现更优,速度接近两倍。检测回归器的设计简化为两个尺度,减少了计算负担并提升了速度。BlazeFace的源代码可在GitHub上找到。
谷歌研究人员提出了BlazeFace,一个专为移动端设计的轻量级人脸检测模型。通过改造mobileNet,使用5x5深度可分离卷积和GPU友好的锚框机制,BlazeFace在保持高性能的同时实现了超高速运行。与MobileNetSSD相比,它在正脸检测任务中表现更优,速度接近两倍。检测回归器的设计简化为两个尺度,减少了计算负担并提升了速度。BlazeFace的源代码可在GitHub上找到。
Introduction
来自谷歌的研究人员通过改造mobileNet提出更为紧凑的轻量级特征提取方法、结合适用于移动端GPU高效运行的新型锚框机制,以及代替非极大值抑制的加权方法保证检测结果的稳定性,在移动端上实现了超高速的高性能人脸检测BlazeFace.
一个轻量级特征提取网络
- 128 x 128 RGB input
- 2D convolution. 5 single, and 6 double BlazeBlocks
- Highest channel resolution is 96
- Lowest spatial resolution is 8 x 8(would be 1 x 1 SSD)
GPU友好型anchor方案
- Anchor scheme stops at 8 x 8(避免更深的下采样)
- 6 anchors per pixel at that resolution
- Only 1 : 1 aspect ratio
骨干网络的设计
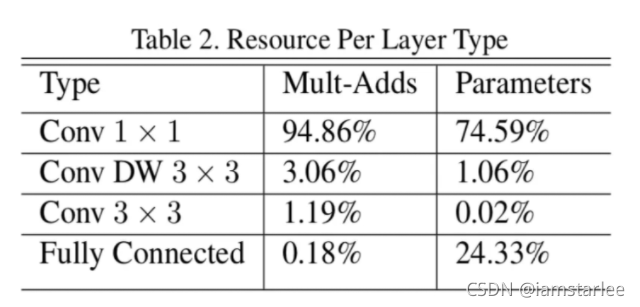
研究人员发现,逐点计算1 x 1卷积对于计算资源的占比比使用k x k(k != 1)卷积核的要高。针对实际的iPhone X手机,其中基于Metal Performance Shader实现的3 x 3卷积,针对56 x 56 x 128大小的16比特浮点张量操作需要0.07ms,而使用1 x 1卷积对128通道到128通道的操作则需要耗时0.3ms,几乎是前者的四倍多。
这样的结果为研究人员指明了提高效率的方向,增加深度可分离卷积操作中第一步核的大小是相对高效的选择。所以在BlazeFace中研究人员将卷积核的大小扩大成了5 x 5。卷积核的增大在bottleneck总量减小的情况下保证了模型感受野的大小。
由于增大了卷积核后的Blaze单元的开销很小,使得另一个层的加入成为可能。于是研究人员又在上面模块的基础上开发出了双份的Blaze单元。不仅增加了感受野的大小,同时也提高了特征的抽象。使用5 x 5 的深度可分离卷积能达到 Same accuracy with fewer layers 的效果。
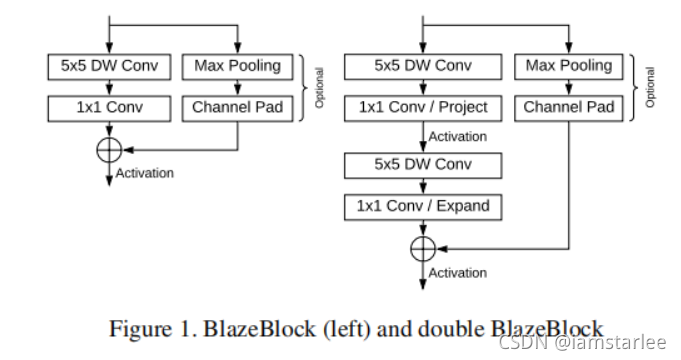
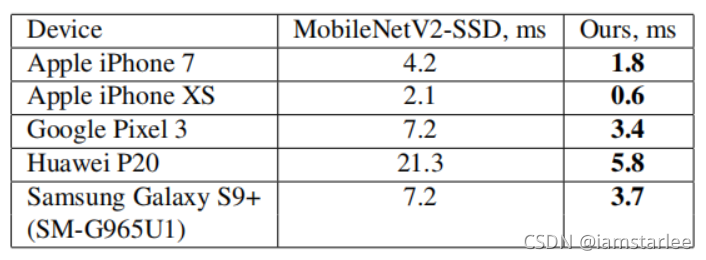
仔细观察上图可以发现,在第一个single blaze的输出为24,而在第二个single blaze的输出为96。相比较于MobileNet动辄256、512、1024的1x1卷积核输出通道数,作者仅仅用了一个24和一个96的1x1卷积核就完成了操作。并且在相同的模型层数下,BlazeFace的网络大小要小于MobileNet很多,速度也快很多。从下图作者的实验中可以看出,在正脸检测的任务中略优于MobileNet SSD,同时速度几乎是其两倍!
检测回归器的设计
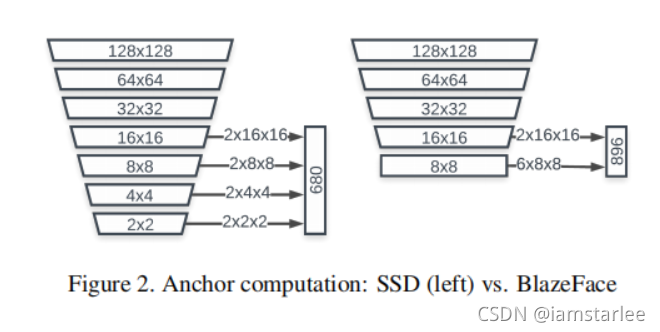
检测回归器的设计,作者主要还是参考了SSD的工作。由于该算法主要需处理的任务为正脸的检测,其anchor在大多数的情况下,使用比例为1.0的anchor即可以得到很好的效果。相比于传统的SSD通过级联6个尺度下的特征(本文作者实现的MSSD级联了4个尺度下的特征),BlazeFace仅仅级联了2个尺度的特征进行人脸检测,且在16x16特征下每个点仅采用2个anchor,在8x8特征下每个点采用6个anchor,在数据分布不复杂的情况下,既能解决问题,又可以提升网络推理的速度,一举两得。
效果
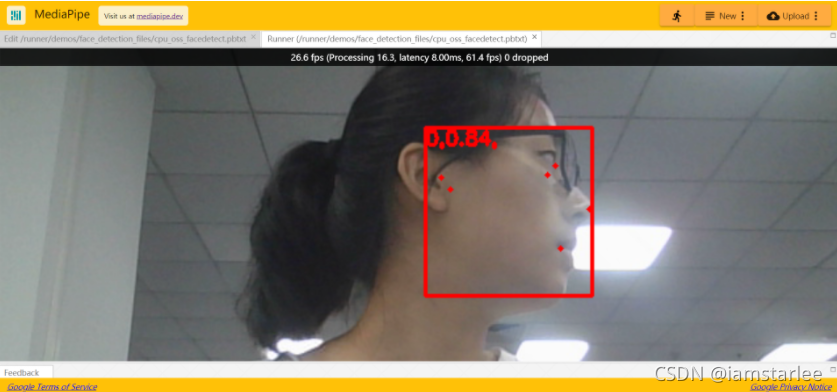
代码
见GitHub:https://github.com/hollance/BlazeFace-PyTorch




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











