







 本文深入探讨了SQL中的视图、子查询和函数谓词,包括视图的创建与使用,子查询的分类及应用,以及函数谓词如CASE表达式的细节。通过实例解析,展示了如何利用视图提高查询效率,理解子查询的嵌套与关联,以及如何运用函数进行数据处理和条件判断。同时,文章也提及了集合运算的基本操作,如并集、交集和差集,以及联结的不同类型,如内联结和外联结。
本文深入探讨了SQL中的视图、子查询和函数谓词,包括视图的创建与使用,子查询的分类及应用,以及函数谓词如CASE表达式的细节。通过实例解析,展示了如何利用视图提高查询效率,理解子查询的嵌套与关联,以及如何运用函数进行数据处理和条件判断。同时,文章也提及了集合运算的基本操作,如并集、交集和差集,以及联结的不同类型,如内联结和外联结。
文章目录
第五章
5.1 视图
- 概念:从SQL的角度来看,视图和表是相同的,两者的区别在于表中保存的是实
际的数据,而视图中保存的是SELECT语句(视图本身并不存储数据)。 - 优点
- 第一,由于视图并不存储数据,因此可以
节省存储空间 - 第二,可以进行
调用select语句,避免重复书写。可以将频繁使用的 SELECT 语句保存成视图,这样就不用每次都重新书写了。创建好视图之后,只需在 SELECT 语句中进行调用,就可以方便地得到想要的结果了。特别是在进行汇总以及复杂的查询条件导致 SELECT 语句非常庞大时,使用视图可以大大提高效率。而且,视图中的数据会随着原表的变化自动更新。视图归根到底就是SELECT 语句,所谓“参照视图”也就是“执行SELECT 语句”的意思,因此可以保证数据的最新状态。这也是将数据保存在表中所不具备的优势
- 第一,由于视图并不存储数据,因此可以
- 视图语法格式:创建视图
create View...as select...,一定要注意不能省略as,这里的as和创建表时数据列的别名不同,可以as select组合短语来记忆
CREATE VIEW 视图名称(<视图列名1>, <视图列名2>, ……)
AS
<SELECT语句>
CREATE VIEW ProductSum (product_type, cnt_product)
AS
SELECT product_type, COUNT(*)
FROM Product
GROUP BY product_type;
- 使用视图的步骤,
使用视图的查询通常需要执行 2 条以上的 SELECT 语句- 首先执行定义视图的 SELECT 语句
- 根据得到的结果,再执行在 FROM 子句中使用视图的 SELECT 语句
- 注意事项:
避免使用order by 语句。这是因为视图和表一样, 数据行都是没有顺序的- 应该
避免在视图基础上创建多重视图 - 尽量
避免对视图的更新,因为在使用聚合函数的视图中,更新视图之后原表没有办法更新,因此更新视图的命令会报错,一般来说,更新应该出现在原表中,这样的话原表和视图才能一起进行更新。
- 删除视图:
DROP VIEW 视图名称(<视图列名1>, <视图列名2>, ……)
在PostgreSQL中,如果删除以视图为基础创建出来的多重视图,由于存在关联的
视图,因此会发生错误。可在语句最后加入CASCADE选项来删除关联视图。
5.2 子查询
- 概念:子查询就是一张
一次性视图。子查询就是将用来定义视图的SELECT语句直接用于FROM子句当中
-- 在FROM子句中直接书写定义视图的SELECT语句
SELECT product_type, cnt_product
FROM ( SELECT product_type, COUNT(*) AS cnt_product
FROM Product
GROUP BY product_type ) AS ProductSum;-
- 该 SELECT 语句包含
嵌套的结构,首先会执行 FROM 子句中的 SELECT 语句,然后才会执行外层的 SELECT 语句。子查询中的语句会首先执行 - 标量子查询:标量子查询就是返回
单一值的子查询。 - 在where子句中,由于where中不能使用聚合函数,因此可以尝试采用标量子查询
SELECT product_id, product_name, sale_price
FROM Product
WHERE sale_price > (SELECT AVG(sale_price)
FROM Product);
- 标量子查询的书写位置:标量子查询的书写位置并不仅仅局限于 WHERE 子句中,通常
任何可以使用单一值的位置都可以使用。也就是说, 能够使用常数或者列名的地方,无论是 SELECT 子句、 GROUP BY 子句、 HAVING 子句,还是ORDER BY 子句,几乎所有的地方都可以使用。
/*在select子句中使用标量子查询*/
SELECT product_id,
product_name,
sale_price,
(SELECT AVG(sale_price)
FROM Product) AS avg_price
FROM Product;
/*在having子句中使用标量子查询*/
SELECT product_type, AVG(sale_price)
FROM Product
GROUP BY product_type
HAVING AVG(sale_price) > (SELECT AVG(sale_price)
FROM Product);
- 注意事项:标量子查询
绝对不能返回多行结果。也就是说,如果子查询返回了多行结果,那么它就不再是标量子查询,而仅仅是一个普通的子查询了,因此不能被用在 = 或者 <> 等需要单一输入值的运算符当中,也不能用在 SELECT等子句当中
5.3 关联子查询
- 基本概念:关联子查询就是在
子查询中添加 WHERE 子句的条件 - 应用场景:选取出
各商品种类中高于该商品种类的平均销售单价的商品。即在细分的组内进行比较时,需要使用关联子查询。 - 当比较对象的是同一张表时,为了进行区别,在使用关联子查询时,需要在表所对应的列名之前加上表的别名,以“
< 表名 >.< 列名 >”的形式记述
SELECT product_type, product_name, sale_price
FROM Product AS P1
WHERE sale_price > (SELECT AVG(sale_price)
FROM Product AS P2
WHERE P1.product_type = P2.product_type
GROUP BY product_type);
关联名称具有一定的有效范围。如下面代码所述, SQL是按照先内层子查询后外层查询的顺序来执行的。这样,子查询执行结束时只会留下执行结果,作为抽出源的 P2 表其实已经不存在了。
SELECT product_type, product_name, sale_price
FROM Product AS P1
WHERE P1.product_type = P2.product_type
/*这一个where 子句不应该从子查询中拿出来*/
AND sale_price > (SELECT AVG(sale_price)
FROM Product AS P2
GROUP BY product_type);
第六章 函数 谓词 case表达式
6.1 函数
- 算术函数
- 绝大多数函数对于 NULL 都返回 NULLA
abs()绝对值函数mod(被除数,除数)round(数值,小数位数)
- 字符串函数
||或者concate(str1,str2)`:字符串连接函数len()或者length()计算字符串长度函数lower()小写转换函数upper()大写转换函数REPLACE(对象字符串,替换前的字符串,替换后的字符串)字符串替换函数SUBSTRING(对象字符串 FROM 截取的起始位置 FOR 截取的字符数):字符串截取函数
- 日期函数
current_date():获得当前日期current_time():获得当前时间current_timestamp():当前日期和时间EXTRACT(日期元素 FROM 日期):截取日期元素
- 转换函数
CAST(转换前的值 AS 想要转换的数据类型):将变量转换为其他类型的数据COALESCE(数据1,数据2,数据3……)函数——将NULL转换为其他值。COALESCE 是 SQL 特有的函数。该函数会返回可变参数 A 中左侧开始第 1个不是 NULL 的值。参数个数是可变的,因此可以根据需要无限增加。
6.2 谓词
谓词的作用就是“判断是否存在满足某种条件的记录”。如果存在这样的记录就返回真(TRUE),如果不存在就返回假(FALSE)。
like——字符串的部分一致查询。包括前方一致、中间一致和后方一致。以字符串中是否包含该条件的规则为基础的查询称为模式匹配,其中的模式也就是前面提到的“规则”- % 是代表“0 字符以上的任意字符串”的特殊符号,
LIKE 'ddd%';代表“以 ddd 开头的所有字符串”。 - 还可以使用
_(下划线)来代替 %,与 % 不同的是,它代表了“任意 1 个字符”
- % 是代表“0 字符以上的任意字符串”的特殊符号,
between A and B ——范围查询。BETWEEN 的特点就是结果中会包含 临界值。如果不想让结果中包含临界值,那就必须使用< 和 >IS NULL谓词判断是否为NULL值IN谓词。起筛选作用。相关语句为NOT IN。IN 谓词(NOT IN 谓词)具有其他谓词所没有的用法,那就是可以使用子查询作为其参数。同理,我们还可以说“能够将视图作为 IN 的参数”
SELECT product_name, purchase_price
FROM Product
WHERE purchase_price IN (320, 500, 5000);
-- 取得“在大阪店销售的商品的销售单价”
SELECT product_name, sale_price
FROM Product
WHERE product_id IN (SELECT product_id
FROM ShopProduct
WHERE shop_id = '000C');
- 注意:像使用子查询作为IN的参数的,可以完美应对数据变更的程序称为
“易维护程序”,或者“免维护程序”。这也是系统开发中需要重点考虑的部分。希望大家在开始学习编程时,就能够有意识地编写易于维护的代码。 exist()函数,右边括号内只有一个参数,通常是关联子查询,用于替代IN 。而且作为EXIST参数的子查询中经常会使用SELECT *。
/*使用EXIST选取出“大阪店(还有其他的店)在售商品的销售单价*/
SELECT product_name, sale_price
FROM Product AS P
WHERE EXISTS (SELECT *
FROM ShopProduct AS SP
WHERE SP.shop_id = '000C'
AND SP.product_id = P.product_id);
内部查询可以探查到外部的信息,但是外部没有办法直接使用子查询原表的数据,
也就是说结果可以用,但是表的重命名不能使用
6.3 case表达式
CASE 表达式是在区分情况时使用的,这种情况的区分在编程中通常称为(条件)分支
- 基本语法:
CASE WHEN <求值表达式> THEN <表达式>
WHEN <求值表达式> THEN <表达式>
WHEN <求值表达式> THEN <表达式>
.
.
.
ELSE <表达式>
END
案例:通过CASE表达式将A ~ C的字符串加入到商品种类当中
SELECT product_name,
CASE WHEN product_type = '衣服'
THEN 'A : ' | | product_type
WHEN product_type = '办公用品'
THEN 'B : ' | | product_type
WHEN product_type = '厨房用具'
THEN 'C : ' | | product_type
ELSE NULL
END
AS abc_product_type
FROM Product;
- 最后的end不能省略,表示case表达式的结束
第七章 集合运算
7.1 表的加减法
- 并集:union:取两个表的不重复的所有元素
SELECT product_id, product_name
FROM Product
UNION
SELECT product_id, product_name
FROM Product2;
- 集合运算的注意事项:
- 作为运算对象的记录的
列数必须保持一致 - 作为运算对象的记录的列的
数据类型必须保持一致 - 可以使用任何select语句,但是
order by语句只能在最后使用
- 作为运算对象的记录的
- 包含重复行的集合运算,需要在union后面使用关键字
ALL,表示重复的行也要计算在内
SELECT product_id, product_name
FROM Product
UNION ALL
SELECT product_id, product_name
FROM Product2;
inetrsect——交集:取两张表的公共部分except——差集:就是对表做减法,前面的表是被减数,后面的是减数
7.2 联结
内联结——INNER JOIN:- 内联结只能选取出
同时存在于两张表中的数据 from子句中有多个表,表示需要联结的表;ON后面是联结条件,通常是多个表中相同的列进行联结;- 使用联结时SELECT子句中的列需要按照
“<表的别名>.<列名>”的格式进行书写。 - 使用联结运算将
满足相同规则的表联结起来时,WHERE、GROUP BY、 HAVING、 ORDER BY等工具都可以正常使用。将联结之后的结果想象为新创建出来的一张表,对这张表使用WHERE 子句等工具。
- 内联结只能选取出
SELECT SP.shop_id, SP.shop_name, SP.product_id, P.product_name,
P.sale_price
FROM ShopProduct AS SP INNER JOIN Product AS P ①
ON SP.product_id = P.product_id;
外联结——outer join:内联结只能选取出同时存在于两张表中的数据,对于外联结来说,只要数据存在于某一张表当中,就能够读取出来。在实际的业务中,例如想要生成固定行数的单据时,就需要使用外联结- 很重要的一点是,将哪一张表作为主表,最终的结果中会
包含主表内所有的数据。指定主表的关键字是LEFT 和 RIGHT。
- 很重要的一点是,将哪一张表作为主表,最终的结果中会
SELECT SP.shop_id, SP.shop_name, SP.product_id, P.product_name,
P.sale_price
FROM Product AS P LEFT OUTER JOIN ShopProduct AS SP ①
ON SP.product_id = P.product_id;
多表联结:每两个表进行联结,分别指定联结条件
SELECT SP.shop_id, SP.shop_name, SP.product_id, P.product_name,
P.sale_price, IP.inventory_quantity
FROM ShopProduct AS SP INNER JOIN Product AS P ①
ON SP.product_id = P.product_id
INNER JOIN InventoryProduct AS IP ②
ON SP.product_id = IP.product_id
WHERE IP.inventory_id = 'P001';
交叉联结:对满足相同规则的表进行交叉联结的集合运算符是CROSS JOIN(笛卡 儿积)。进行交叉联结时无法使用内联结和外联结中所使用的 ON 子句,这是因为交叉联结是对两张表中的全部记录进行交叉组合,因此结果中的记录数通常是两张表中行数的乘积。
第八章 SQL高级处理
8.1 窗口函数
-
概念:窗口函数可以进行
排序、生成序列号等一般的聚合函数无法实现的高级
操作。 -
语法格式:
<窗口函数> OVER ([PARTITION BY <列清单>] ORDER BY <排序用列清单>) -
窗口函数种类:包括一般的聚合函数和专用的窗口函数
- 一般聚合函数:sum count avg max min
- 专用窗口函数:由于
专用窗口函数无需参数,因此通常括号中都是空的。
-
专用窗口函数:
rank():计算排序时,如果存在相同位次的记录,则会跳过之后的位次。例如有 3 条记录排在第 1 位时:1 位、1 位、1 位、4 位……DENSE_RANK函数:同样是计算排序,即使存在相同位次的记录,也不会跳过之后的位次。例)有 3 条记录排在第 1 位时:1 位、1 位、1 位、2 位……ROW_NUMBER函数:赋予唯一的连续位次。例)有 3 条记录排在第 1 位时:1 位、2 位、3 位、4 位……
-
窗口函数只能用在 SELECT 子句之中。反过来说,就是这类函数不能在WHERE 子句或者 GROUP BY 子句中使用。:这是因为在 DBMS 内部,窗口函数是对 WHERE 子句或者 GROUP BY 子句处理后的“结果”进行的操作。在得到用户想要的结果之前,即使进行了排序处理,结果也是错误的。在得到排序结果之后,如果通过 WHERE 子句中的条件除去了某些记录,或者使用 GROUP BY 子句进行了汇总处理,那好不容易得到的排序结果也无法使用了。正是由于这样的原因,
在 SELECT 子句之外“使用窗口函数是没有意义的”,所以在语法上才会有这样的限制。 -
普通聚合函数作为窗口函数时,称为
累计的统计方法。函数中要加入参数,
SELECT product_id, product_name, sale_price,
SUM (sale_price) OVER (ORDER BY product_id) AS current_sum
FROM Product;
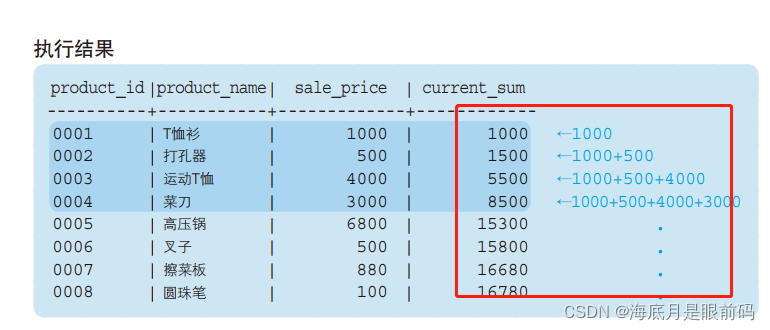
-
计算移动平均
窗口函数就是将表以窗口为单位进行分割,并在其中进行排序的函数。其实其中还包含在窗口中指定
更加详细的汇总范围的备选功能,该备选功能中的汇总范围称为框架。rows n preceding/following:定义框架,截止到当前记录的前n行或者后n行。比如说截止到当前记录的前两行,说明是三期移动平均,即只计算当前记录以及当前记录前面两行记录的窗口函数值
SELECT product_id, product_name, sale_price,
AVG (sale_price) OVER (ORDER BY product_id
ROWS 2 PRECEDING) AS moving_avg
FROM Product;
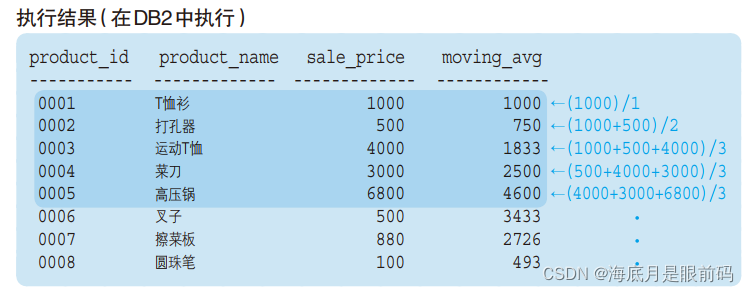
两个order by函数:OVER 子句中的 ORDER BY 只是用来决定窗口函数按照什么样的顺序进行计算的,对结果的排列顺序也就是最大的那个select子句并没有影响
8.2 GROUPING运算符
rollup:该运算符的作用,就是一次计算出不同聚合键组合的结果
SELECT product_type, SUM(sale_price) AS sum_price
FROM Product
SELECT product_type, SUM(sale_price) AS sum_price
FROM Product
GROUP BY ROLLUP(product_type);;
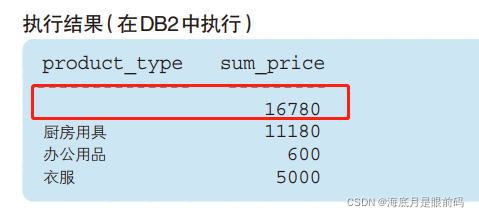
- 代码解释:
GROUP BY ROLLUP(product_type);出了如下两种组合的汇总结果。
① GROUP BY ()
② GROUP BY (product_type)
①中的 GROUP BY() 表示没有聚合键,也就相当于没有 GROUP BY子句(这时会得到全部数据的合计行的记录),该合计行记录称为超级分组记录(super group row)。超级分组记录的 product_type列的键值(对 DBMS 来说)并不明确,因此会默认使用NULL。 grouping函数:SQL 提供了一个用来判断超级分组记录的 NULL的特定函数 —— GROUPING 函数。该函数在其参数列的值为超级分组记录所产生的 NULL 时返回 1,其他情况返回 0
SELECT GROUPING(product_type) AS product_type,
GROUPING(regist_date) AS regist_date, SUM(sale_price) AS sum_price
FROM Product
GROUP BY ROLLUP(product_type, regist_date);
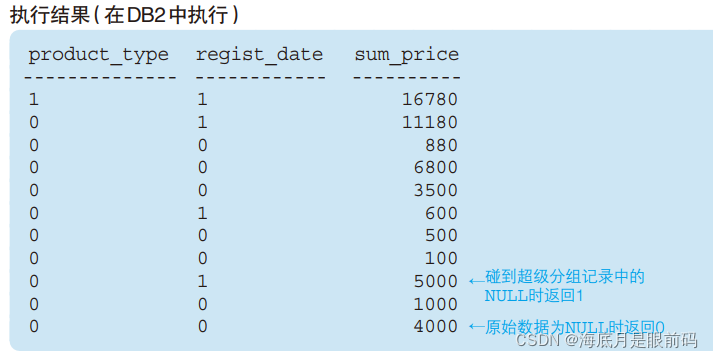
- 在超级分组记录的
键值中插入恰当的字符串。利用前面grouping得到的01值进行条件赋值
SELECT CASE WHEN GROUPING(product_type) = 1
THEN '商品种类 合计'
ELSE product_type END AS product_type,
CASE WHEN GROUPING(regist_date) = 1
THEN '登记日期 合计'
ELSE CAST(regist_date AS VARCHAR(16)) END AS regist_date,
SUM(sale_price) AS sum_price
FROM Product
GROUP BY ROLLUP(product_type, regist_date);
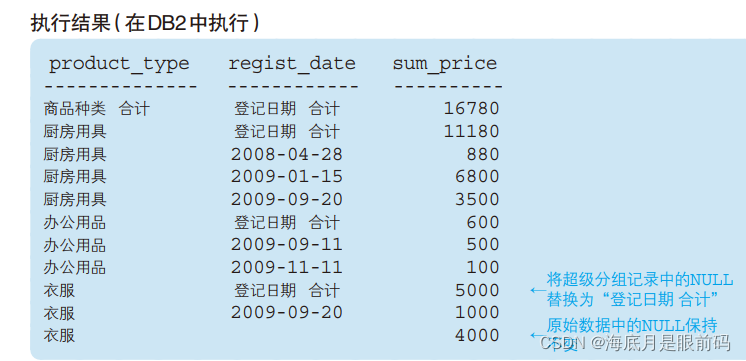
cube()用数据来搭积木。cube的语法与rollup语法相同,所谓 CUBE,就是将 GROUP BY 子句中聚合键的“所有可能的组合”的汇总结果集中到一个结果中。因此,组合的个数就是 2 n 2^n 2n(n 是聚合键的个数)
SELECT CASE WHEN GROUPING(product_type) = 1
THEN '商品种类 合计'
ELSE product_type END AS product_type,
CASE WHEN GROUPING(regist_date) = 1
THEN '登记日期 合计'
ELSE CAST(regist_date AS VARCHAR(16)) END AS regist_date,
SUM(sale_price) AS sum_price
FROM Product
GROUP BY CUBE(product_type, regist_date);
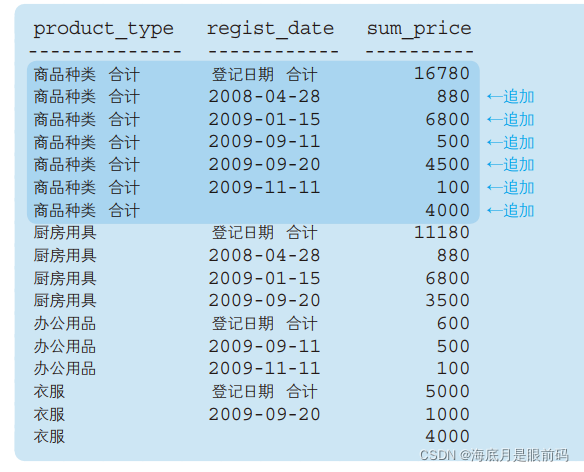
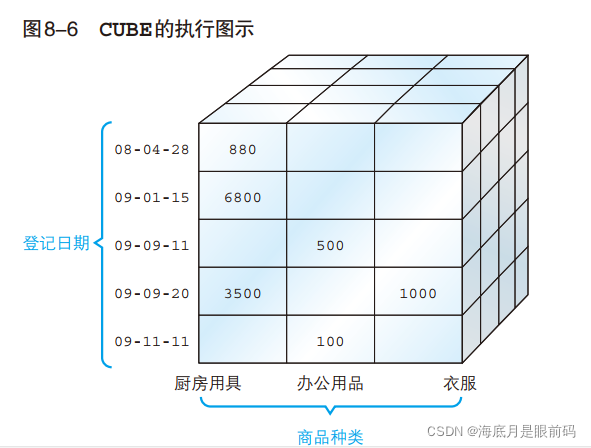
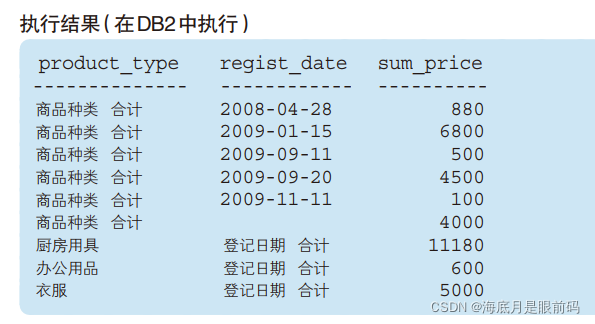
- 之前的 CUBE 的结果就是根据聚合键的所有可能的组合计算而来的。如果希望从中
选取出将“商品种类”和“登记日期”各自作为聚合键的结果,或者不想得到“合计记录和使用 2 个聚合键的记录”时,可以使用GROUPING SETS
SELECT CASE WHEN GROUPING(product_type) = 1
THEN '商品种类 合计'
ELSE product_type END AS product_type,
CASE WHEN GROUPING(regist_date) = 1
THEN '登记日期 合计'
ELSE CAST(regist_date AS VARCHAR(16)) END AS regist_date,
SUM(sale_price) AS sum_price
FROM Product
GROUP BY GROUPING SETS (product_type, regist_date);


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









