





这里暂时还演示不了多路复用,因为多路复用需要结合拦截器一起。
所以多路服用的案例放到了自定义拦截器那里
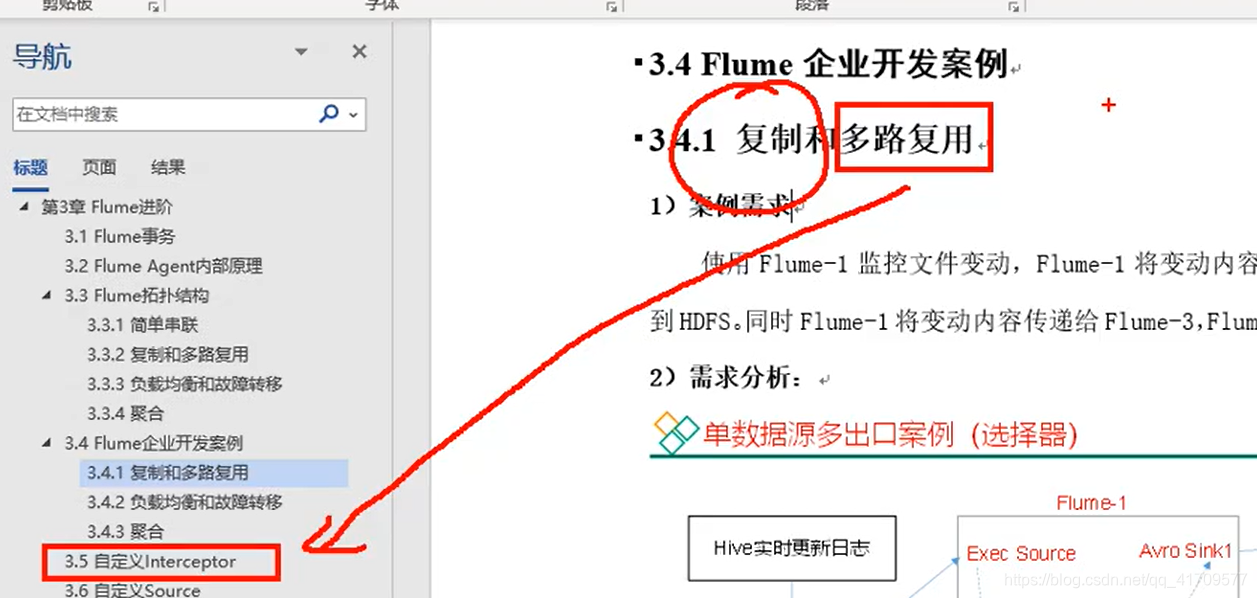
监控文件的变动使用exec source和taildir均可。
但是优先使用taildir,毕竟挂了还可以再用。
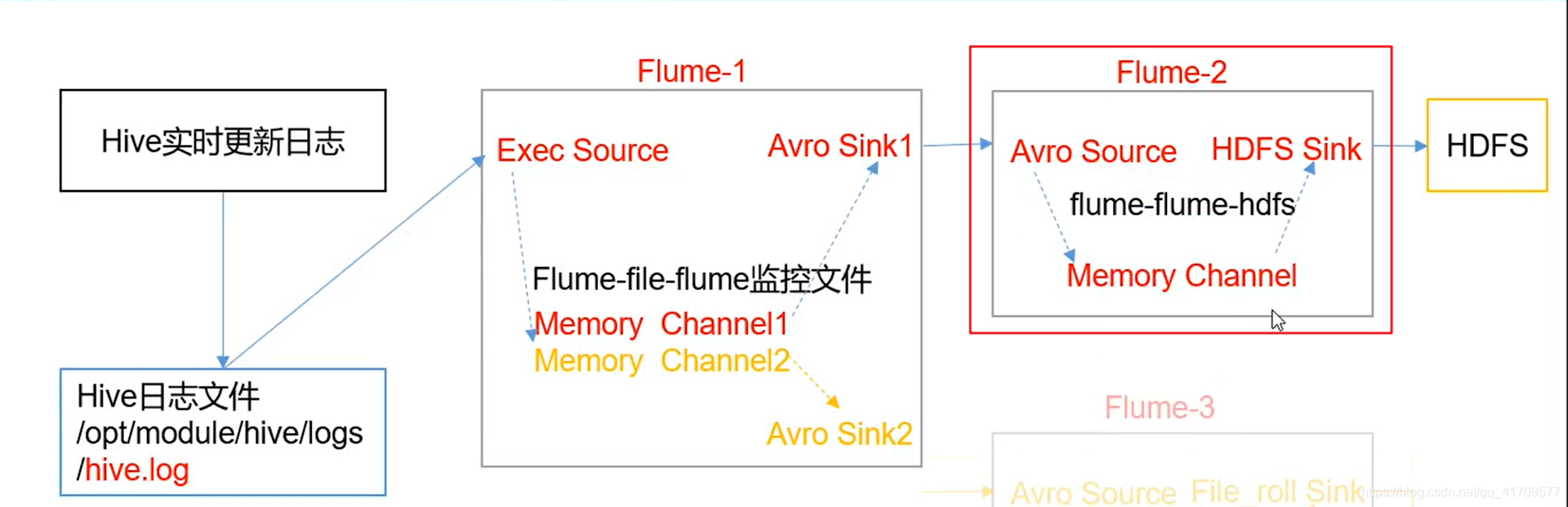
监控文件的变动,将内容传给flume-2
flume1给flume2使用阿波罗sink和source

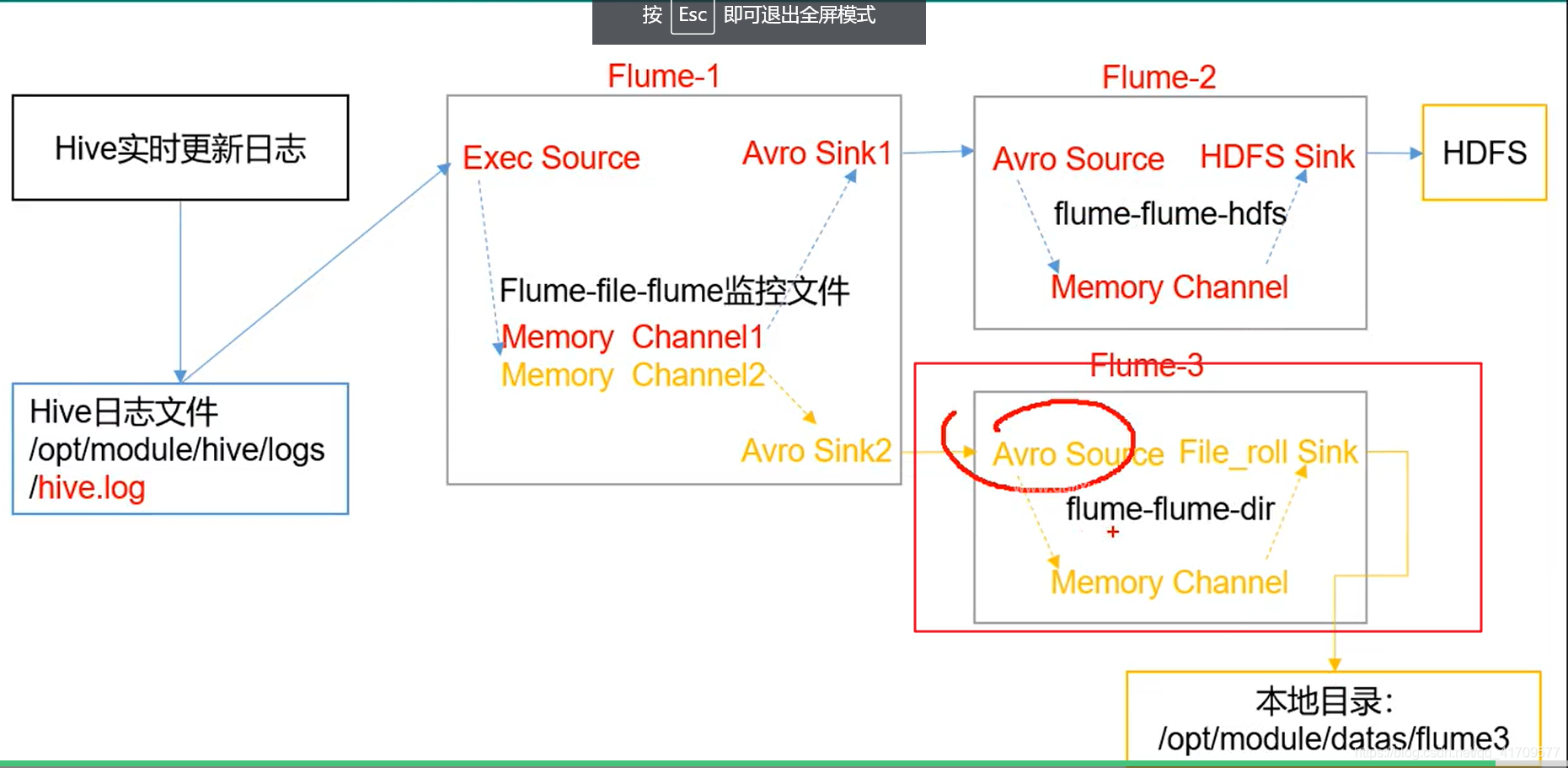
看avro sink /source 和 roll sink
最终的目的把hive实时更新的日志数据上传到hdfs,同时在本地还做一个备份。

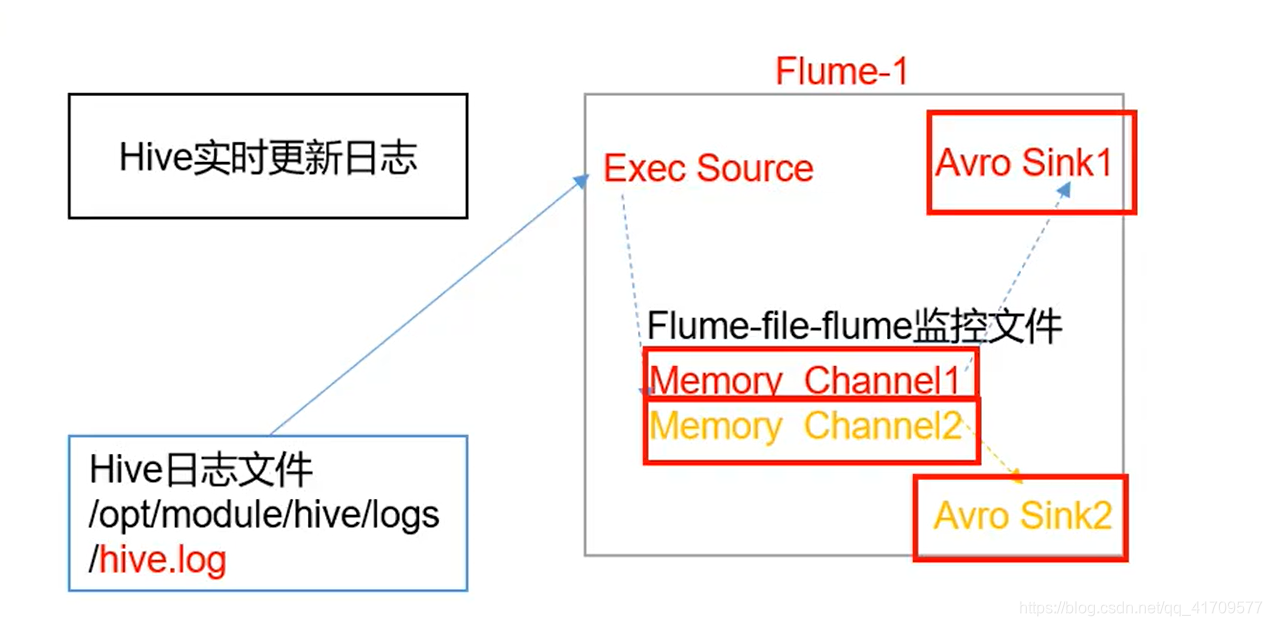
采集hive数据的flume1使用两个channel,两个sink
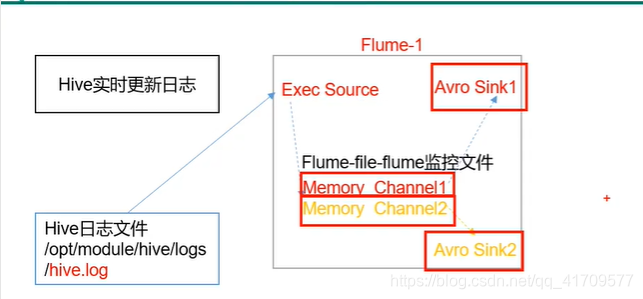
为啥这里不使用一个channel对应两个sink呢
这里不能使用一个channel对应两个sink的。
如果用一个channel那么中间用的就是一个sink组,sink组里面没有什么副本机制的,只有默认,故障转移和负载均衡三种。故障转移:数据只会往一个sink里面发
负载均衡:数据是一人一条发,就不是完整的数据了。
这里我们需要达到的目的是:最终hdfs和本地磁盘都有hive日志。
只能多个channel。一定要。
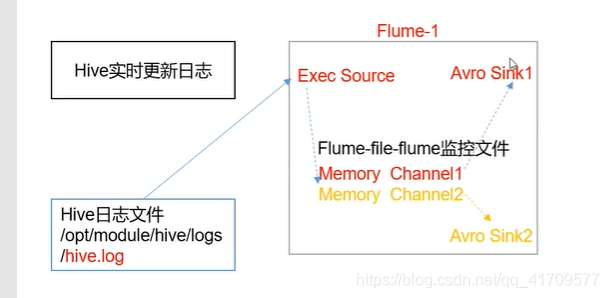
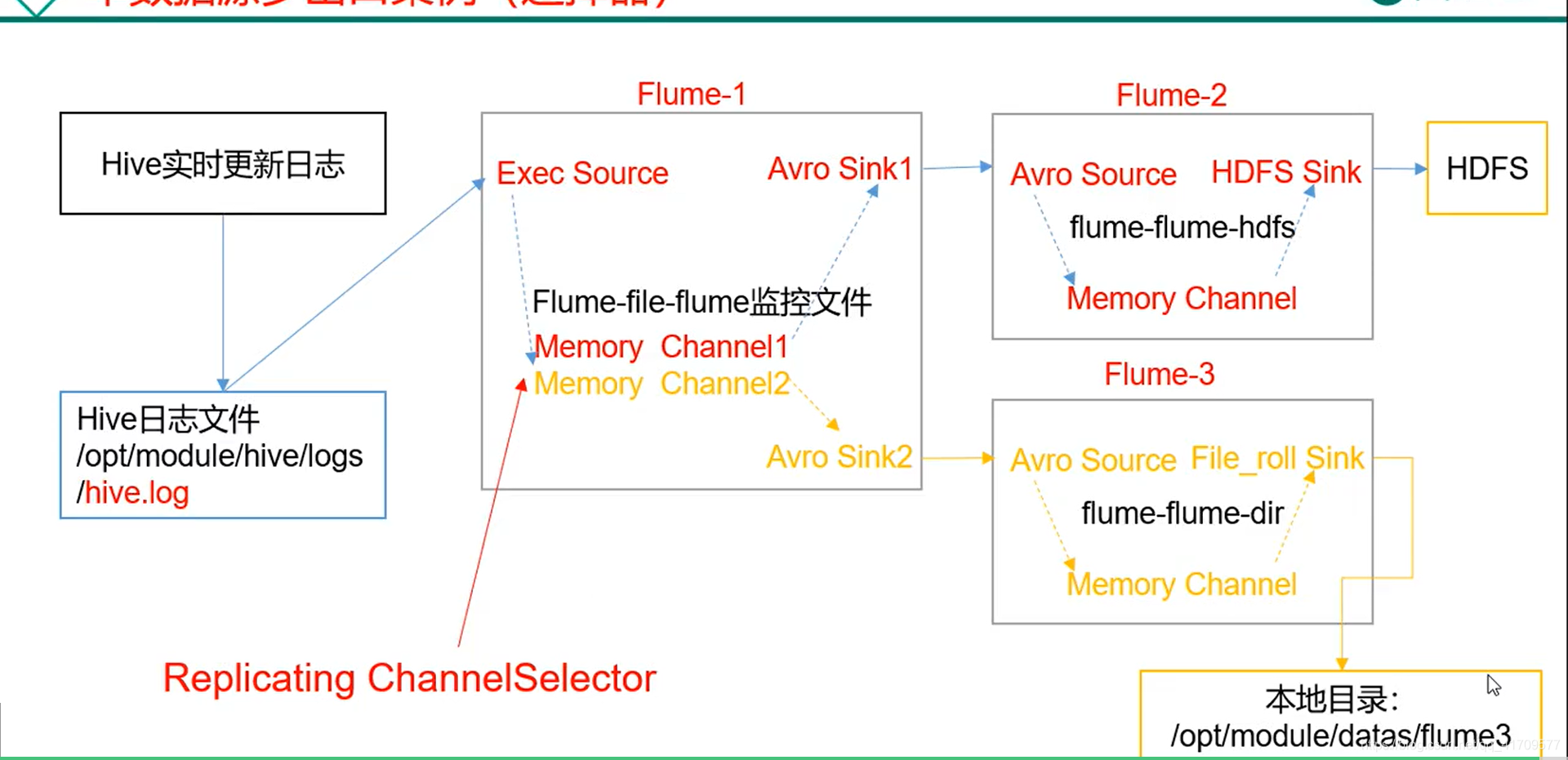
中间使用 复制选择器。hdfs的数据和本地文件的数据必须保持一致。
任务21:21_Flume高级_Channel选择器副本机制(需求分析)
最新推荐文章于 2025-09-08 19:25:22 发布
 该博客探讨了在Flume中实现多路复用和监控文件变动的方法,强调了使用taildir而非execsource的优先性。在确保HDFS和本地磁盘数据一致性的情况下,通过复制选择器配置,实现Hive日志的实时更新同步到HDFS并备份到本地。博客指出,为确保完整数据传输,必须使用多个channel,而非一个channel对应多个sink。此外,还提到了AvroSink和RollSink在数据流处理中的应用。
该博客探讨了在Flume中实现多路复用和监控文件变动的方法,强调了使用taildir而非execsource的优先性。在确保HDFS和本地磁盘数据一致性的情况下,通过复制选择器配置,实现Hive日志的实时更新同步到HDFS并备份到本地。博客指出,为确保完整数据传输,必须使用多个channel,而非一个channel对应多个sink。此外,还提到了AvroSink和RollSink在数据流处理中的应用。

















 1178
1178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









