




 博客讨论了Flume在大数据集群中的应用,强调了跨机器数据传输的规则,指出Flume agent应放置在数据源服务器上。文章提到了使用副本机制实现数据同时发送到JDFS和logger,通过sink组缓解单个sink压力。还探讨了聚合策略,如何通过Avrosource和Avrosink进行数据汇总,并提出了两种不同的汇总方法。生产环境中,负载均衡用于解决压力分布和故障转移问题,确保多台后台服务器的日志数据有效聚合并写入HDFS。
博客讨论了Flume在大数据集群中的应用,强调了跨机器数据传输的规则,指出Flume agent应放置在数据源服务器上。文章提到了使用副本机制实现数据同时发送到JDFS和logger,通过sink组缓解单个sink压力。还探讨了聚合策略,如何通过Avrosource和Avrosink进行数据汇总,并提出了两种不同的汇总方法。生产环境中,负载均衡用于解决压力分布和故障转移问题,确保多台后台服务器的日志数据有效聚合并写入HDFS。
拓扑结构:
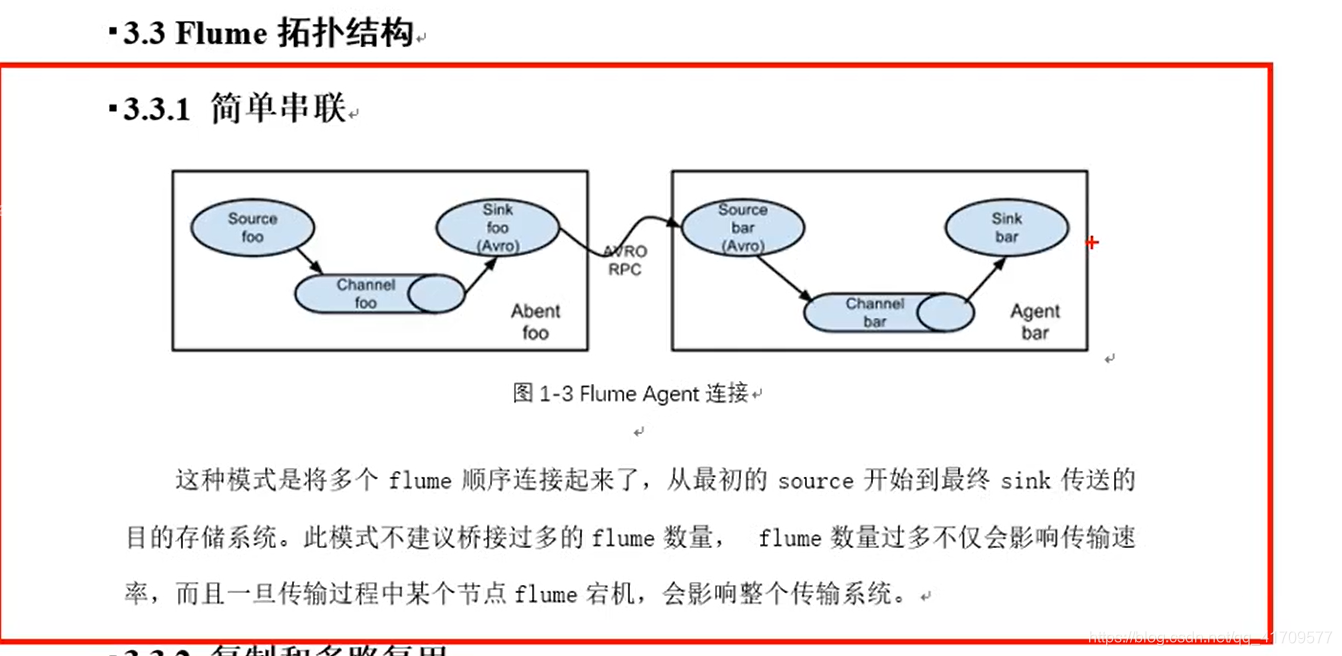
启动两个agent,就是两个flume的任务,可以在同一台机器,也可以在另一台机器。后台服务器和大数据集群不在一块,
数据落在java后台服务器上面,那flume装在哪呢?
装一个在大数据集群机器上,肯定不能读取后台服务器磁盘上的文件。
A机器不能直接读B机器磁盘的文件,必须通过端口网络通信,让他传输过来,假如在后台服务器和大数据集群上都启动了flume,从原始读数据的后台服务器,agent一定放在后台这里,因为跨机器不能直接读取别人磁盘的内容。只能把人家的数据读出来之后,写到某一个端口之后,再去读取。这个是OK的。
但是远程直接把人家的磁盘数据读取过来,这是监控不了的。taildir和exec都可以读文件,文件的地址是不能写别人机器的地址。只能写自己的。
复制和多路复用:
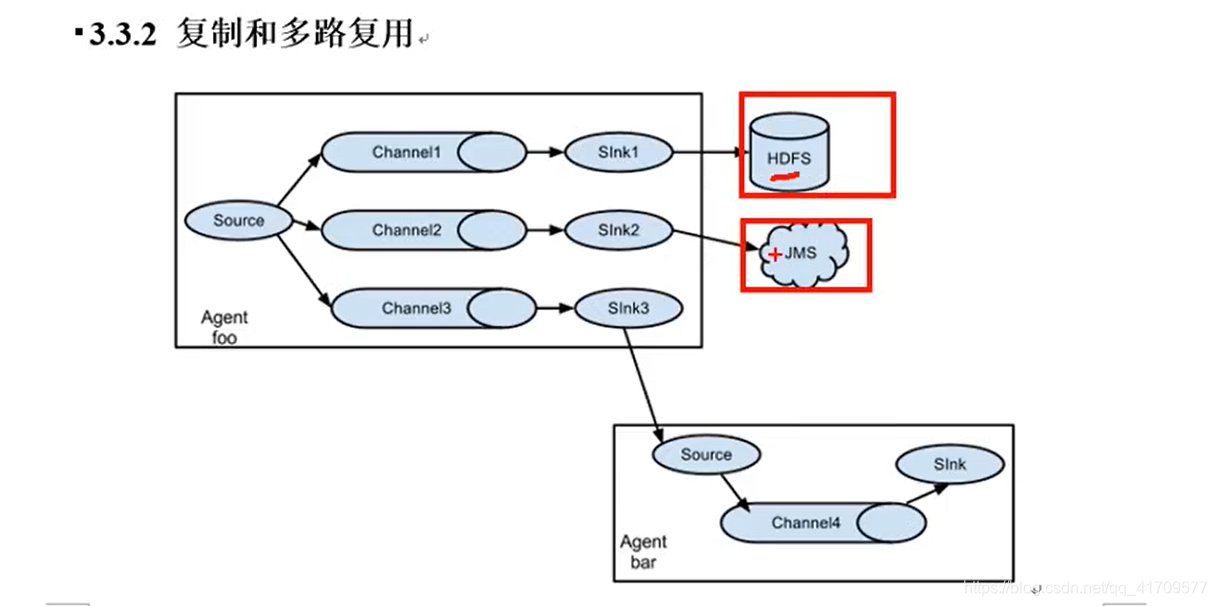
想将采集的数据既发给JDFS。又想发给logger,就要使用副本机制。
一个channel多个sink,这就是sink组。
不使用sink组,直接使用阿波罗sink,一个channel,一个hdfs sink 给数据给hdfs
这样单个sink的压力会很大。使用三个sink的轮询的方式,让三个sink去写数据到hdfs.
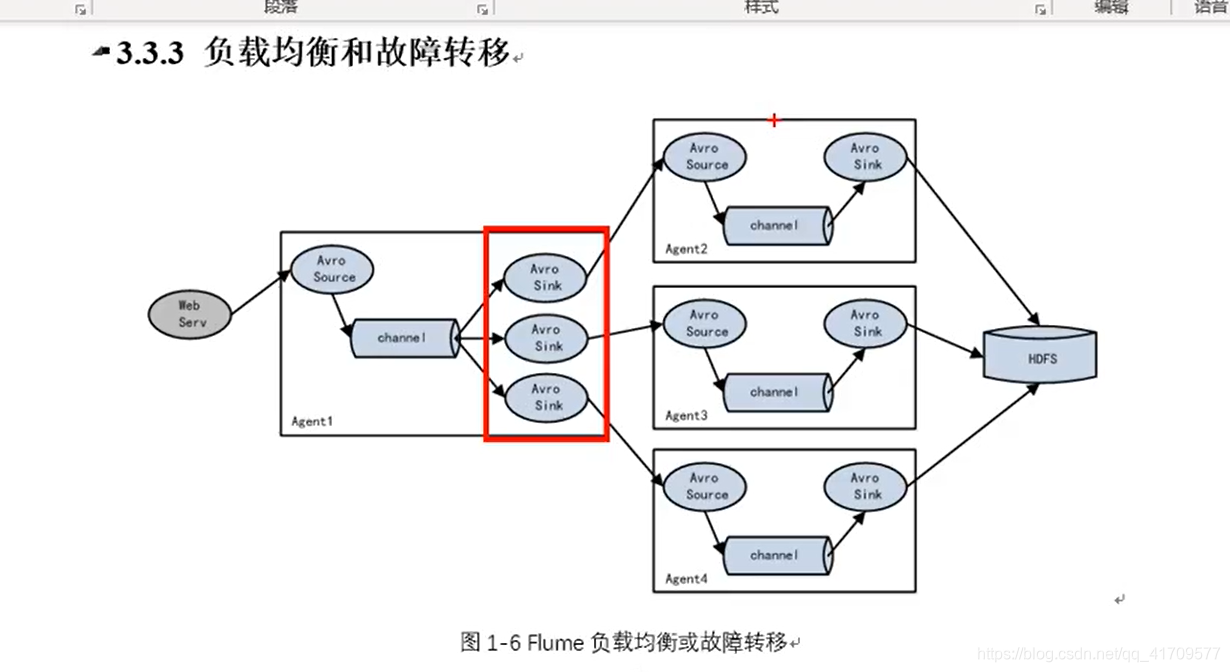
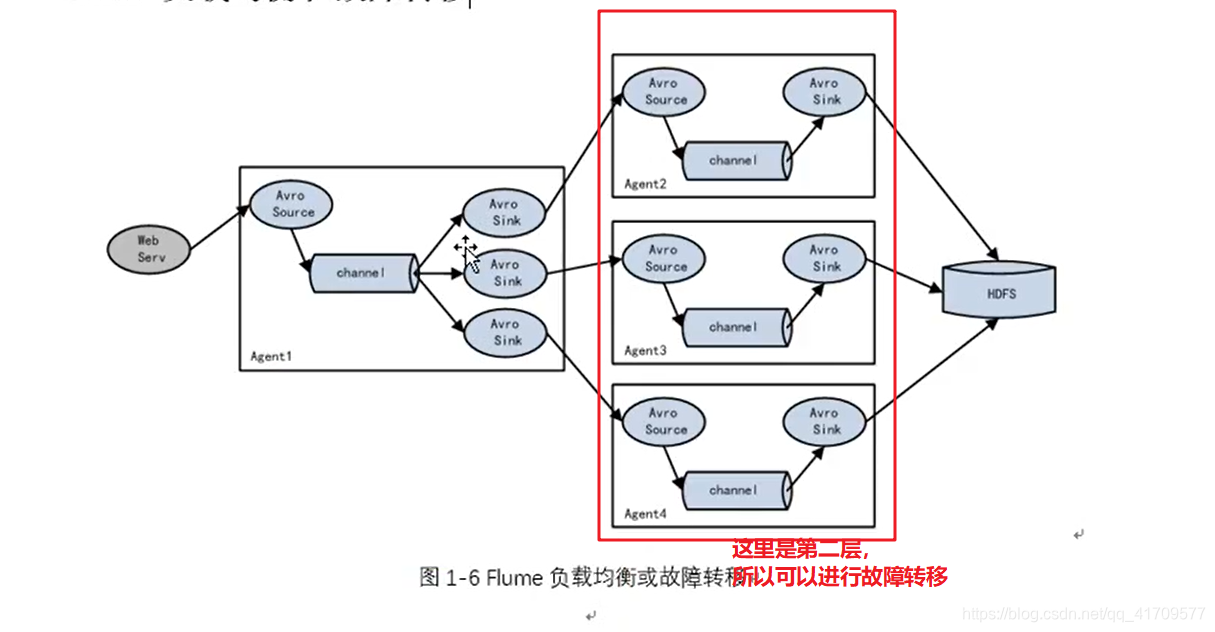
负载均衡只要解决单台机器压力过大的问题,同时解决古惑仔那个故障转移的问题。
生产环境主要用负载均衡。
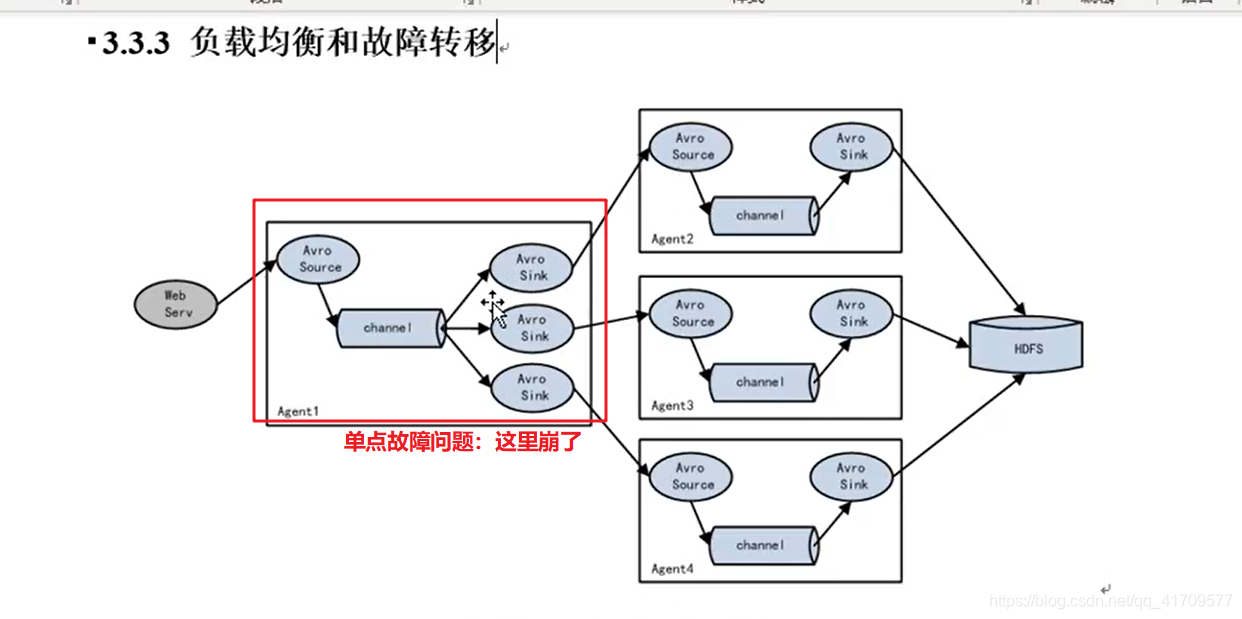
flume存在单点故障的问题。
两个人去读原始数据去读数据,是备份的关系,做不到你不工作,我工作的情况。
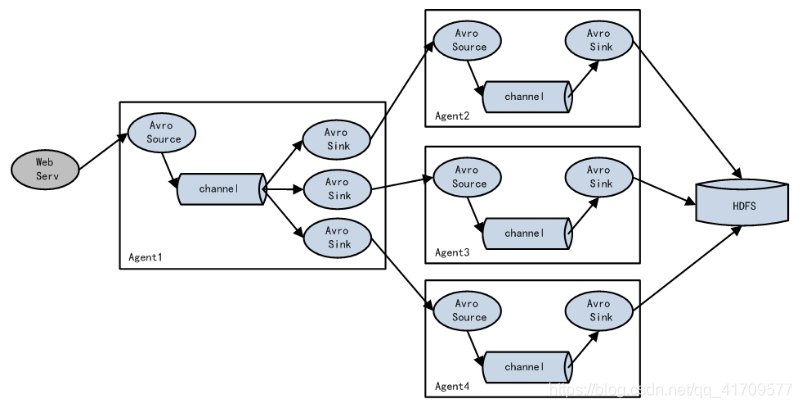
聚合:用的很多。
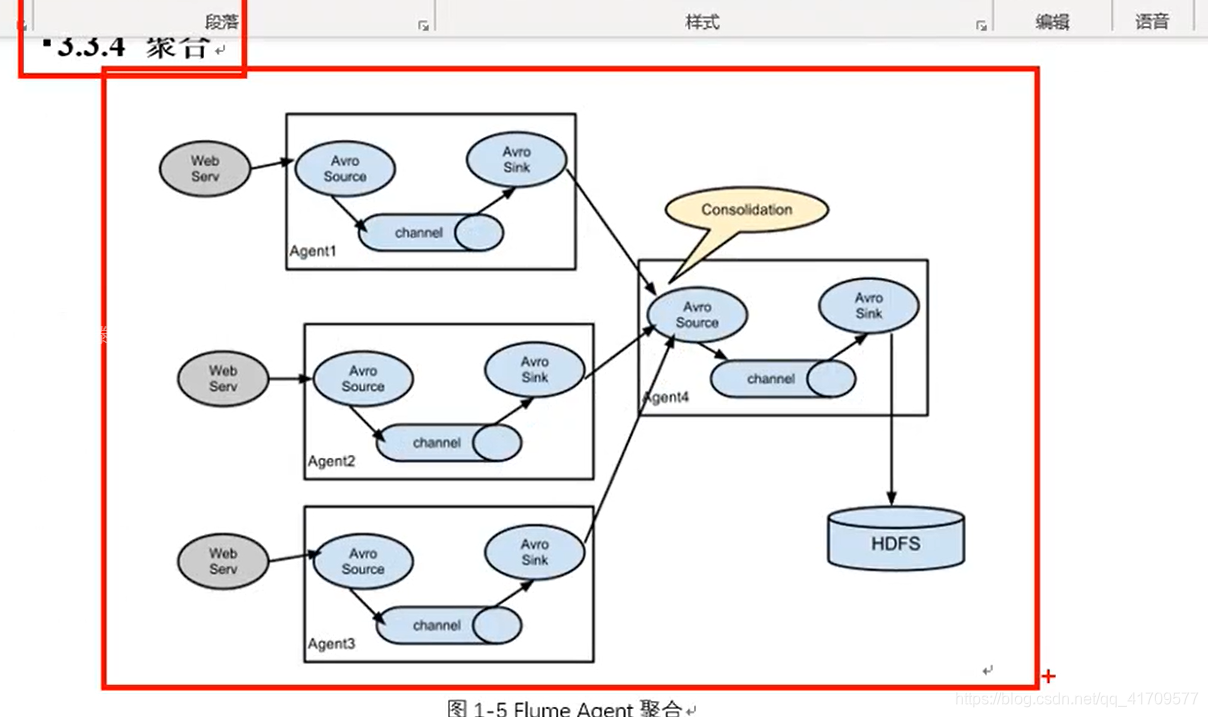
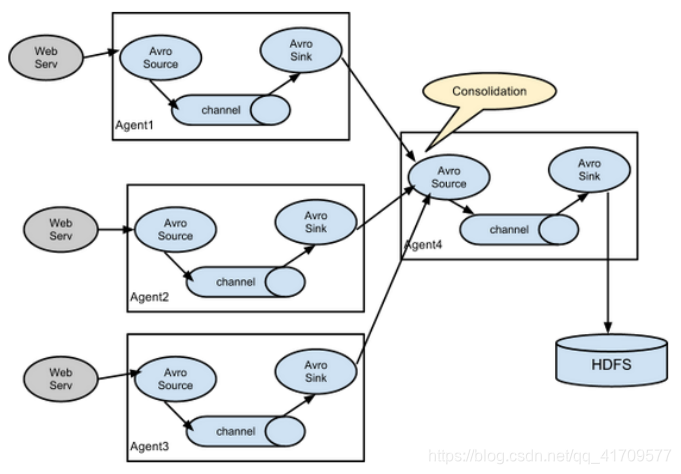
多个源头,不一样的数据,最后的数据都要写到hdfs上去。同时上千个机器去访问hdfs不好,肯定是希望某一台机器去访问hdfs。
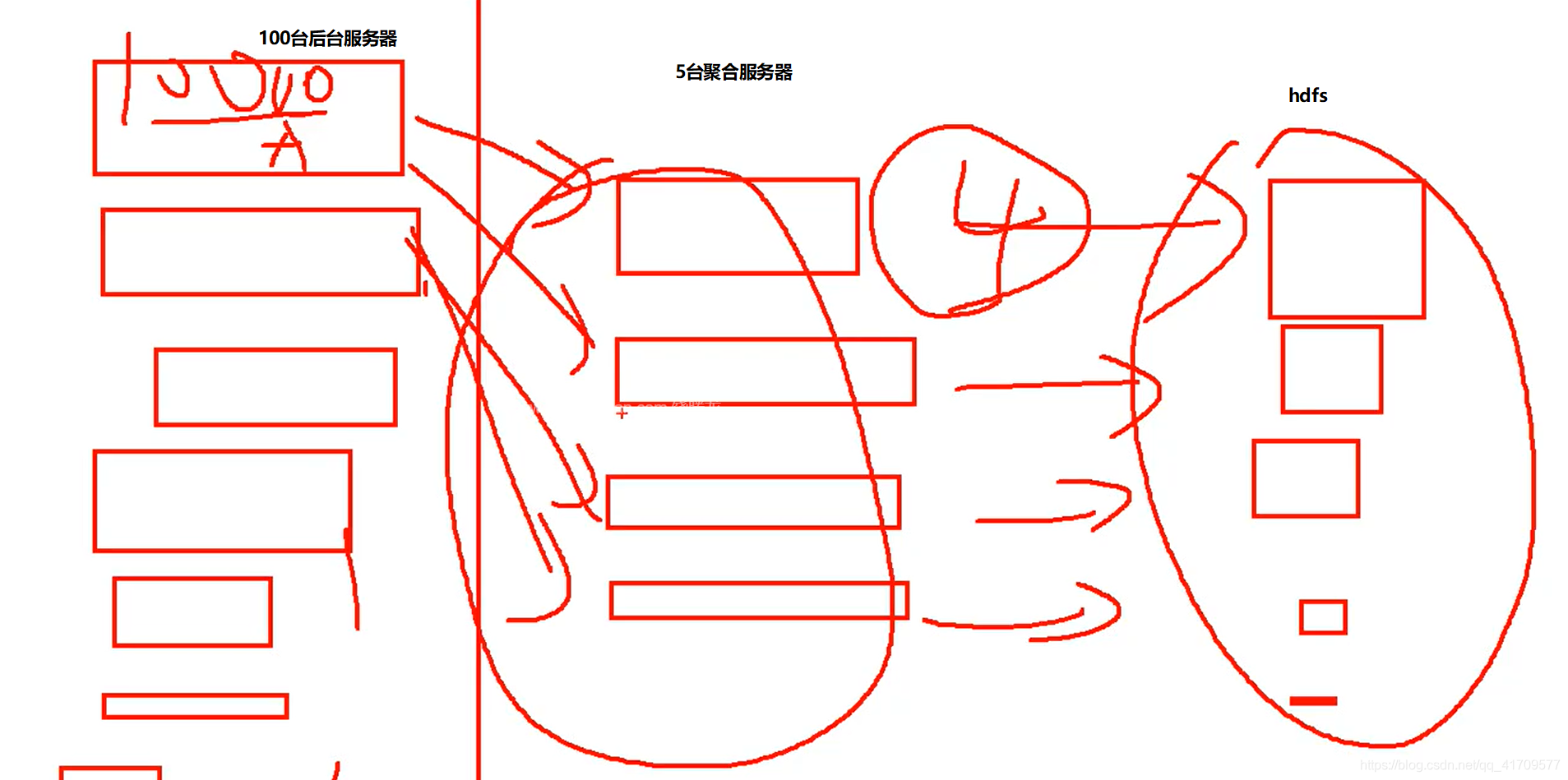
生产环境中,后台服务器肯定很多台,他们的数据不是副本关系,多个后台服务器处理同一套业务,但是,任何一台都不可能说同时处理那么多用户的请求,这时候就需要负载均衡,处理的业务,用户请求来了,到底谁来处理呢?前面有个软件层面的负载均衡,将所有请求分别发到不同服务器,每一台服务器上都会产生不同的日志文件,但是最后需要汇总所有的日志。所以,需要将这些服务器做一下聚合,这么多数据写给一个机器,压力太大了。
前面有100台,后面又5台汇总,之后就是这5台服务器操作hdfs
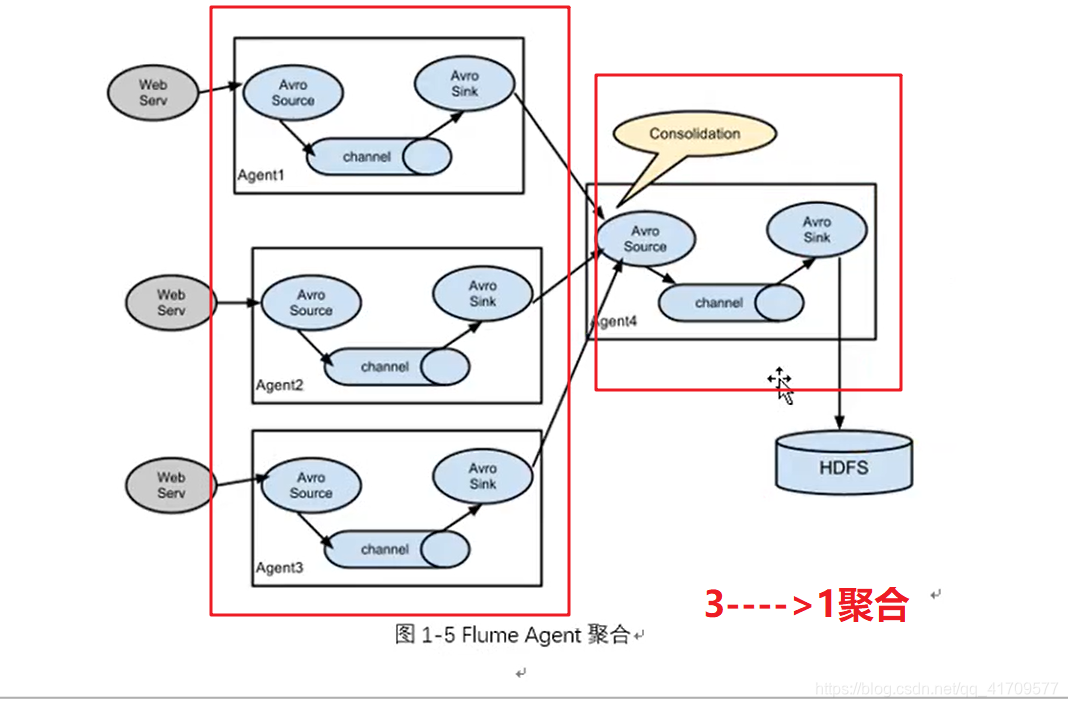
汇总方式1:
三个avro sink发往一个avro source
都发往一个端口44444
汇总方式2:
三个avro sink发往不同的avro source

每个avro sink发往不同的端口。这个也可以,第二层avro source必须要有三个source,
三个source对应一个channel,最后发往hdfs

















 4614
4614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









