




编写MR程序在集群上运行。输入输出路径不要写死,作为参数传进来。
方式一、

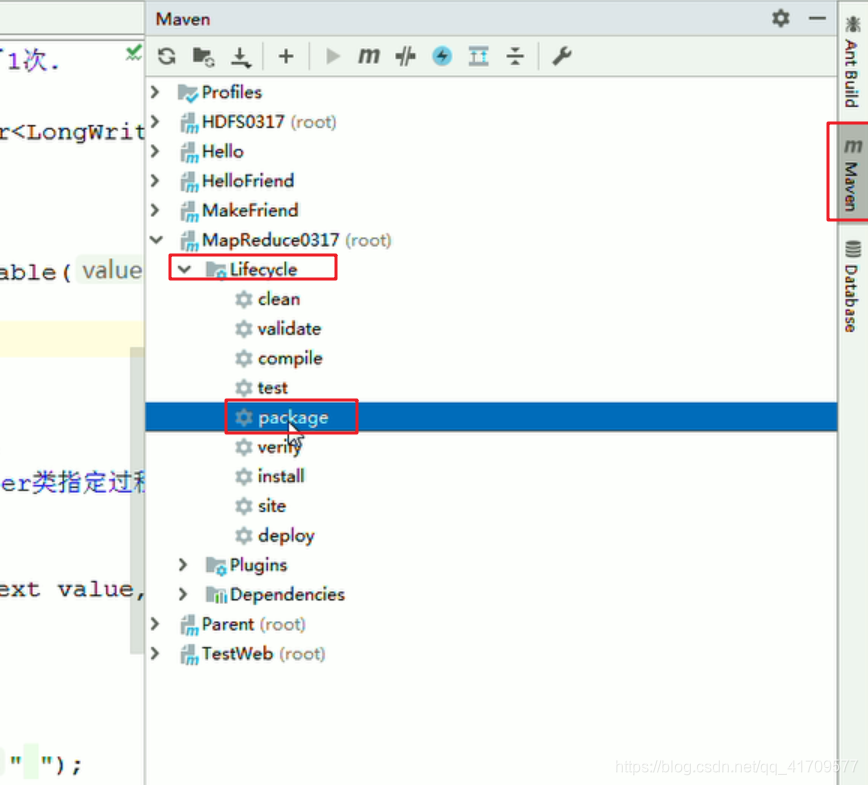
打jar包
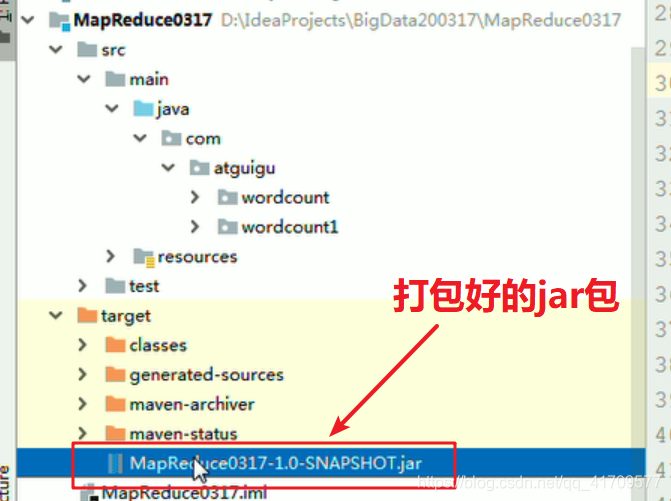
把这个包放到桌面上去
把jar包放到这个linux目录上
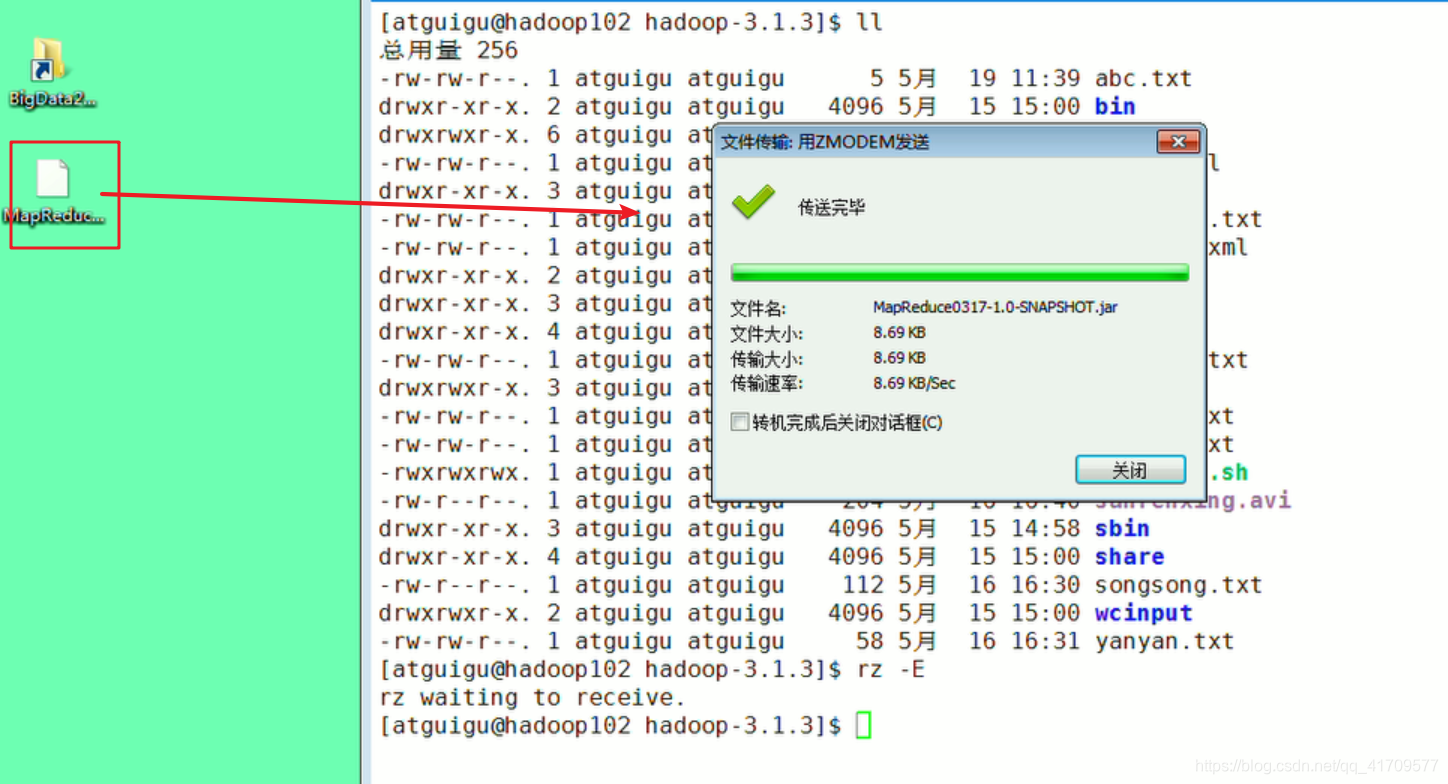
启动集群
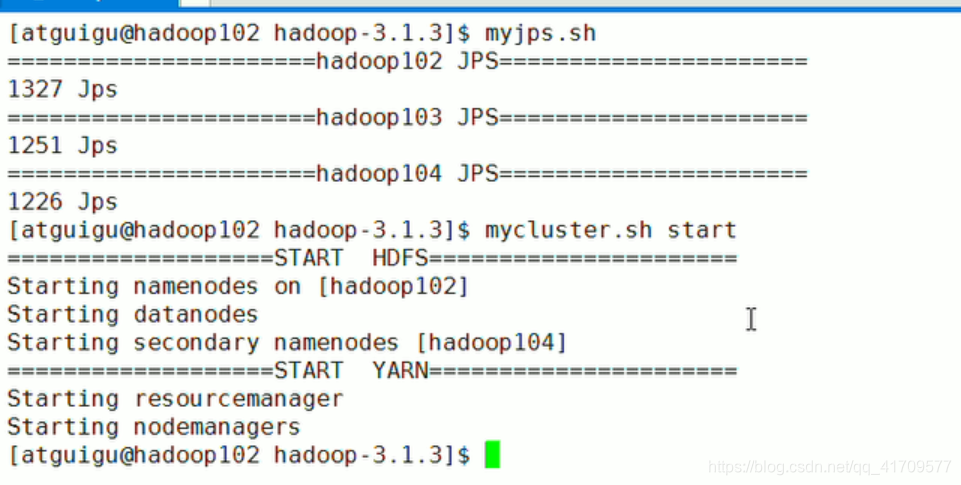
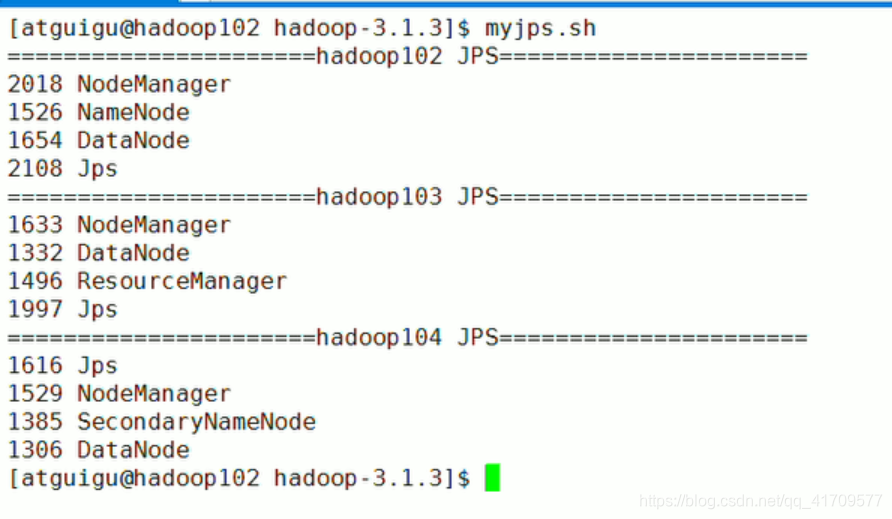
准备测试数据,放在集群上:


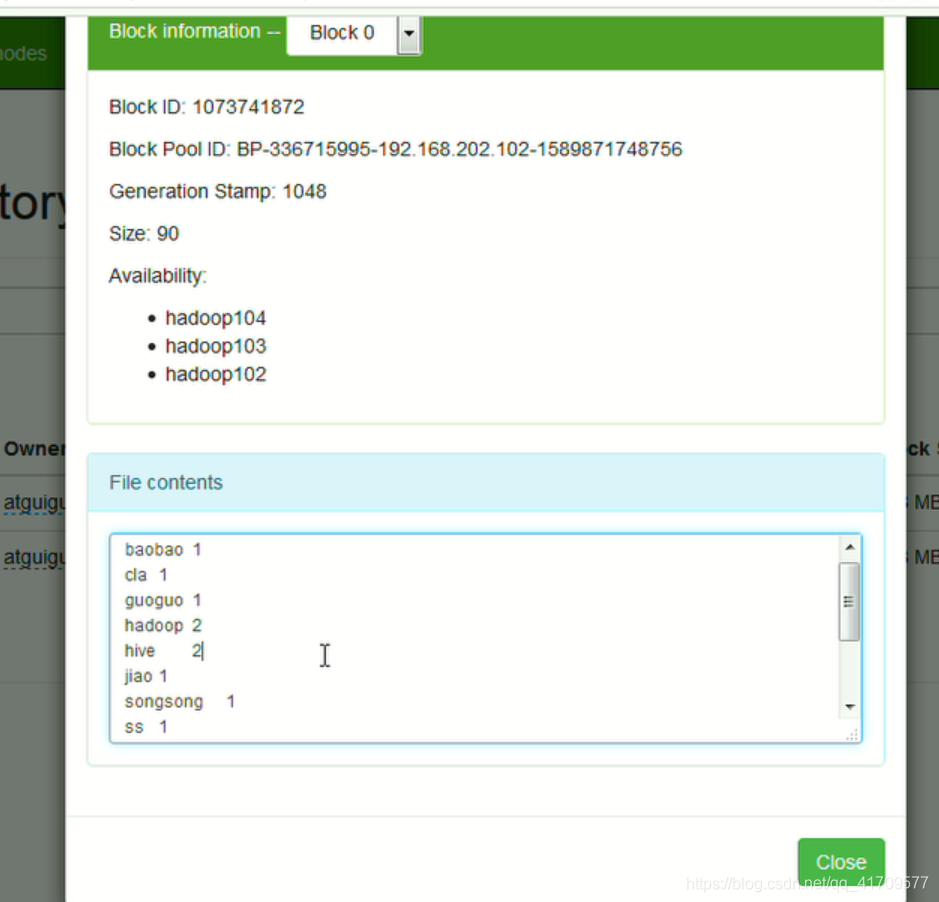

在集群上运行的方式2:
程序的入口还是在idea,但是真正运行在集群上。
在windows上向集群提交任务:
需要在configuration上设置一些参数:
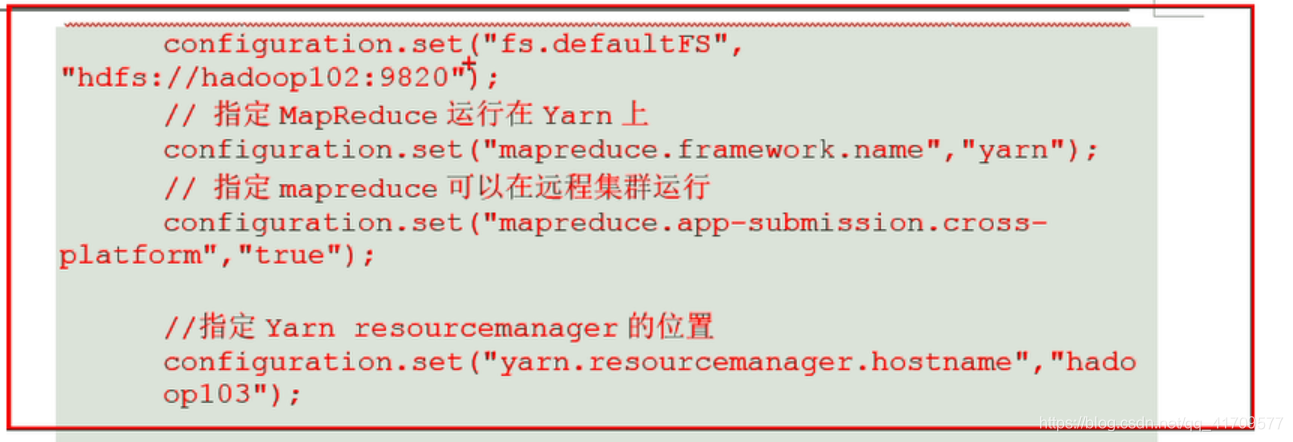
因为在集群上运行一定要涉及到jar包,
之前写的方式:

现在:


MR程序在集群上运行的两种方式
最新推荐文章于 2023-03-28 13:06:09 发布
 本文介绍了在Hadoop集群上运行MapReduce程序的两种方法。方式一是将编译好的jar包上传到Linux目录,然后启动集群并使用测试数据运行。方式二是通过IDEA直接提交任务到集群,需要在配置中指定相关参数,确保集群能够找到并执行jar包。
本文介绍了在Hadoop集群上运行MapReduce程序的两种方法。方式一是将编译好的jar包上传到Linux目录,然后启动集群并使用测试数据运行。方式二是通过IDEA直接提交任务到集群,需要在配置中指定相关参数,确保集群能够找到并执行jar包。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 922
922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









