









目录
第四章 快速排序
快速排序——一种常用的优雅的排序算法。快速排序使用分而治之的策略。
分而治之(divide and conquer,D&C)——一种著名的递归式问题解决方法。
4.1 分而治之 D&C
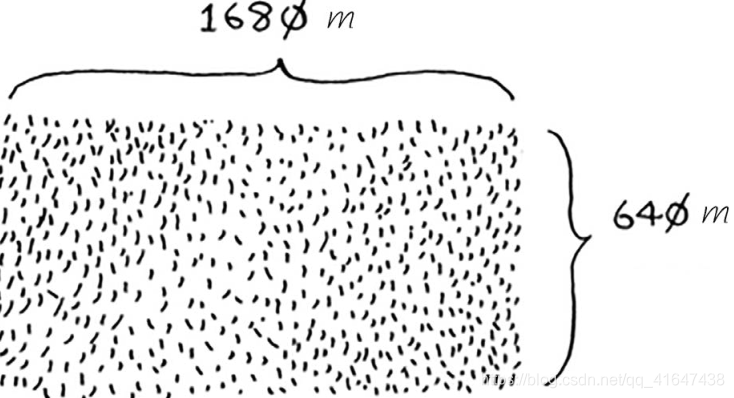
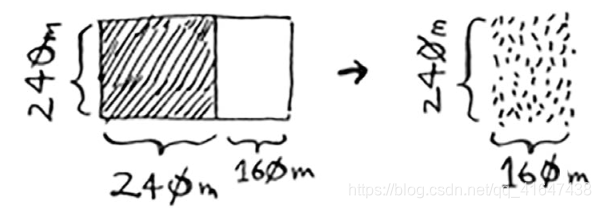
有一块土地,你要将这块地均匀地分成方块,且分出的方块要尽可能大。
D&C解决问题的过程包括两个步骤:
(1) 找出基线条件,这种条件必须尽可能简单。
(2) 不断将问题分解(或者说缩小规模),直到符合基线条件。
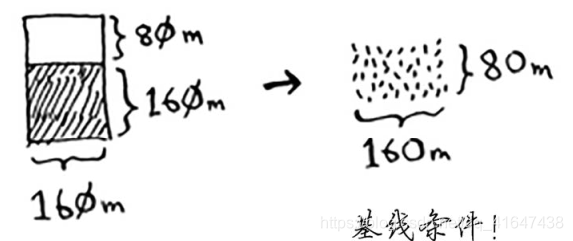
在这个问题中,基线条件:最容易处理的情况是,一条边的长度是另一条边的整数倍。如果一边长25 m,另一边长50 m,那么可使用的最大方块为 25 m×25 m。
递归条件:每次递归调用都必须缩小问题的规模。 首先找出这块地可容纳的最大方块。
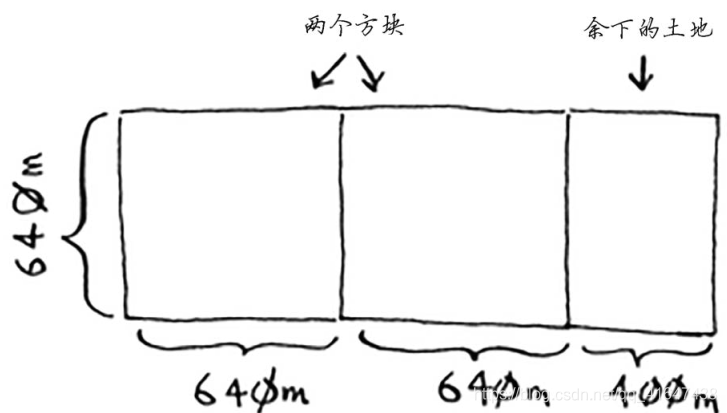
对余下的那一小块地使用相同的算法。、
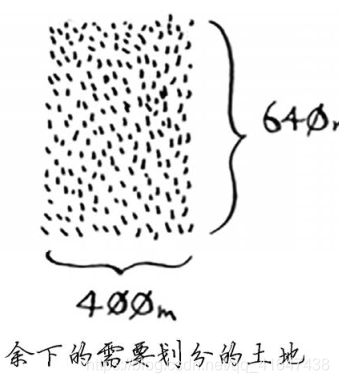
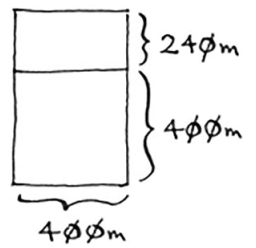
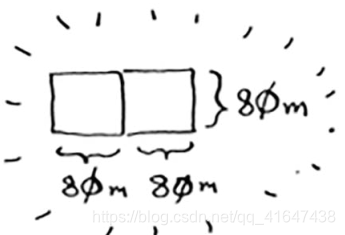
因此,对于最初的那片土地,适用的最大方块为80 m× 80 m。
“适用于这小块地的最大方块,也是适用于整块地的最大方块。”具体原理参见欧几里得算法:辗转相除,找到两个正整数的最大公约数。欧几里得算法百度百科
D&C的工作原理:
(1) 找出简单的基线条件;
(2) 确定如何缩小问题的规模,使其符合基线条件。
动手练习:
给定一个数字数组。 将这些数字相加,并返回结果。使用循环可以很方便完成任务。
循环实现数组里的元素相加(code)
#用循环实现数组里的数相加
def sum(arr):
total = 0
for i in arr:
total += i
return total
print(sum([5,4,3,2]))
#OUT: 14递归函数实现数组里的元素相加(code)
#用递归实现
def sum(arr):
b = arr.pop()
if arr == []: #基线条件
return b
else:
return b+sum(arr) #递归
print(sum([5,4,3,2]))
#OUT: 14涉及数组的递归函数时,基线条件通常是数组为空或只包含一个元素。
练习1
4.1 请编写前述sum函数的代码。
答:如上
4.2 编写一个递归函数来计算列表包含的元素数。
答:如上
4.3 找出列表中最大的数字。
答:可以用循环,递归的方法或者调用python的函数。(选择排序代码就不放了)
#1.循环
def findlargest(arr):
large = arr[0]
for i in range(len(arr)):
if arr[i]>=large:
large = arr[i]
return large
print(findlargest([1,2,3,4,5]))
#OUT: 5
#2.递归 https://blog.youkuaiyun.com/Sukiyou_xixi/article/details/95099292
def find_max(arr):
tmp = arr.pop(0)
if len(arr) == 0:
return tmp
max = find_max(arr)
if max > tmp:
return max
else:
return tmp
print(find_max([15, 10, 90, 200, 20]))
#OUT: 200
#3.python 内置函数
a = [1,2,3,4]
print(max(a))
#OUT: 4
4.4 还记得第1章介绍的二分查找吗?它也是一种分而治之算法。你能找出二分查找算法的基线条件和递归条件吗?
答:基线条件是查找的数正好是想要的数。递归条件就是,在符合条件那边继续折半查找。
4.2 快速排序
快速排序也是一种常见的排序算法,比选择排序快。
快速排序也采用了D&C,分而治之的策略:找基线条件,分解问题成基线条件去解决。递归的思想。
快速排序是怎么进行的?
第一步找基线条件。
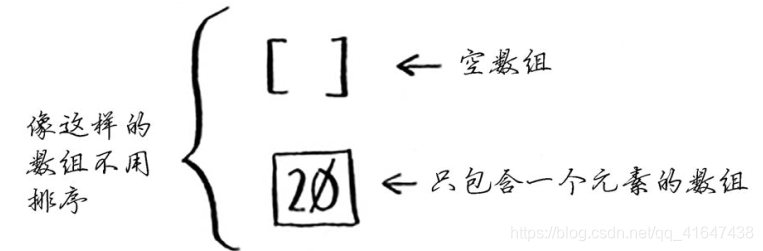
如果一个数组只有一个数,或者为空,则排序就原样返回,不需要排序。那么排序的基线条件就是数组为空或只包含一个元素。
如果数组有很多数,我们进行分解和归纳。
如果数组有两个数:

如果有三个数 :要使用D&C,分解数组,直到满足基线条件。

排序前,确定基准值(pivot),我们采用数组第一个元素作为基准值,根据基准值进行分区。所有小于基准值的元素放在它左边,大的放右边,
分区完,你有一个由所有小于基准值的数字组成的子数组;基准值;一个由所有大于基准值的数组组成的子数组。
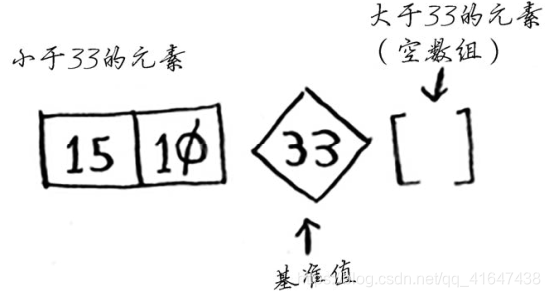
接着对左右两个数组再进行以上操作:以基准值再分左右区,直至返回一个元素。
其实 任何元素用作基准值都可行。你能对含有一个、两个、三个、四个元素的数组进行排序,同理以此类推,快速排序对任何长度的数组都管用。这里涉及到一个归纳证明的知识点。
快速排序代码
def quicksort(arr):
if len(arr)<2: #基线条件
return arr
else:
pivot = arr[0] #基准值
less = [i for i in arr[1:] if i<=pivot]
greater = [i for i in arr[1:] if i>pivot]
return quicksort(less)+[pivot]+quicksort(greater)
print(quicksort([10,5,2,3]))OUT:[2, 3, 5, 10]
4.3 再谈大 O 表示法
快速排序的独特之处在于,其速度取决于选择的基准值。讨论快速排序的大O表示之前,回顾一下一些查找和排序算法的常见的大O运行时间。
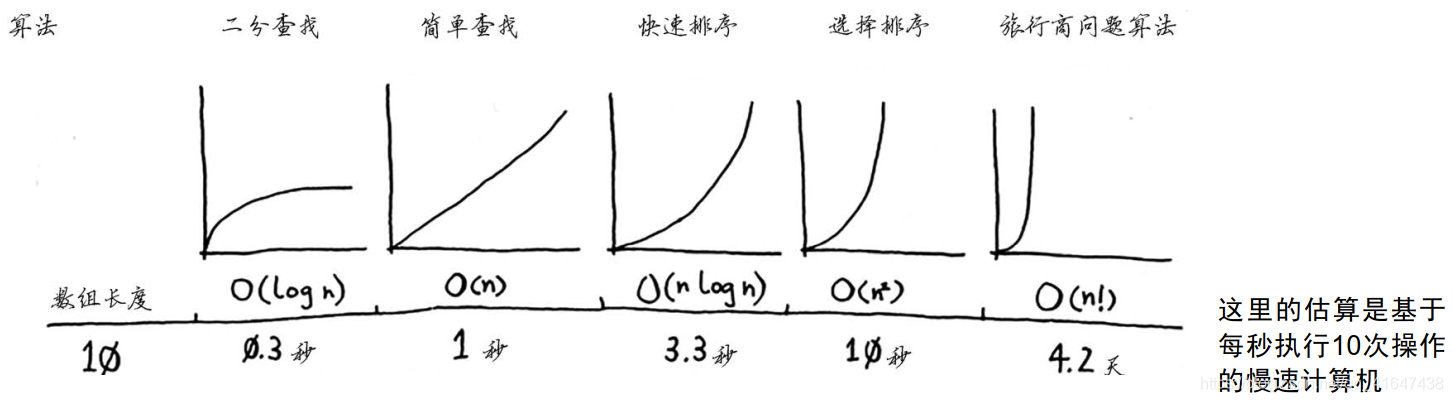
还有一种名为合并排序(merge sort)的排序算法,其运行时间为O(n log n),比选择排序快得多。
快速排序速度与基准值的选取有关,平均情况下快速排序的运行时间为O(n log n),最糟情况下,其运行时间为O()。
4.3.1 比较合并排序和快速排序
比如二分查找和简单查找:

暂且认为简单查找一次时间常量(算法所需的固定时间量)为10毫秒,二分查找时间常量是1秒。看起来好像是简单查找快,但如果要在包含40亿个元素的列表中查找:
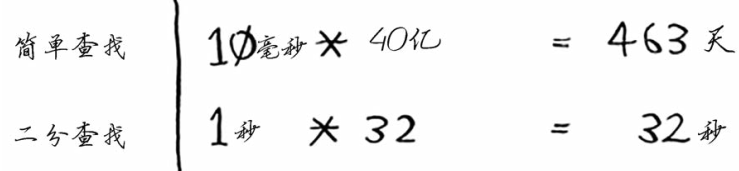
还是二分查找快的多。如果两个算法的大O表示不同,时间常量无关紧要。
但有时候,常量的影响可能很大。比如对快速查找和合并查找而言,快速查找的常量比合并查找小,因此如果它们的运行时间都为O(n log n),快速查找的速度将更快。实际上,快速查找的速度确实更快,因为相对于遇上最糟情况,它遇上平均情况的可能性要大得多。
什么是平均情况?最糟情况?
4.3.2 平均情况和最糟情况
使用快速排序,考虑两种基准值情况。
1.基准值每次都选择列表的第一个元素,且处理的数组是有序的。
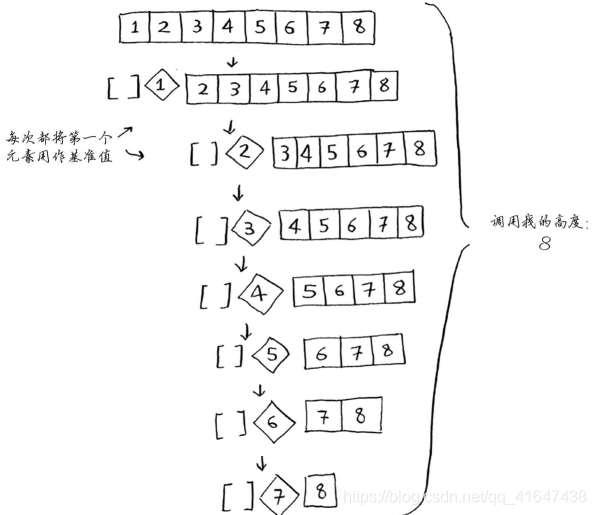
在此过程中,分区时,其中一个子数组始终为空,这导致调用栈非常长。这是最糟情况,栈长为O(n)。
2.也是上面的有序数组,但每次都选取数组的中间元素作为基准值。
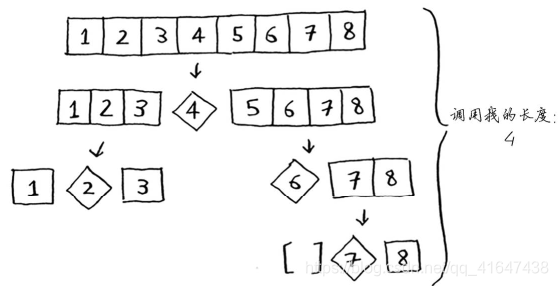
这样每次都将数组分成两半,所以不需要那么多递归调用。你很快就到达了基线条件,因此调用栈短得多。 这是最佳情况,栈长为O(logn)。
看第一种情况栈的第一层。你将一个元素用作基准值,并将其他的元素划分到两个子数组中。这涉及数组中的全部8个元素,因此该操作的时间为O(n)。实际上,在调用栈的每层都涉及O(n)个元素。
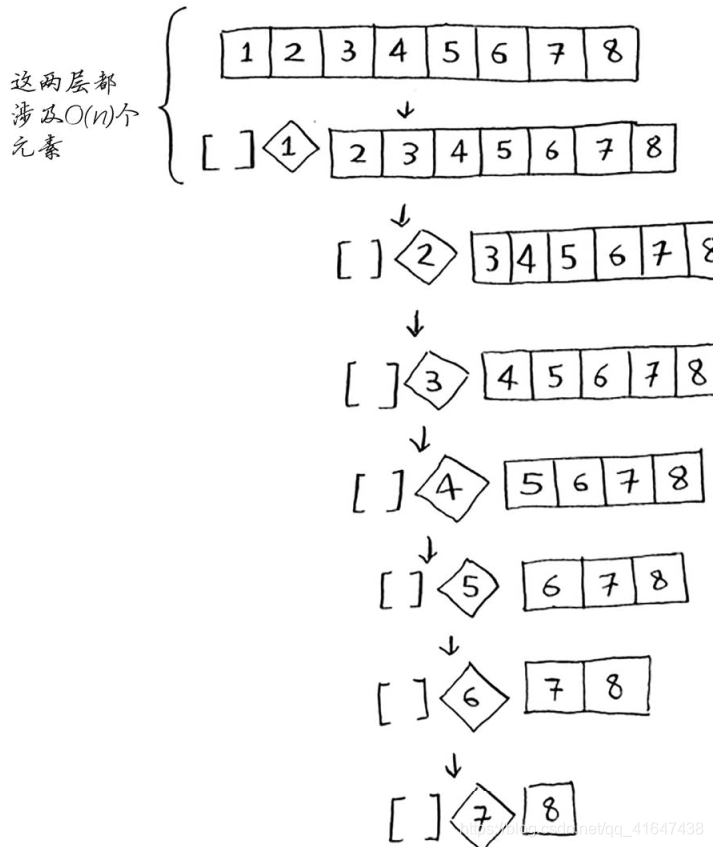
第二种情况,以中间元素作为基准,对半划分,每次也将涉及O(n)个元素。
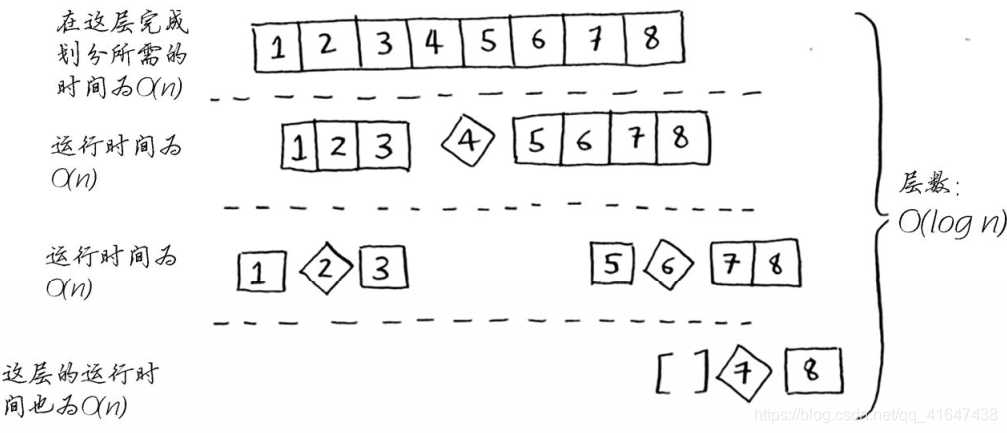
因此,完成每层所需的时间都为O(n)。
第一种情况,有O(n)层,因此该算法的运行时间为O(n) * O(n) = O(),最糟情况。
第二种情况,层数为O(log n)(用技术术语说,调用栈的高度为O(log n)),而每层需要的时间为O(n)。因此整个算法需要的时间为O(n) * O(log n) = O(n log n)。这就是最佳情况。
最佳情况也是平均情况。只要你每次都随机地选择一个数组元素作为基准值,快速排序的平均运行时间就将为O(n log n)。快速排序是最快的排序算法之一,也是D&C典范。
练习2
使用大O表示法时,下面各种操作都需要多长时间?
4.5 打印数组中每个元素的值。
答:O(n)
4.6 将数组中每个元素的值都乘以2。
答:O(n)
4.7 只将数组中第一个元素的值乘以2。
答:O(1)常量
4.8 根据数组包含的元素创建一个乘法表,即如果数组为[2, 3, 7, 8, 10],首先将每个元素 都乘以2,再将每个元素都乘以3,然后将每个元素都乘以7,以此类推。
答:O()
4.4 小结
D&C将问题逐步分解。使用D&C处理列表时,基线条件很可能是空数组或只包含一个元素的数组。
实现快速排序时,请随机地选择用作基准值的元素。快速排序的平均运行时间为O(n log n)。
大O表示法中的常量有时候事关重大,这就是快速排序比合并排序快的原因所在。
比较简单查找和二分查找时,常量几乎无关紧要,因为列表很长时,O(log n)的速度比O(n)快得多。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









