







目录
问题1: 如果某个topic有多个partition,怎么按照partition写入数据的?
问题1: kafka怎么快速查找到指定的一条message?(这一切都是建立在 offset 有序的基础上)
问题1: Consumer Group如何确定自己的coordinator是谁呢?
问题1:如果kafka中没有对应的offset信息(有可能offset被删除了),消费者应该从何处开始消费?
问题2: 如果consumer消费了5条消息,然后宕机,重新连接后从哪个位置开始消费?
问题3: 如果consumer第一次接入一个已经存在的topic,此时kafka中不存在这个consumer的消费offset信息,从哪开始消费?
QA:用db设计实现Kafka,表结构应该是咋样的?需要加什么索引
一、kafka的应用场景
1、解耦(A服务可以直接生产消息,然后不等B的结果,去做别的事。B异步的去消费)
2、异步
3、削峰
二、消息队列的通信模式
1、推拉模式
推拉模式的时候指的是 Comsumer 和 Broker 之间的交互。
推模式:消息从 Broker 推向 Consumer,即 Consumer 被动的接收消息,由 Broker 来主导消息的发送。
优点:
- 消息实时性高, Broker 接受完消息之后可以立马推送给 Consumer。
对于消费者使用来说更简单
缺点:
- 推送速率难以适应消费速率,推模式的目标就是以最快的速度推送消息,消费者可能消费不过来。
拉模式:Consumer 主动向 Broker 请求拉取消息,即 Broker 被动的发送消息给 Consumer。
优点:
- 消费者可以根据自身的情况来发起拉取消息的请求。
- 拉模式下 Broker 就相对轻松了,它只管存生产者发来的消息。
- 拉模式可以更合适的进行消息的批量发送
缺点:
- 消息延迟,毕竟是消费者去拉取消息,但是消费者怎么知道消息到了呢。所以它只能不断地拉取,但是又不能很频繁地请求,太频繁了就变成消费者在攻击 Broker 了。因此需要降低请求的频率,比如隔个 2 秒请求一次,你看着消息就很有可能延迟 2 秒了。
- 消息忙请求,比如消息隔了几个小时才有,那么在几个小时之内消费者的请求都是无效的,在做无用功。
2、Kafka拉模式实现原理
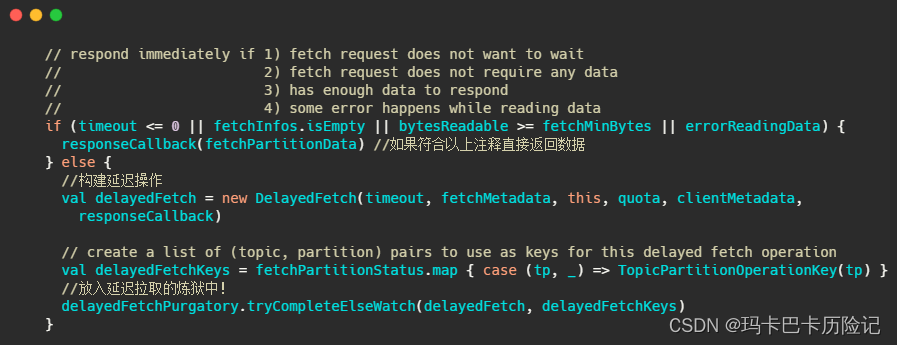
RocketMQ 和 Kafka 都是利用“长轮询”来实现拉模式。Kafka 在拉请求中有参数,可以使得消费者请求在 “长轮询” 中阻塞等待。简单的说就是消费者去 Broker 拉消息,定义了一个超时时间。拉消息时,如果有的话马上返回消息,如果没有的话消费者等着直到超时,然后再次发起拉消息请求。
并且 Broker 也得配合,如果消费者请求过来,有消息肯定马上返回,没有消息那就建立一个延迟操作,等条件满足了再返回。
参考:消息队列之推还是拉,RocketMQ 和 Kafka 是如何做的?_kafka_yes_InfoQ写作社区
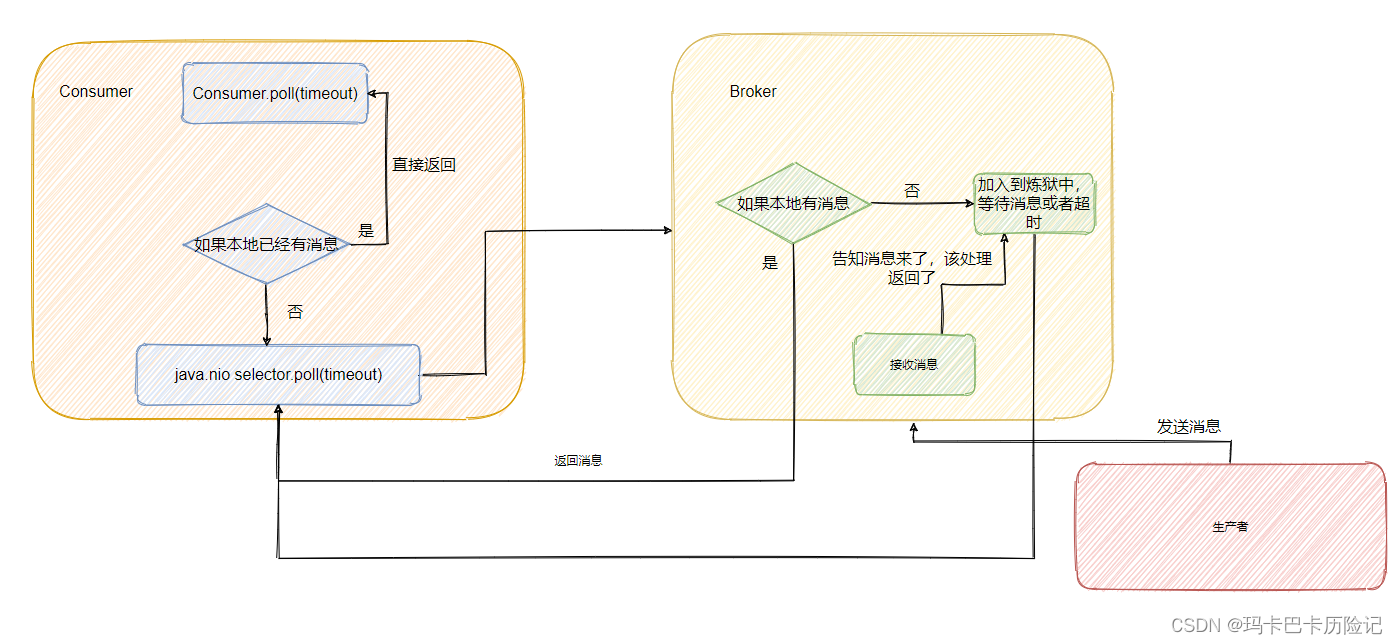
2.1、消费端实现逻辑
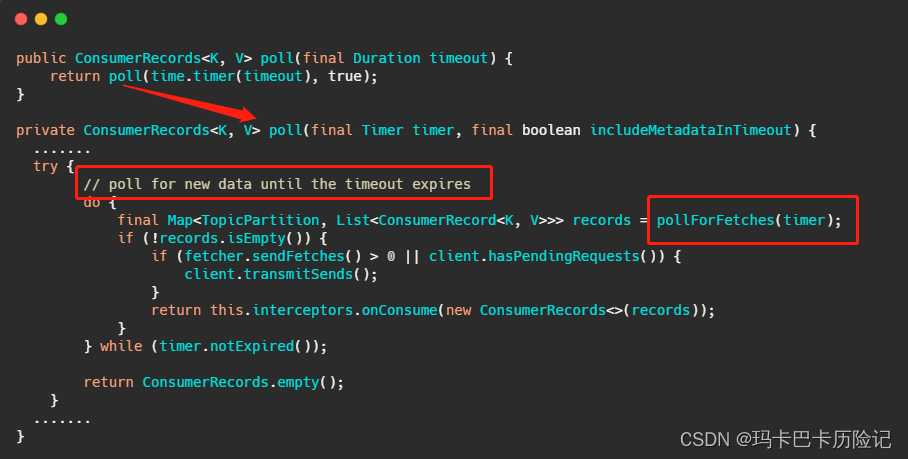
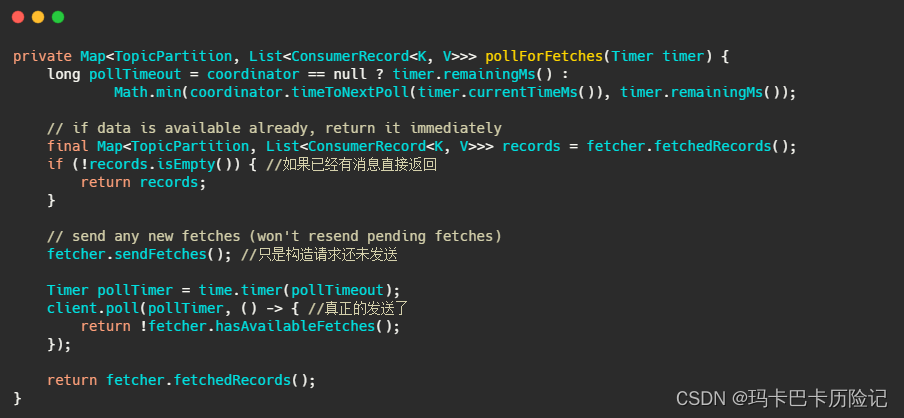
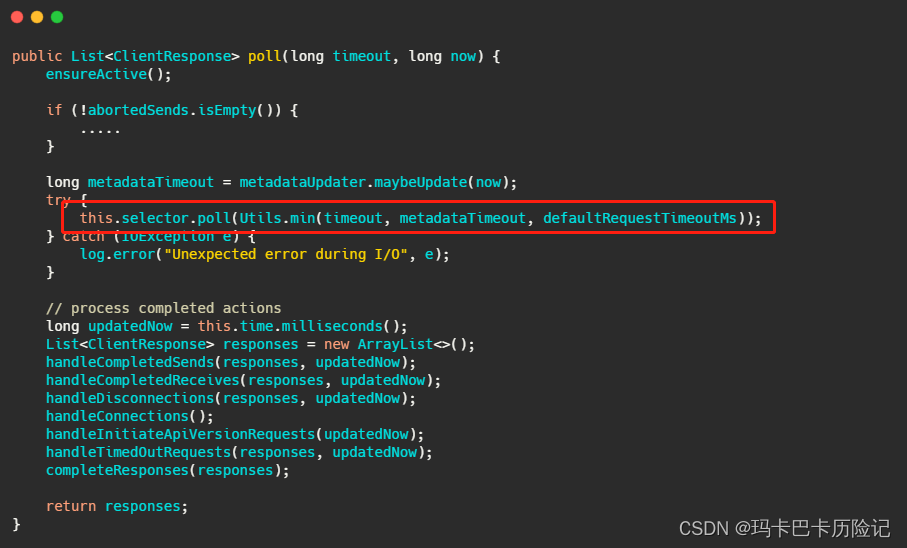
client.poll() 方法如下。实际调用的是kafka的包装过的selector。最终会调用到 Java nio的select(timeout)
2.2、Kafka实现逻辑
KafkaApis.scala 文件的 handle方法:
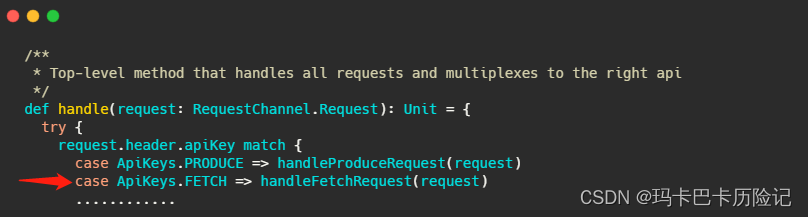
handleFetchRequest的重要部分源码如下:
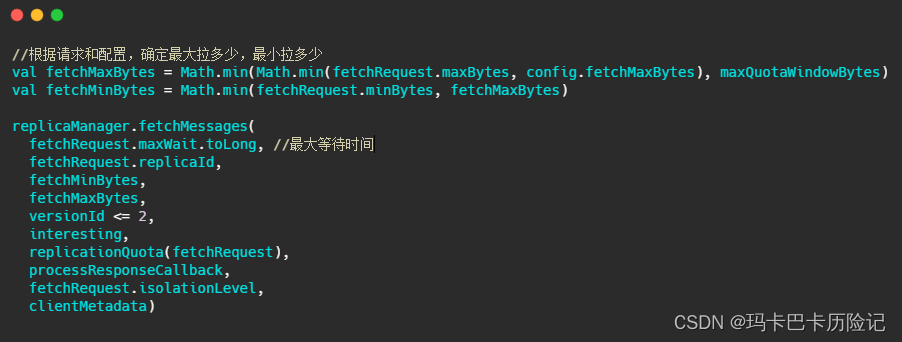
fetchMessages实现如下:
3、点对点和发布订阅
在点对点系统中,消息保留在队列中。一个或者多个消费者可以消费队列中的消息,但是特定消息只能由一个消费者消费,一旦该消息被一个消费者消费,他就会从队列中消失[不会将消息落磁盘]。
在发布订阅系统中,消息被保存在topic中。与点对点的不同的是,消费者可以订阅多个topic,一个topic中的消息可供多个消费组消费。
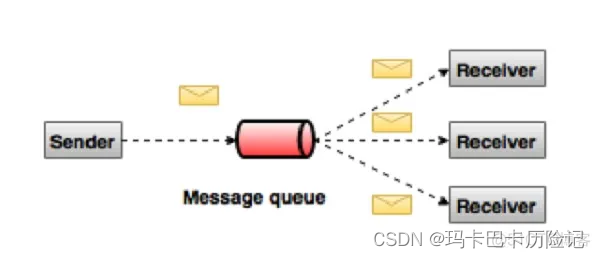
Kafka是一种高吞吐量的分布式发布订阅消息系统。具有高性能、持久化、多副本备份、横向扩展能力。
QA:kafka怎么实现点对点?
参考:Kafka如何实现点对点消息和发布订阅消息?-阿里云开发者社区
实现点对点:通过不同的消费者消费不同的partiton实现。
三、kafka的工作原理
1、基本概念及结构
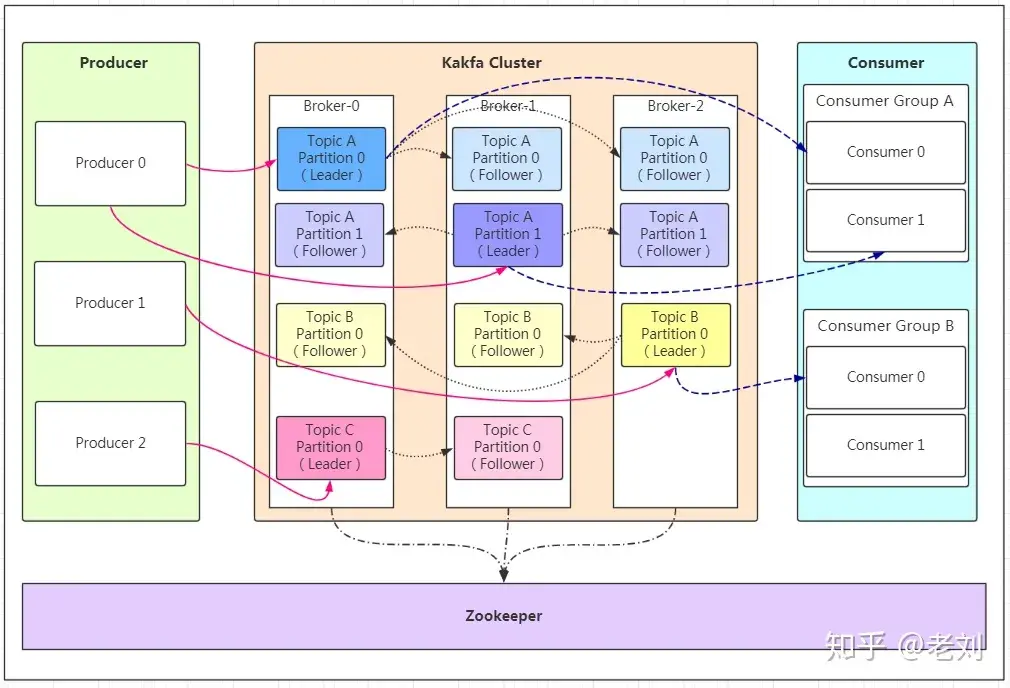
kafka集群结构图
producer:消息的生产者
consumer:消息的消费者
kafka cluster:
Broker:是kafka的实例,每个服务器上有一个或者多个Broker。假设一台机器一个Broker实例,每个Broker都有一个不重复的编号
Topic:消息的主题,可以理解为消息的分类。kafka的数据就保存在topic中。在每个Broker上都可以创建多个Topic。
Partition:Topic的分区。每个Topic可以有多个分区。分区的作用是做负载,提高kafka的吞吐量。同一个Topic的每个分区中的数据是不重复的,partition的表现形式是一个一个文件夹。每个partition只能被一个consumer消费。
Replication:每一个分区有多个副本,当Leader故障时,会选择一个follower成为leader。kafka的最大默认副本数是10,且副本的数量不能 > broker的数量。每个partition的副本和leader绝对不在同一台机器上。
2、kafka生产消息的流程
Producer在写入数据的时候永远的找leader,不会直接将数据写入follower!
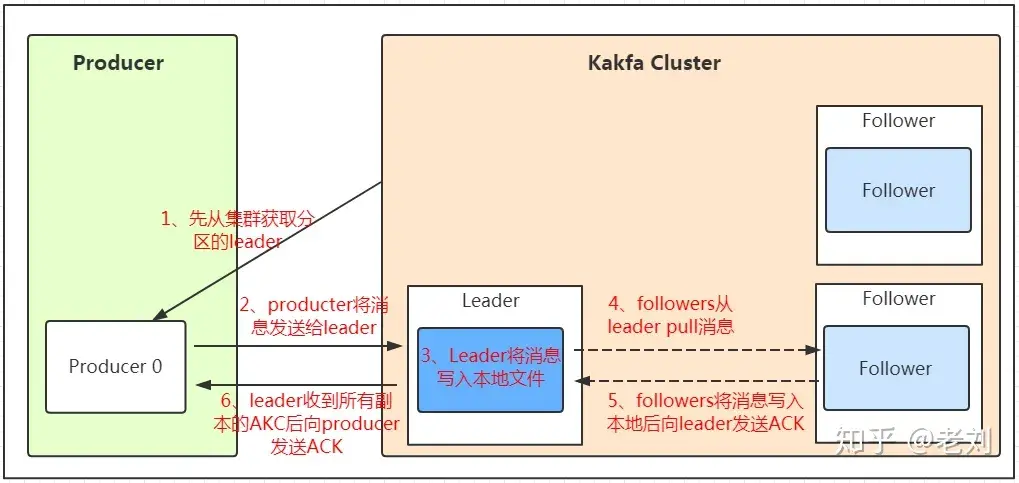
kafka发送消息流程图
1、producer先从集群获取分区的leader
2、producer将消息发送给分区的leader
3、leader将消息写入本地文件
4、follower从leader poll拉取消息
5、follower将消息写入本地后,向leader发送ack
6、leader收到所有副本
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









