




 本文介绍了在大数据背景下,如何利用哈希算法进行图像检索。通过对cifar-10数据集的实验,展示了DSH(Density Sensitive Hashing)哈希算法的工作原理,包括超平面划分、k-means聚类、近邻组对形成以及基于熵值的超平面选择策略。DSH旨在挖掘数据内部结构,优化哈希码的生成,以提高图像检索的效率和准确性。
本文介绍了在大数据背景下,如何利用哈希算法进行图像检索。通过对cifar-10数据集的实验,展示了DSH(Density Sensitive Hashing)哈希算法的工作原理,包括超平面划分、k-means聚类、近邻组对形成以及基于熵值的超平面选择策略。DSH旨在挖掘数据内部结构,优化哈希码的生成,以提高图像检索的效率和准确性。
一、图像检索中哈希算法的使用过程:
1.在成绩管理系统中,我们知道学生的姓名和数学语文成绩,从数据中匹配这个记录,找到该学生,每次匹配需要比较姓名,数学成绩,语文成绩三个字段,数据维度较低,对于这种小量数据,我们可以线性匹配都可以解决。
2.小的图片数据库中,我们可以为每张图片加上标签,例如一张风景照,我么可以标记山,水,湖泊,房屋等等标签,我们搜索房屋关键字时,可以到数据库中去匹配,从而找到用户需要的图片。
3.但是在这个大数据时代,每天产生数以亿计的图片,并且对于图片这种高维数据,依然使用传统的方法已经很难解决检索问题。对于这种大规模数据的检索,近似近邻搜索可以达到很好的效果,它平衡了效率与准确率,使检索达到很好的效果。主要思想是,将每一张图片用一个相对较短的01编码表示,例如长度为64,128的编码,这个编码依然近似保持了图片空间的物理近邻关系。当用户上传一张图片时,使用哈希函数将它转化为01编码,然后计算这条编码与数据库中所有图片的编码进行距离计算(此时使用汉明距离计算)即是将该图片的二进制编码,与数据库中所有二进制编码进行异或运算,其中1的个数即为距离,对所有的距离进行排序,选择前100个距离最近的作为相近的图片,然后通过索引找到原始图片显示出来。
4.主要过程:
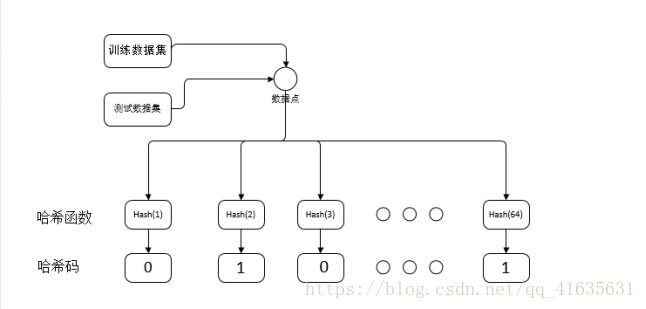
在做基于哈希的图像检索时,我使用cifar-10数据集,首先对该数据集提取gist特征,每张图片用一个向量表示,例如提取512个特征,则每张图片就使用一个512维的向量表示,一万张图片最后形成:10000*512的矩阵。将数据划分为训练集和测试集,训练集用来训练哈希函数。测试集用来测试查准率与查全率。根据训练集训练出哈希函数。将训练数据通过哈希函数转化为哈希函码,将测试数据转化为哈希码。计算测试数据到训练数据的距离,排序,选择距离最小的前100张图片,搜出来的100张图片就是近似近邻的图片。哈希码的形成过程如下图:
二、DSH哈希算法
密度敏感哈希可以看作时局部敏感哈希
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









