









 本文深入解析MMDetection框架中内置的损失函数,涵盖分类与回归任务,如CrossEntropyLoss、BalancedL1Loss及FocalLoss等,探讨其应用场景与调整方法。
本文深入解析MMDetection框架中内置的损失函数,涵盖分类与回归任务,如CrossEntropyLoss、BalancedL1Loss及FocalLoss等,探讨其应用场景与调整方法。
1、MMdetection内置损失函数
1、CrossEntropyLoss(分类任务)
cross_entropy 函数用于计算交叉熵损失。交叉熵损失是一种常用的分类任务损失函数,用于衡量预测类别与真实类别之间的差异
@LOSSES.register_module()
class CrossEntropyLoss(nn.Module):
def __init__(self,
use_sigmoid=False,
use_mask=False,
reduction='mean',
class_weight=None,
ignore_index=None,
loss_weight=1.0,
avg_non_ignore=False):
"""CrossEntropyLoss.
Args:
use_sigmoid (bool, optional): Whether the prediction uses sigmoid
of softmax. Defaults to False.
use_mask (bool, optional): Whether to use mask cross entropy loss.
Defaults to False.
reduction (str, optional): . Defaults to 'mean'.
Options are "none", "mean" and "sum".
class_weight (list[float], optional): Weight of each class.
Defaults to None.
ignore_index (int | None): The label index to be ignored.
Defaults to None.
loss_weight (float, optional): Weight of the loss. Defaults to 1.0.
avg_non_ignore (bool): The flag decides to whether the loss is
only averaged over non-ignored targets. Default: False.
"""
super(CrossEntropyLoss, self).__init__()
assert (use_sigmoid is False) or (use_mask is False)
self.use_sigmoid = use_sigmoid
self.use_mask = use_mask
self.reduction = reduction
self.loss_weight = loss_weight
self.class_weight = class_weight
self.ignore_index = ignore_index
self.avg_non_ignore = avg_non_ignore
if ((ignore_index is not None) and not self.avg_non_ignore
and self.reduction == 'mean'):
warnings.warn(
'Default ``avg_non_ignore`` is False, if you would like to '
'ignore the certain label and average loss over non-ignore '
'labels, which is the same with PyTorch official '
'cross_entropy, set ``avg_non_ignore=True``.')
if self.use_sigmoid:
self.cls_criterion = binary_cross_entropy
elif self.use_mask:
self.cls_criterion = mask_cross_entropy
else:
self.cls_criterion = cross_entropy
def extra_repr(self):
"""Extra repr."""
s = f'avg_non_ignore={self.avg_non_ignore}'
return s
def forward(self,
cls_score,
label,
weight=None,
avg_factor=None,
reduction_override=None,
ignore_index=None,
**kwargs):
"""Forward function.
Args:
cls_score (torch.Tensor): The prediction.
label (torch.Tensor): The learning label of the prediction.
weight (torch.Tensor, optional): Sample-wise loss weight.
avg_factor (int, optional): Average factor that is used to average
the loss. Defaults to None.
reduction_override (str, optional): The method used to reduce the
loss. Options are "none", "mean" and "sum".
ignore_index (int | None): The label index to be ignored.
If not None, it will override the default value. Default: None.
Returns:
torch.Tensor: The calculated loss.
"""
assert reduction_override in (None, 'none', 'mean', 'sum')
reduction = (
reduction_override if reduction_override else self.reduction)
if ignore_index is None:
ignore_index = self.ignore_index
if self.class_weight is not None:
class_weight = cls_score.new_tensor(
self.class_weight, device=cls_score.device)
else:
class_weight = None
loss_cls = self.loss_weight * self.cls_criterion(
cls_score,
label,
weight,
class_weight=class_weight,
reduction=reduction,
avg_factor=avg_factor,
ignore_index=ignore_index,
avg_non_ignore=self.avg_non_ignore,
**kwargs)
return loss_cls
2、 BalancedL1Loss(回归任务)
Balanced L1 Loss 是一种改进的 L1 损失函数,主要用于回归任务,尤其是在目标检测任务中。它通过引入平衡因子来处理目标检测中的边界框回归问题,这样可以有效地减少对异常值的实力。
class BalancedL1Loss(nn.Module):
"""Balanced L1 Loss.
arXiv: https://arxiv.org/pdf/1904.02701.pdf (CVPR 2019)
Args:
alpha (float): The denominator ``alpha`` in the balanced L1 loss.
Defaults to 0.5.
gamma (float): The ``gamma`` in the balanced L1 loss. Defaults to 1.5.
beta (float, optional): The loss is a piecewise function of prediction
and target. ``beta`` serves as a threshold for the difference
between the prediction and target. Defaults to 1.0.
reduction (str, optional): The method that reduces the loss to a
scalar. Options are "none", "mean" and "sum".
loss_weight (float, optional): The weight of the loss. Defaults to 1.0
"""
def __init__(self,
alpha=0.5,
gamma=1.5,
beta=1.0,
reduction='mean',
loss_weight=1.0):
super(BalancedL1Loss, self).__init__()
self.alpha = alpha
self.gamma = gamma
self.beta = beta
self.reduction = reduction
self.loss_weight = loss_weight
def forward(self,
pred,
target,
weight=None,
avg_factor=None,
reduction_override=None,
**kwargs):
"""Forward function of loss.
Args:
pred (torch.Tensor): The prediction with shape (N, 4).
target (torch.Tensor): The learning target of the prediction with
shape (N, 4).
weight (torch.Tensor, optional): Sample-wise loss weight with
shape (N, ).
avg_factor (int, optional): Average factor that is used to average
the loss. Defaults to None.
reduction_override (str, optional): The reduction method used to
override the original reduction method of the loss.
Options are "none", "mean" and "sum".
Returns:
torch.Tensor: The calculated loss
"""
assert reduction_override in (None, 'none', 'mean', 'sum')
reduction = (
reduction_override if reduction_override else self.reduction)
loss_bbox = self.loss_weight * balanced_l1_loss(
pred,
target,
weight,
alpha=self.alpha,
gamma=self.gamma,
beta=self.beta,
reduction=reduction,
avg_factor=avg_factor,
**kwargs)
return loss_bbox
应用场景
目标检测:
在目标检测中,平衡 L1
平衡 L1 损失可以有效地对目标检测中的小目标和大目标进行区分,使得训练过程对小目标更为敏感,同时对大目标的误差处理更加稳健。
回归任务:
在回归任务中,平衡 L1 损失也可以用于处理异常值和数据噪声。当数据中存在一些异常值时,平衡 L1 损失可以有效地减少这些异常值对损失的影响,从而提升回归模型的鲁棒性和稳定性。
计算机视觉:
除了目标检测,平衡 L1 损失还可以用于其他计算机视觉任务,如图像分割、姿态估计等。这些任务中的目标位置或边界的回归问题也可以受益于平衡 L1 损失的设计,特别是在存在大量噪声或异常值的情况下。
总之,Balanced L1 Loss 通过结合 L1 损失和一个平衡机制,使得损失函数在处理不同误差范围时表现出更好的鲁棒性。这使得它在目标检测和回归任务中非常有用,特别是在面对异常值和数据噪声时。
3、L1Loss
@LOSSES.register_module()
class L1Loss(nn.Module):
"""L1 loss.
Args:
reduction (str, optional): The method to reduce the loss.
Options are "none", "mean" and "sum".
loss_weight (float, optional): The weight of loss.
"""
def __init__(self, reduction='mean', loss_weight=1.0):
super(L1Loss, self).__init__()
self.reduction = reduction
self.loss_weight = loss_weight
def forward(self,
pred,
target,
weight=None,
avg_factor=None,
reduction_override=None):
"""Forward function.
Args:
pred (torch.Tensor): The prediction.
target (torch.Tensor): The learning target of the prediction.
weight (torch.Tensor, optional): The weight of loss for each
prediction. Defaults to None.
avg_factor (int, optional): Average factor that is used to average
the loss. Defaults to None.
reduction_override (str, optional): The reduction method used to
override the original reduction method of the loss.
Defaults to None.
"""
assert reduction_override in (None, 'none', 'mean', 'sum')
reduction = (
reduction_override if reduction_override else self.reduction)
loss_bbox = self.loss_weight * l1_loss(
pred, target, weight, reduction=reduction, avg_factor=avg_factor)
return loss_bbox
4、SmoothL1Loss(回归任务)
Smooth L1 Loss 是一种常用于回归任务中的损失函数,尤其是在目标检测中的边界框回归任务。它通过结合 L1 损失和 L2 损失的特点,平滑了传统 L1 损失的尖锐性,从而提供了一种更为稳定的损失计算方式。

class SmoothL1Loss(nn.Module):
"""Smooth L1 loss.
Args:
beta (float, optional): The threshold in the piecewise function.
Defaults to 1.0.
reduction (str, optional): The method to reduce the loss.
Options are "none", "mean" and "sum". Defaults to "mean".
loss_weight (float, optional): The weight of loss.
"""
def __init__(self, beta=1.0, reduction='mean', loss_weight=1.0):
super(SmoothL1Loss, self).__init__()
self.beta = beta
self.reduction = reduction
self.loss_weight = loss_weight
def forward(self,
pred,
target,
weight=None,
avg_factor=None,
reduction_override=None,
**kwargs):
"""Forward function.
Args:
pred (torch.Tensor): The prediction.
target (torch.Tensor): The learning target of the prediction.
weight (torch.Tensor, optional): The weight of loss for each
prediction. Defaults to None.
avg_factor (int, optional): Average factor that is used to average
the loss. Defaults to None.
reduction_override (str, optional): The reduction method used to
override the original reduction method of the loss.
Defaults to None.
"""
assert reduction_override in (None, 'none', 'mean', 'sum')
reduction = (
reduction_override if reduction_override else self.reduction)
loss_bbox = self.loss_weight * smooth_l1_loss(
pred,
target,
weight,
beta=self.beta,
reduction=reduction,
avg_factor=avg_factor,
**kwargs)
return loss_bbox
应用场景
目标检测:
在目标检测中,Smooth L1 Loss 通常用于边界框回归任务。它可以有效地处理目标框的回归问题,特别是当目标框的大小差异较大时,平滑 L1 损失能更好地平衡回归误差的影响。
回归任务:
在回归任务中,Smooth L1 Loss 提供了一种平滑的损失计算方式,可以减少异常值对回归模型的影响,从而提升模型的稳定性。
计算机视觉:
在计算机视觉领域的其他任务中,如姿态估计、图像分割等,Smooth L1 Loss 也可以用于回归问题,特别是在需要处理预测值和真实值之间的差异时。
总之,Smooth L1 Loss 通过结合 L1 和 L2 损失的优点,提供了一种在小误差和大误差范围内都表现良好的损失函数。它在目标检测和回归任务中非常有用,尤其是在处理异常值和数据噪声时。
4、FocalLoss(分类任务,正负样本平衡机制)
Focal Loss 是为了解决目标检测中前景和背景类别不平衡问题而提出的一种损失函数。在常规的分类任务中,当负样本远多于正样本时,模型的训练可能会被大量的负样本主导,导致对少数正样本的学习效果较差。Focal Loss 通过调整损失函数,使得模型能够更加关注难分类的样本,从
Focal Loss 的核心思想是对标准交叉熵损失进行调制,通过引入一个调整因子(modulating factor)来降低容易分类样本的损失贡献,增加难分类
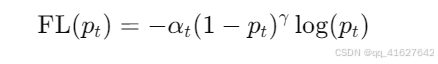
class FocalLoss(nn.Module):
def __init__(self,
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
reduction='mean',
loss_weight=1.0,
activated=False):
"""`Focal Loss <https://arxiv.org/abs/1708.02002>`_
Args:
use_sigmoid (bool, optional): Whether to the prediction is
used for sigmoid or softmax. Defaults to True.
gamma (float, optional): The gamma for calculating the modulating
factor. Defaults to 2.0.
alpha (float, optional): A balanced form for Focal Loss.
Defaults to 0.25.
reduction (str, optional): The method used to reduce the loss into
a scalar. Defaults to 'mean'. Options are "none", "mean" and
"sum".
loss_weight (float, optional): Weight of loss. Defaults to 1.0.
activated (bool, optional): Whether the input is activated.
If True, it means the input has been activated and can be
treated as probabilities. Else, it should be treated as logits.
Defaults to False.
"""
super(FocalLoss, self).__init__()
assert use_sigmoid is True, 'Only sigmoid focal loss supported now.'
self.use_sigmoid = use_sigmoid
self.gamma = gamma
self.alpha = alpha
self.reduction = reduction
self.loss_weight = loss_weight
self.activated = activated
def forward(self,
pred,
target,
weight=None,
avg_factor=None,
reduction_override=None):
"""Forward function.
Args:
pred (torch.Tensor): The prediction.
target (torch.Tensor): The learning label of the prediction.
weight (torch.Tensor, optional): The weight of loss for each
prediction. Defaults to None.
avg_factor (int, optional): Average factor that is used to average
the loss. Defaults to None.
reduction_override (str, optional): The reduction method used to
override the original reduction method of the loss.
Options are "none", "mean" and "sum".
Returns:
torch.Tensor: The calculated loss
"""
assert reduction_override in (None, 'none', 'mean', 'sum')
reduction = (
reduction_override if reduction_override else self.reduction)
if self.use_sigmoid:
if self.activated:
calculate_loss_func = py_focal_loss_with_prob
else:
if torch.cuda.is_available() and pred.is_cuda:
calculate_loss_func = sigmoid_focal_loss
else:
num_classes = pred.size(1)
target = F.one_hot(target, num_classes=num_classes + 1)
target = target[:, :num_classes]
calculate_loss_func = py_sigmoid_focal_loss
loss_cls = self.loss_weight * calculate_loss_func(
pred,
target,
weight,
gamma=self.gamma,
alpha=self.alpha,
reduction=reduction,
avg_factor=avg_factor)
else:
raise NotImplementedError
return loss_cls
应用场景
目标检测:
在目标检测中,正样本(目标)通常会远缺失负样本(背景),这种不平衡导致标准的交叉熵损失无法有效训练模型。焦点损失通过容易调整分类样本的损失贡献,使得模型受到更多关注难分类的正样本,从而提高目标检测的性能。
分类任务:
在一般的分类任务中,当类别不平衡严重时,也可以使用 Focal Loss 来改善模型对少数类别的分类效果。
关系结构:
在分割任务中,各类别像素数量不平衡也可以采用Focal Loss,通过增加难分类像素的损失权重,提升模型对小目标或难分类区域的分割效果。
总之,Focal Loss通过引入调节因子,使得模型在训练过程中更加关注难分类的样本,能够有效地解决类别不平衡问题,在目标检测和其他分类任务中具有广泛的应用。
5、AssociativeEmbeddingLoss(多目标检测和关键点检测任务的损失函数)
6、DiceLoss(图像分割)
class DiceLoss(nn.Module):
def __init__(self,
use_sigmoid=True,
activate=True,
reduction='mean',
naive_dice=False,
loss_weight=1.0,
eps=1e-3):
"""Compute dice loss.
Args:
use_sigmoid (bool, optional): Whether to the prediction is
used for sigmoid or softmax. Defaults to True.
activate (bool): Whether to activate the predictions inside,
this will disable the inside sigmoid operation.
Defaults to True.
reduction (str, optional): The method used
to reduce the loss. Options are "none",
"mean" and "sum". Defaults to 'mean'.
naive_dice (bool, optional): If false, use the dice
loss defined in the V-Net paper, otherwise, use the
naive dice loss in which the power of the number in the
denominator is the first power instead of the second
power. Defaults to False.
loss_weight (float, optional): Weight of loss. Defaults to 1.0.
eps (float): Avoid dividing by zero. Defaults to 1e-3.
"""
super(DiceLoss, self).__init__()
self.use_sigmoid = use_sigmoid
self.reduction = reduction
self.naive_dice = naive_dice
self.loss_weight = loss_weight
self.eps = eps
self.activate = activate
def forward(self,
pred,
target,
weight=None,
reduction_override=None,
avg_factor=None):
"""Forward function.
Args:
pred (torch.Tensor): The prediction, has a shape (n, *).
target (torch.Tensor): The label of the prediction,
shape (n, *), same shape of pred.
weight (torch.Tensor, optional): The weight of loss for each
prediction, has a shape (n,). Defaults to None.
avg_factor (int, optional): Average factor that is used to average
the loss. Defaults to None.
reduction_override (str, optional): The reduction method used to
override the original reduction method of the loss.
Options are "none", "mean" and "sum".
Returns:
torch.Tensor: The calculated loss
"""
assert reduction_override in (None, 'none', 'mean', 'sum')
reduction = (
reduction_override if reduction_override else self.reduction)
if self.activate:
if self.use_sigmoid:
pred = pred.sigmoid()
else:
raise NotImplementedError
loss = self.loss_weight * dice_loss(
pred,
target,
weight,
eps=self.eps,
reduction=reduction,
naive_dice=self.naive_dice,
avg_factor=avg_factor)
return loss
7、GaussianFocalLoss高斯焦点损失(图像分类)
算法原理
高斯焦点损失的目的是解决类别不平衡问题,使得模型更加关注难以检测的目标。其损失函数通过
class GaussianFocalLoss(nn.Module):
"""GaussianFocalLoss is a variant of focal loss.
More details can be found in the `paper
<https://arxiv.org/abs/1808.01244>`_
Code is modified from `kp_utils.py
<https://github.com/princeton-vl/CornerNet/blob/master/models/py_utils/kp_utils.py#L152>`_ # noqa: E501
Please notice that the target in GaussianFocalLoss is a gaussian heatmap,
not 0/1 binary target.
Args:
alpha (float): Power of prediction.
gamma (float): Power of target for negative samples.
reduction (str): Options are "none", "mean" and "sum".
loss_weight (float): Loss weight of current loss.
"""
def __init__(self,
alpha=2.0,
gamma=4.0,
reduction='mean',
loss_weight=1.0):
super(GaussianFocalLoss, self).__init__()
self.alpha = alpha
self.gamma = gamma
self.reduction = reduction
self.loss_weight = loss_weight
def forward(self,
pred,
target,
weight=None,
avg_factor=None,
reduction_override=None):
"""Forward function.
Args:
pred (torch.Tensor): The prediction.
target (torch.Tensor): The learning target of the prediction
in gaussian distribution.
weight (torch.Tensor, optional): The weight of loss for each
prediction. Defaults to None.
avg_factor (int, optional): Average factor that is used to average
the loss. Defaults to None.
reduction_override (str, optional): The reduction method used to
override the original reduction method of the loss.
Defaults to None.
"""
assert reduction_override in (None, 'none', 'mean', 'sum')
reduction = (
reduction_override if reduction_override else self.reduction)
loss_reg = self.loss_weight * gaussian_focal_loss(
pred,
target,
weight,
alpha=self.alpha,
gamma=self.gamma,
reduction=reduction,
avg_factor=avg_factor)
return loss_reg
应用场景
目标检测:高斯焦点损失主要
人群统计:在人群统计任务中,可以将目标区域表示为高斯热力图,通过高斯焦点损失计算损失,有助于提高人群中的目标检测效果
实例分割:在实例分割任务中,高斯焦点损失能够增强模型对目标区域的关注,提高分割精度。
Gaussian Focal Loss的应用场景
- 目标检测: - CornerNet:Gaussian Focal Loss在CornerNet中用于检测物体的角点,将角点预测为高斯热图的形式,以提高检测精度和识别率。 - CenterNet:在CenterNet中,对于检测物体的中心点,通过高斯热图形式的预测,达到了对小物体和密集场景的检测能力。
-
- Gaussian Focal Loss的应用场景 1. 关键点检测: - CornerNet:在CornerNet中,使用Gaussian Focal Loss来训练模型来检测目标的角点。通过生成高斯热图作为目标标签,该损失函数可以更好地定位目标目标的关键点,提高检测精度。 - 姿势估计:在人体姿势估计任务中,利用高斯焦点损失来定位人体的关键点(如关节、头部等),提高关键点检测的准确性
8、QualityFocalLoss质量焦点损失 (QFL)(密集目标检测任务的损失函数)(分类损失,正负样本平横机制)
class QualityFocalLoss(nn.Module):
r"""Quality Focal Loss (QFL) is a variant of `Generalized Focal Loss:
Learning Qualified and Distributed Bounding Boxes for Dense Object
Detection <https://arxiv.org/abs/2006.04388>`_.
Args:
use_sigmoid (bool): Whether sigmoid operation is conducted in QFL.
Defaults to True.
beta (float): The beta parameter for calculating the modulating factor.
Defaults to 2.0.
reduction (str): Options are "none", "mean" and "sum".
loss_weight (float): Loss weight of current loss.
activated (bool, optional): Whether the input is activated.
If True, it means the input has been activated and can be
treated as probabilities. Else, it should be treated as logits.
Defaults to False.
"""
def __init__(self,
use_sigmoid=True,
beta=2.0,
reduction='mean',
loss_weight=1.0,
activated=False):
super(QualityFocalLoss, self).__init__()
assert use_sigmoid is True, 'Only sigmoid in QFL supported now.'
self.use_sigmoid = use_sigmoid
self.beta = beta
self.reduction = reduction
self.loss_weight = loss_weight
self.activated = activated
def forward(self,
pred,
target,
weight=None,
avg_factor=None,
reduction_override=None):
"""Forward function.
Args:
pred (torch.Tensor): Predicted joint representation of
classification and quality (IoU) estimation with shape (N, C),
C is the number of classes.
target (tuple([torch.Tensor])): Target category label with shape
(N,) and target quality label with shape (N,).
weight (torch.Tensor, optional): The weight of loss for each
prediction. Defaults to None.
avg_factor (int, optional): Average factor that is used to average
the loss. Defaults to None.
reduction_override (str, optional): The reduction method used to
override the original reduction method of the loss.
Defaults to None.
"""
assert reduction_override in (None, 'none', 'mean', 'sum')
reduction = (
reduction_override if reduction_override else self.reduction)
if self.use_sigmoid:
if self.activated:
calculate_loss_func = quality_focal_loss_with_prob
else:
calculate_loss_func = quality_focal_loss
loss_cls = self.loss_weight * calculate_loss_func(
pred,
target,
weight,
beta=self.beta,
reduction=reduction,
avg_factor=avg_factor)
else:
raise NotImplementedError
return loss_cls
Quality Focal Loss (QFL) 的应用场景 Quality Focal Loss (QFL) 是一个专门用于处理密集目标检测任务的损失函数。它通过将目标检测中的分类损失和目标质量(通常是IoU)结合起来,改进了标准Focal Loss,设置能够更好地处理目标检测中的各种挑战。以下是QFL的主要应用场景: 1. 密集目标检测: - 目标检测:QFL非常适合用于密集目标检测任务,例如在图像中检测多个目标(如车辆、行人、动物等)。它能够处理目标之间的重叠问题,并且在处理小物体时比传统- 实例分割:在实例分割任务中,QFL可以提高对密集分割区域的检测精度,尤其是在处理目标重叠和稀疏的情况下。 2. **自动驾驶
9、 DistributionFocalLoss
class DistributionFocalLoss(nn.Module):
r"""Distribution Focal Loss (DFL) is a variant of `Generalized Focal Loss:
Learning Qualified and Distributed Bounding Boxes for Dense Object
Detection <https://arxiv.org/abs/2006.04388>`_.
Args:
reduction (str): Options are `'none'`, `'mean'` and `'sum'`.
loss_weight (float): Loss weight of current loss.
"""
def __init__(self, reduction='mean', loss_weight=1.0):
super(DistributionFocalLoss, self).__init__()
self.reduction = reduction
self.loss_weight = loss_weight
def forward(self,
pred,
target,
weight=None,
avg_factor=None,
reduction_override=None):
"""Forward function.
Args:
pred (torch.Tensor): Predicted general distribution of bounding
boxes (before softmax) with shape (N, n+1), n is the max value
of the integral set `{0, ..., n}` in paper.
target (torch.Tensor): Target distance label for bounding boxes
with shape (N,).
weight (torch.Tensor, optional): The weight of loss for each
prediction. Defaults to None.
avg_factor (int, optional): Average factor that is used to average
the loss. Defaults to None.
reduction_override (str, optional): The reduction method used to
override the original reduction method of the loss.
Defaults to None.
"""
assert reduction_override in (None, 'none', 'mean', 'sum')
reduction = (
reduction_override if reduction_override else self.reduction)
loss_cls = self.loss_weight * distribution_focal_loss(
pred, target, weight, reduction=reduction, avg_factor=avg_factor)
return loss_cls
应用场景
目标检测:
密集目标检测:DFL 适用于密集目标检测任务,比如在自然场景中检测多
边界框回归:在目
实例分割:
实例分割:DFL 也可以用于实例分割任务,特别是在需要精确定位物体边界的情况下。它通过改进边界框回归来提高实例分割的精度。
多尺度检测:
多尺度检测:在处理多尺度目标时,DFL 能够帮助提高不同尺度下的检测精度,尤其是在处理大范围或小范围目标时。
视觉导航:
视觉导航:DFL 可以用于视觉导航任务中,如自动驾驶汽车中的障碍物检测,帮助提高对边界框的预测精度,从而提升整体导航性能。
总结
Distribution Focal Loss(DFL)通过对边界框分布的建模和焦点损失的改进,提高了目标检测中的边界框回归精度。它适用于各种目标检测任务,包括密集目标检测、实例分割和多尺度检测等。DFL 的引入使得模型在这些任务中能够更准确地预测边界框,从而提升整体性能。
10、GHMC(分类任务,正负样本平衡机制)
Gradient Harmonized Classification Loss (GHMC) 是一种用于分类任务的损失函数,旨在解决传统分类损失函数在面对不平衡样本和梯度问题时的不足。GHMC 基于对梯度的调和处理,通过自适应调整样本权重,来提高分类模型在不平衡数据集上的性能。
算法原理
背景
在分类任务中,特别是在处理不平衡数据集时,传统的分类损失函数(如交叉熵损失)可能无法有效地处理梯度问题。传统方法容易受到易分类样本和难分类样本的梯度影响,可能导致训练过程中的不稳定性。
GHMC的核心思想
梯度调和:GHMC 通过分析梯度的分布,并根据梯度的强度动态调整样本的权重。具体来说,GHMC 计算每个样本的梯度长度,并将其划分为不同的区间(bins),然后根据这些区间的样本数量调整权重。
梯度长度:计算每个样本的梯度长度,即预测值与目标值之间的绝对差。
动态权重调整:对于每个梯度区间,根据样本数量调整权重。样本的权重被调整为总样本数除以当前区间的样本数,以减少梯度对易分类样本的影响,从而更关注难分类样本。
动量:GHMC 使用动量来平滑权重的调整过程,以避免权重变化过快。
GHMC的实现步骤
计算梯度长度:通过 g = torch.abs(pred.sigmoid().detach() - target) 计算预测值与目标值之间的绝对差。
权重计算:
将梯度长度划分为 bins 个区间。
对于每个区间,计算样本数量,并根据动量更新权重。
使用权重调整每个样本的损失。
计算损失:
使用二元交叉熵损失函数计算每个样本的损失。
根据计算出的权重调整损失,并应用所需的 reduction 操作。
class GHMC(nn.Module):
"""GHM Classification Loss.
Details of the theorem can be viewed in the paper
`Gradient Harmonized Single-stage Detector
<https://arxiv.org/abs/1811.05181>`_.
Args:
bins (int): Number of the unit regions for distribution calculation.
momentum (float): The parameter for moving average.
use_sigmoid (bool): Can only be true for BCE based loss now.
loss_weight (float): The weight of the total GHM-C loss.
reduction (str): Options are "none", "mean" and "sum".
Defaults to "mean"
"""
def __init__(self,
bins=10,
momentum=0,
use_sigmoid=True,
loss_weight=1.0,
reduction='mean'):
super(GHMC, self).__init__()
self.bins = bins
self.momentum = momentum
edges = torch.arange(bins + 1).float() / bins
self.register_buffer('edges', edges)
self.edges[-1] += 1e-6
if momentum > 0:
acc_sum = torch.zeros(bins)
self.register_buffer('acc_sum', acc_sum)
self.use_sigmoid = use_sigmoid
if not self.use_sigmoid:
raise NotImplementedError
self.loss_weight = loss_weight
self.reduction = reduction
def forward(self,
pred,
target,
label_weight,
reduction_override=None,
**kwargs):
"""Calculate the GHM-C loss.
Args:
pred (float tensor of size [batch_num, class_num]):
The direct prediction of classification fc layer.
target (float tensor of size [batch_num, class_num]):
Binary class target for each sample.
label_weight (float tensor of size [batch_num, class_num]):
the value is 1 if the sample is valid and 0 if ignored.
reduction_override (str, optional): The reduction method used to
override the original reduction method of the loss.
Defaults to None.
Returns:
The gradient harmonized loss.
"""
assert reduction_override in (None, 'none', 'mean', 'sum')
reduction = (
reduction_override if reduction_override else self.reduction)
# the target should be binary class label
if pred.dim() != target.dim():
target, label_weight = _expand_onehot_labels(
target, label_weight, pred.size(-1))
target, label_weight = target.float(), label_weight.float()
edges = self.edges
mmt = self.momentum
weights = torch.zeros_like(pred)
# gradient length
g = torch.abs(pred.sigmoid().detach() - target)
valid = label_weight > 0
tot = max(valid.float().sum().item(), 1.0)
n = 0 # n valid bins
for i in range(self.bins):
inds = (g >= edges[i]) & (g < edges[i + 1]) & valid
num_in_bin = inds.sum().item()
if num_in_bin > 0:
if mmt > 0:
self.acc_sum[i] = mmt * self.acc_sum[i] \
+ (1 - mmt) * num_in_bin
weights[inds] = tot / self.acc_sum[i]
else:
weights[inds] = tot / num_in_bin
n += 1
if n > 0:
weights = weights / n
loss = F.binary_cross_entropy_with_logits(
pred, target, reduction='none')
loss = weight_reduce_loss(
loss, weights, reduction=reduction, avg_factor=tot)
return loss * self.loss_weight
应用场景
不平衡数据集的分类任务
目标检测:在目标检测中,尤其是在面对大量背景区域和少量目标区域时,GHMC 可以帮助提高对少数目标区域的检测能力。
医学图像分类:在医学图像分类中,通常存在样本不平衡的问题。GHMC 可以帮助模型更好地处理少数类样本。
多类分类问题
多类分类:对于多类分类问题,GHMC 可以通过处理每个类别的样本梯度来改进模型对少数类的学习能力,从而提高分类准确性。
高噪声数据
处理高噪声数据:GHMC 对梯度的动态调整有助于减少噪声对模型训练的影响,使模型在面对高噪声数据时更具鲁棒性。
总结
Gradient Harmonized Classification Loss (GHMC) 通过对梯度进行调和处理,有效地解决了传统分类损失函数在处理不平衡数据和梯度问题时的不足。它适用于各种分类任务,包括不平衡数据集的目标检测、多类分类问题以及高噪声数据处理。通过动态调整样本权重,GHMC 能够帮助模型更好地处理难分类样本,提高整体分类性能。
11、GHMR(回归任务)
Gradient Harmonized Regression Loss (GHMR) 是一种用于回归任务的损失函数,它在梯度计算过程中考虑了样本的梯度分布,通过动态调整样本的权重来提高回归模型的性能。GHMR 是 GHMC(Gradient Harmonized Classification Loss)的回归版,旨在解决传统回归损失函数在处理不同梯度大小的样本时的不足。
算法原理
背景
在回归任务中,特别是处理边界框回归等问题时,样本的梯度可能会出现较大差异。传统的回归损失函数(如 L1 损失)可能无法有效处理这些差异,导致模型训练不稳定。
GHMR 的核心思想
Authentic Smooth L1 Loss: GHMR 使用平滑的 L1 损失来计算回归误差,平滑 L1 损失结合了 L1 和 L2 损失的优点,对小误差使用 L2 损失,对大误差使用 L1 损失。
梯度长度计算: GHMR 计算每个样本的梯度长度,并根据梯度长度动态调整样本的权重。具体来说,样本的梯度长度是通过标准化误差来计算的。
动态权重调整: GHMR 将样本的梯度长度划分为若干个区间(bins),根据每个区间的样本数量调整样本的权重。这种方法可以减少对梯度较大的样本的影响,从而关注梯度较小的样本。
GHMR 的实现步骤
计算损失: 使用平滑 L1 损失计算预测值与目标值之间的误差:
python
复制代码
loss = torch.sqrt(diff * diff + mu * mu) - mu
其中 diff 是预测值与目标值之间的差异,mu 是平滑参数。
计算梯度长度: 计算每个样本的梯度长度,并根据这个长度来调整权重:
python
复制代码
g = torch.abs(diff / torch.sqrt(mu * mu + diff * diff)).detach()
动态调整权重:
将梯度长度划分为若干个区间(bins)。
计算每个区间内的样本数量,并根据动量更新样本权重。
对每个样本应用相应的权重调整损失:
python
复制代码
weights[inds] = tot / num_in_bin
处理和计算
权重计算:使用权重调整损失值,并应用所需的 reduction 操作(如 ‘mean’、‘sum’)。
返回最终损失:将计算得到的损失乘以 loss_weight 返回。
class GHMR(nn.Module):
"""GHM Regression Loss.
Details of the theorem can be viewed in the paper
`Gradient Harmonized Single-stage Detector
<https://arxiv.org/abs/1811.05181>`_.
Args:
mu (float): The parameter for the Authentic Smooth L1 loss.
bins (int): Number of the unit regions for distribution calculation.
momentum (float): The parameter for moving average.
loss_weight (float): The weight of the total GHM-R loss.
reduction (str): Options are "none", "mean" and "sum".
Defaults to "mean"
"""
def __init__(self,
mu=0.02,
bins=10,
momentum=0,
loss_weight=1.0,
reduction='mean'):
super(GHMR, self).__init__()
self.mu = mu
self.bins = bins
edges = torch.arange(bins + 1).float() / bins
self.register_buffer('edges', edges)
self.edges[-1] = 1e3
self.momentum = momentum
if momentum > 0:
acc_sum = torch.zeros(bins)
self.register_buffer('acc_sum', acc_sum)
self.loss_weight = loss_weight
self.reduction = reduction
# TODO: support reduction parameter
def forward(self,
pred,
target,
label_weight,
avg_factor=None,
reduction_override=None):
"""Calculate the GHM-R loss.
Args:
pred (float tensor of size [batch_num, 4 (* class_num)]):
The prediction of box regression layer. Channel number can be 4
or 4 * class_num depending on whether it is class-agnostic.
target (float tensor of size [batch_num, 4 (* class_num)]):
The target regression values with the same size of pred.
label_weight (float tensor of size [batch_num, 4 (* class_num)]):
The weight of each sample, 0 if ignored.
reduction_override (str, optional): The reduction method used to
override the original reduction method of the loss.
Defaults to None.
Returns:
The gradient harmonized loss.
"""
assert reduction_override in (None, 'none', 'mean', 'sum')
reduction = (
reduction_override if reduction_override else self.reduction)
mu = self.mu
edges = self.edges
mmt = self.momentum
# ASL1 loss
diff = pred - target
loss = torch.sqrt(diff * diff + mu * mu) - mu
# gradient length
g = torch.abs(diff / torch.sqrt(mu * mu + diff * diff)).detach()
weights = torch.zeros_like(g)
valid = label_weight > 0
tot = max(label_weight.float().sum().item(), 1.0)
n = 0 # n: valid bins
for i in range(self.bins):
inds = (g >= edges[i]) & (g < edges[i + 1]) & valid
num_in_bin = inds.sum().item()
if num_in_bin > 0:
n += 1
if mmt > 0:
self.acc_sum[i] = mmt * self.acc_sum[i] \
+ (1 - mmt) * num_in_bin
weights[inds] = tot / self.acc_sum[i]
else:
weights[inds] = tot / num_in_bin
if n > 0:
weights /= n
loss = weight_reduce_loss(
loss, weights, reduction=reduction, avg_factor=tot)
return loss * self.loss_weight
应用场景
边界框回归
目标检测:在目标检测中,GHMR 可以用于处理边界框的回归问题,特别是在面对多种尺度的目标或具有高噪声的回归任务时,GHMR 能够提供更稳定的训练结果。
高精度回归任务
定位任务:对于需要高精度定位的任务,如关键点检测,GHMR 可以帮助模型更好地处理细小的误差,并提高定位精度。
不平衡回归任务
处理不平衡数据:在回归任务中,当数据分布不均衡时,GHMR 通过动态调整样本的权重,可以帮助模型更好地学习不平衡样本,从而提高整体回归性能。
总结
Gradient Harmonized Regression Loss (GHMR) 通过对回归任务中的梯度进行调和处理,提供了一种有效的解决方案来处理梯度差异和样本不平衡问题。它适用于各种回归任务,包括边界框回归、定位任务和不平衡数据处理。GHMR 通过平滑 L1 损失和动态权重调整,提高了模型的稳定性和性能。
12、IoULoss(目标检测任务的损失函数)
1、算法原理
IoU Loss 是一种用于目标检测任务的损失函数,它通过计算预测边界框和目标边界框之间的 Intersection over Union (IoU) 来评估模型的性能。与传统的损失函数不同,IoU Loss 直接在边界框的重叠程度上进行优化,旨在提高检测精度。算法原理
(1)背景
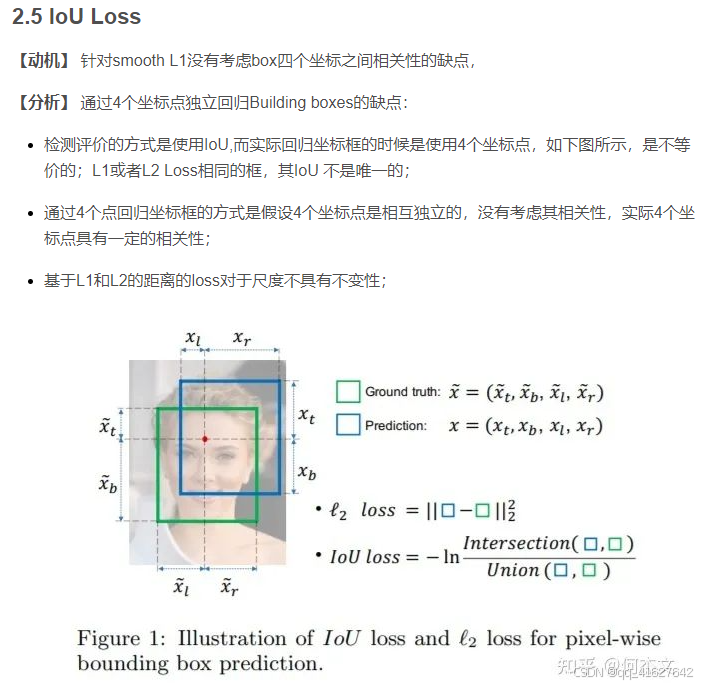
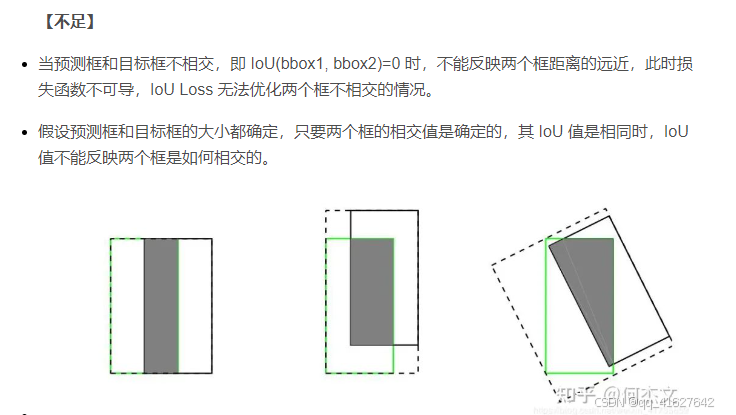
Intersection over Union (IoU) 是衡量两个边界框重叠程度的指标。IoU 计算的是两个边界框的交集区域与它们的并集区域的比值。IoU Loss 通过最小化预测边界框和真实边界框之间的 IoU 差异,来提高目标检测模型的精度。
(2)IoU Loss 的核心思想
IoU Loss 可以在不同的损失缩放模式下计算,这些模式包括线性(linear)、平方(square)和对数(log)模式。选择不同的模式可以影响损失的计算方式,从而适应不同的任务需求。
(3)IoU Loss 的实现步骤
1、计算 IoU: 根据预测值和目标值计算 IoU 值。
2、计算损失: 根据选择的模式计算损失值。
- 线性模式(linear): 直接使用 IoU 值作为损失,计算 IoU 的线性缩放。
- 平方模式(square): 使用 IoU 值的平方作为损失,计算 IoU 的平方缩放。
- 对数模式(log): 使用 IoU 值的对数作为损失,计算 IoU 的对数缩放。
3、加权损失: 对损失值应用权重和减少策略,以适应不同的训练需求。
2、 代码实现
class IoULoss(nn.Module):
"""IoULoss.
Computing the IoU loss between a set of predicted bboxes and target bboxes.
Args:
linear (bool): If True, use linear scale of loss else determined
by mode. Default: False.
eps (float): Eps to avoid log(0).
reduction (str): Options are "none", "mean" and "sum".
loss_weight (float): Weight of loss.
mode (str): Loss scaling mode, including "linear", "square", and "log".
Default: 'log'
"""
def __init__(self,
linear=False,
eps=1e-6,
reduction='mean',
loss_weight=1.0,
mode='log'):
super(IoULoss, self).__init__()
assert mode in ['linear', 'square', 'log']
if linear:
mode = 'linear'
warnings.warn('DeprecationWarning: Setting "linear=True" in '
'IOULoss is deprecated, please use "mode=`linear`" '
'instead.')
self.mode = mode
self.linear = linear
self.eps = eps
self.reduction = reduction
self.loss_weight = loss_weight
def forward(self,
pred,
target,
weight=None,
avg_factor=None,
reduction_override=None,
**kwargs):
"""Forward function.
Args:
pred (torch.Tensor): The prediction.
target (torch.Tensor): The learning target of the prediction.
weight (torch.Tensor, optional): The weight of loss for each
prediction. Defaults to None.
avg_factor (int, optional): Average factor that is used to average
the loss. Defaults to None.
reduction_override (str, optional): The reduction method used to
override the original reduction method of the loss.
Defaults to None. Options are "none", "mean" and "sum".
"""
assert reduction_override in (None, 'none', 'mean', 'sum')
reduction = (
reduction_override if reduction_override else self.reduction)
if (weight is not None) and (not torch.any(weight > 0)) and (
reduction != 'none'):
if pred.dim() == weight.dim() + 1:
weight = weight.unsqueeze(1)
return (pred * weight).sum() # 0
if weight is not None and weight.dim() > 1:
# TODO: remove this in the future
# reduce the weight of shape (n, 4) to (n,) to match the
# iou_loss of shape (n,)
assert weight.shape == pred.shape
weight = weight.mean(-1)
loss = self.loss_weight * iou_loss(
pred,
target,
weight,
mode=self.mode,
eps=self.eps,
reduction=reduction,
avg_factor=avg_factor,
**kwargs)
return loss
参数说明
linear: 如果设置为 True,则使用线性缩放模式。该参数的设置已经被弃用,建议使用 mode=‘linear’ 代替。
eps: 避免在计算对数时出现对数零错误。
reduction: 损失的计算方式,选项包括 ‘none’、‘mean’ 和 ‘sum’。
loss_weight: 损失的权重系数。
mode: 损失缩放模式,选项包括 ‘linear’、‘square’ 和 ‘log’。决定了如何计算 IoU 损失。
3、应用场景
目标检测
- 边界框回归:IoU Loss 主要用于目标检测任务中的边界框回归,优化模型预测的边界框与真实边界框之间的重叠程度。
精细定位
- 高精度检测:在需要高精度定位的任务中,如物体检测或关键点检测,IoU Loss 可以帮助模型提高对边界框的准确性。
模型训练
- 改进损失函数:在模型训练过程中,IoU Loss 通过优化边界框的重叠度,提高模型对目标的检测性能。
总结
IoU Loss 是一种用于目标检测的损失函数,通过直接优化边界框之间的重叠程度来提高模型的精度。它支持多种损失缩放模式,可以适应不同的任务需求。IoU Loss 通过计算预测和目标之间的 IoU 来评估模型的性能,适用于边界框回归和精细定位任务。
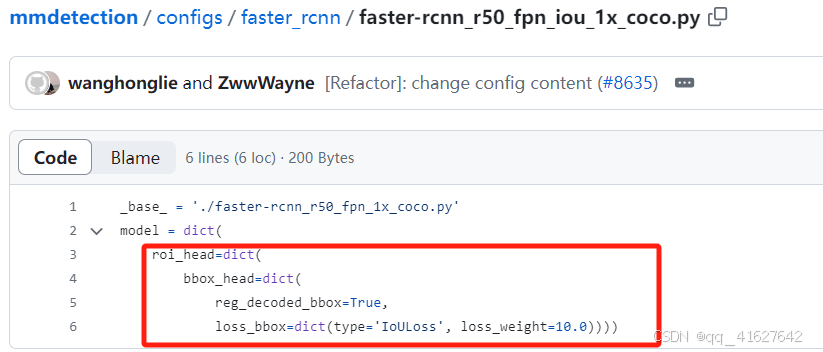
4、配置文件设置
13、BIoULoss(回归任务)
1、算法原理
BoundedIoULoss 的原理是基于目标检测中边界框的精确度。它通过以下方式来计算损失:
- 边界框的中心和尺寸计算: 计算预测和目标边界框的中心和尺寸。
- 计算损失分量:
loss_dx, loss_dy: 计算中心点位置的损失。
loss_dw, loss_dh: 计算宽度和高度的损失。 - 计算最终损失:
使用 Bounded IoU Loss 公式来计算损失,其中 loss_comb 是所有损失分量的组合。
应用平滑的 L1 损失函数来避免对损失进行过度惩罚。
2、代码实现
@mmcv.jit(derivate=True, coderize=True)
@weighted_loss
def bounded_iou_loss(pred, target, beta=0.2, eps=1e-3):
"""BIoULoss.
This is an implementation of paper
`Improving Object Localization with Fitness NMS and Bounded IoU Loss.
<https://arxiv.org/abs/1711.00164>`_.
Args:
pred (torch.Tensor): Predicted bboxes.
target (torch.Tensor): Target bboxes.
beta (float): beta parameter in smoothl1.
eps (float): eps to avoid NaN.
"""
pred_ctrx = (pred[:, 0] + pred[:, 2]) * 0.5
pred_ctry = (pred[:, 1] + pred[:, 3]) * 0.5
pred_w = pred[:, 2] - pred[:, 0]
pred_h = pred[:, 3] - pred[:, 1]
with torch.no_grad():
target_ctrx = (target[:, 0] + target[:, 2]) * 0.5
target_ctry = (target[:, 1] + target[:, 3]) * 0.5
target_w = target[:, 2] - target[:, 0]
target_h = target[:, 3] - target[:, 1]
dx = target_ctrx - pred_ctrx
dy = target_ctry - pred_ctry
loss_dx = 1 - torch.max(
(target_w - 2 * dx.abs()) /
(target_w + 2 * dx.abs() + eps), torch.zeros_like(dx))
loss_dy = 1 - torch.max(
(target_h - 2 * dy.abs()) /
(target_h + 2 * dy.abs() + eps), torch.zeros_like(dy))
loss_dw = 1 - torch.min(target_w / (pred_w + eps), pred_w /
(target_w + eps))
loss_dh = 1 - torch.min(target_h / (pred_h + eps), pred_h /
(target_h + eps))
# view(..., -1) does not work for empty tensor
loss_comb = torch.stack([loss_dx, loss_dy, loss_dw, loss_dh],
dim=-1).flatten(1)
loss = torch.where(loss_comb < beta, 0.5 * loss_comb * loss_comb / beta,
loss_comb - 0.5 * beta)
return loss
@LOSSES.register_module()
class BoundedIoULoss(nn.Module):
def __init__(self, beta=0.2, eps=1e-3, reduction='mean', loss_weight=1.0):
super(BoundedIoULoss, self).__init__()
self.beta = beta
self.eps = eps
self.reduction = reduction
self.loss_weight = loss_weight
def forward(self,
pred,
target,
weight=None,
avg_factor=None,
reduction_override=None,
**kwargs):
if weight is not None and not torch.any(weight > 0):
if pred.dim() == weight.dim() + 1:
weight = weight.unsqueeze(1)
return (pred * weight).sum() # 0
assert reduction_override in (None, 'none', 'mean', 'sum')
reduction = (
reduction_override if reduction_override else self.reduction)
loss = self.loss_weight * bounded_iou_loss(
pred,
target,
weight,
beta=self.beta,
eps=self.eps,
reduction=reduction,
avg_factor=avg_factor,
**kwargs)
return loss
3、应用场景
BoundedIoULoss 通常用于目标检测任务中的损失计算,尤其是在需要提高定位精度时。它可以用来优化目标检测模型,使得预测的边界框更接近目标边界框,从而提高检测精度。具体应用场景包括:
目标检测: 用于训练检测算法(如 YOLO、Faster R-CNN 等),以提高对目标位置的准确性。
计算机视觉: 在需要精确边界框定位的任务中,如物体检测、实例分割等。
4、配置文件设置
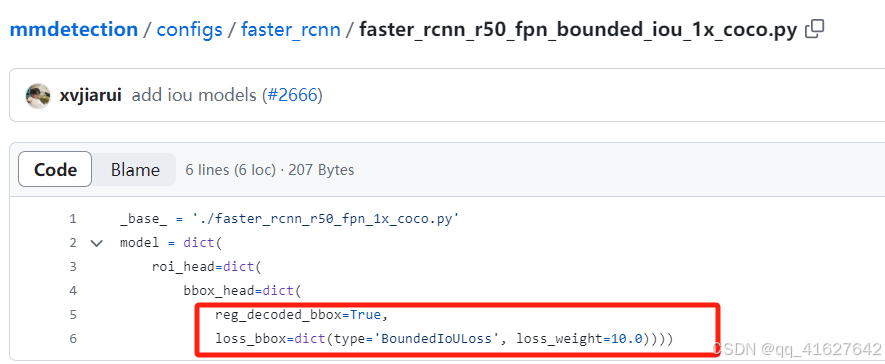
14、GIoULoss(回归任务)
1、算法原理
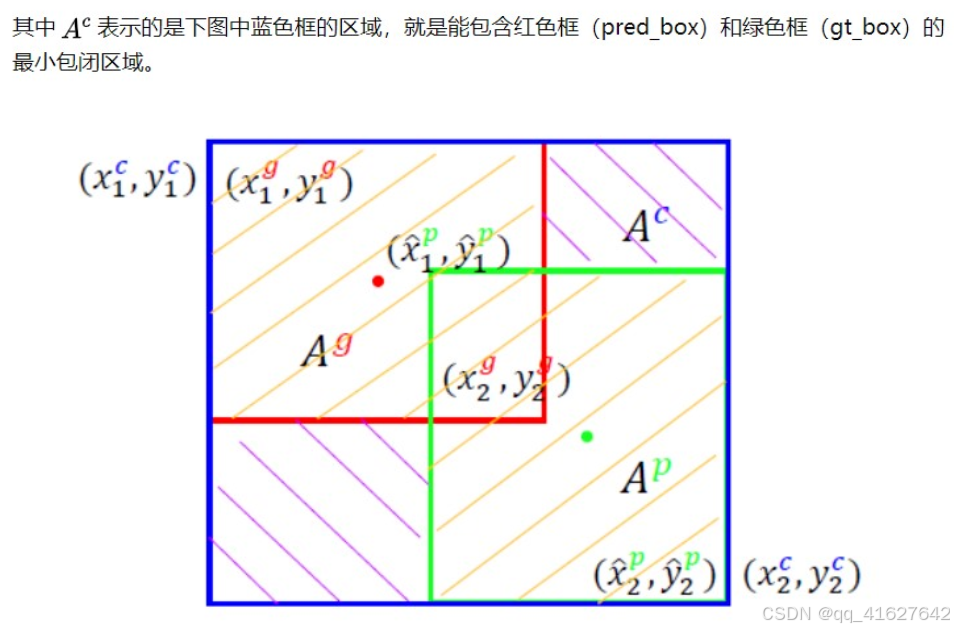
为了解决IoU存在的问题,Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression中提出了GIoU loss,他考虑了能包含两个边界框的最小包闭区间,这样就可以对没有重叠部分的框进行有效衡量,距离较远的,loss大,距离较近的,loss小。计算公式如下:
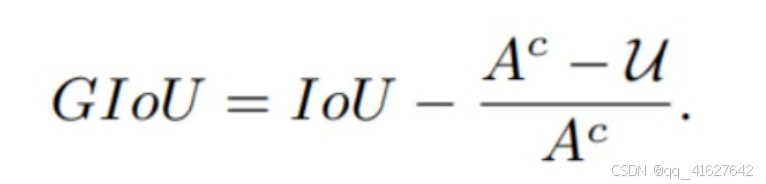

IoU 损失的公式为:
GIoU Loss=1−GIoU
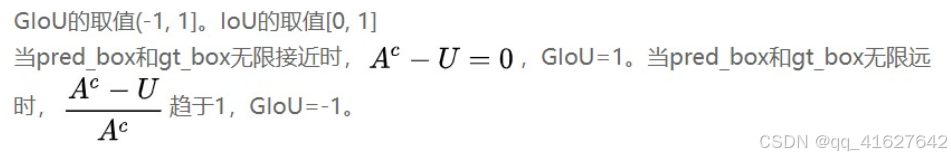

2、代码实现
@mmcv.jit(derivate=True, coderize=True)
@weighted_loss
def giou_loss(pred, target, eps=1e-7):
r"""`Generalized Intersection over Union: A Metric and A Loss for Bounding
Box Regression <https://arxiv.org/abs/1902.09630>`_.
Args:
pred (torch.Tensor): Predicted bboxes of format (x1, y1, x2, y2),
shape (n, 4).
target (torch.Tensor): Corresponding gt bboxes, shape (n, 4).
eps (float): Eps to avoid log(0).
Return:
Tensor: Loss tensor.
"""
gious = bbox_overlaps(pred, target, mode='giou', is_aligned=True, eps=eps)
loss = 1 - gious
return loss
class GIoULoss(nn.Module):
def __init__(self, eps=1e-6, reduction='mean', loss_weight=1.0):
super(GIoULoss, self).__init__()
self.eps = eps
self.reduction = reduction
self.loss_weight = loss_weight
def forward(self,
pred,
target,
weight=None,
avg_factor=None,
reduction_override=None,
**kwargs):
if weight is not None and not torch.any(weight > 0):
if pred.dim() == weight.dim() + 1:
weight = weight.unsqueeze(1)
return (pred * weight).sum() # 0
assert reduction_override in (None, 'none', 'mean', 'sum')
reduction = (
reduction_override if reduction_override else self.reduction)
if weight is not None and weight.dim() > 1:
# TODO: remove this in the future
# reduce the weight of shape (n, 4) to (n,) to match the
# giou_loss of shape (n,)
assert weight.shape == pred.shape
weight = weight.mean(-1)
loss = self.loss_weight * giou_loss(
pred,
target,
weight,
eps=self.eps,
reduction=reduction,
avg_factor=avg_factor,
**kwargs)
return loss
计算步骤
计算交集框的坐标和面积:求出预测框和目标框的交集部分的坐标,并计算其面积。
计算预测框和目标框的面积:分别计算预测框和目标框的面积。
计算并集面积:通过预测框和目标框的面积减去交集面积得到并集面积。
计算 IoU:通过交集面积除以并集面积得到 IoU。
计算最小外接矩形的坐标和面积:求出包含预测框和目标框的最小外接矩形的坐标,并计算其面积。
计算 GIoU:通过 IoU 减去最小外接矩形面积和并集面积的差比上最小外接矩形的面积,得到 GIoU。
计算 GIoU 损失:通过 1 减去 GIoU 得到 GIoU 损失。
3、应用场景
应用场景
目标检测:GIoU 损失常用于目标检测任务中,用于回归预测框的坐标。由于 GIoU 能够更好地处理边界框之间的关系,因此在目标检测任务中表现优于传统的 IoU 损失。
图像分割:在图像分割任务中,也可以使用 GIoU 损失来度量预测分割掩码和真实掩码之间的重叠程度,从而优化模型。
三维目标检测:在三维目标检测任务中,GIoU 损失同样可以用于优化三维边界框的位置和尺寸。
视频目标跟踪:在视频目标跟踪任务中,GIoU 损失可以帮助跟踪器更准确地预测目标的位置,提高跟踪性能。
4、配置文件设置
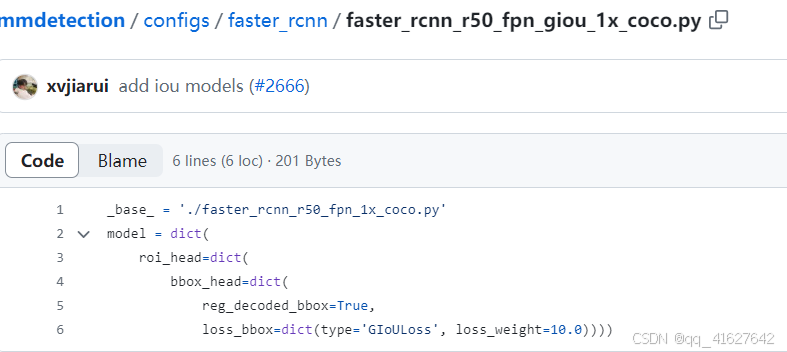
15、DIoULoss(回归任务)
1、算法原理
DIoU Loss是由Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression这篇论文提出,论文中针对IoU loss和GIoU loss的不足,说到坐标回归需要同时考虑重叠区域(overlap area)、中心点距离(central point distance)以及长宽比(aspect ratio)这三个要素,并且引出了两个问题:
1.能否直接优化pred_box和gt_box之间的距离来使模型快速收敛。2.当pred_box和gt_box有重叠时,能否更加准确的做回归。
DIoU loss解决了提出的第一个问题,把pred_box和gt_box之间的中心点距离作为损失的一部分,计算公式如下:
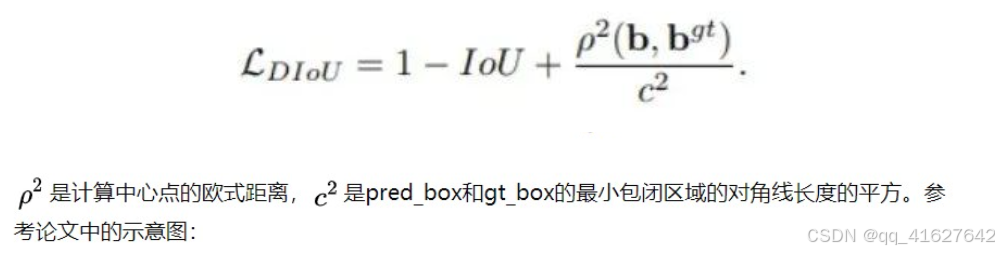

2、代码实现
@mmcv.jit(derivate=True, coderize=True)
@weighted_loss
def diou_loss(pred, target, eps=1e-7):
r"""`Implementation of Distance-IoU Loss: Faster and Better
Learning for Bounding Box Regression, https://arxiv.org/abs/1911.08287`_.
Code is modified from https://github.com/Zzh-tju/DIoU.
Args:
pred (Tensor): Predicted bboxes of format (x1, y1, x2, y2),
shape (n, 4).
target (Tensor): Corresponding gt bboxes, shape (n, 4).
eps (float): Eps to avoid log(0).
Return:
Tensor: Loss tensor.
"""
# overlap
lt = torch.max(pred[:, :2], target[:, :2])
rb = torch.min(pred[:, 2:], target[:, 2:])
wh = (rb - lt).clamp(min=0)
overlap = wh[:, 0] * wh[:, 1]
# union
ap = (pred[:, 2] - pred[:, 0]) * (pred[:, 3] - pred[:, 1])
ag = (target[:, 2] - target[:, 0]) * (target[:, 3] - target[:, 1])
union = ap + ag - overlap + eps
# IoU
ious = overlap / union
# enclose area
enclose_x1y1 = torch.min(pred[:, :2], target[:, :2])
enclose_x2y2 = torch.max(pred[:, 2:], target[:, 2:])
enclose_wh = (enclose_x2y2 - enclose_x1y1).clamp(min=0)
cw = enclose_wh[:, 0]
ch = enclose_wh[:, 1]
c2 = cw**2 + ch**2 + eps
b1_x1, b1_y1 = pred[:, 0], pred[:, 1]
b1_x2, b1_y2 = pred[:, 2], pred[:, 3]
b2_x1, b2_y1 = target[:, 0], target[:, 1]
b2_x2, b2_y2 = target[:, 2], target[:, 3]
left = ((b2_x1 + b2_x2) - (b1_x1 + b1_x2))**2 / 4
right = ((b2_y1 + b2_y2) - (b1_y1 + b1_y2))**2 / 4
rho2 = left + right
# DIoU
dious = ious - rho2 / c2
loss = 1 - dious
return loss
@MODELS.register_module()
class DIoULoss(nn.Module):
r"""Implementation of `Distance-IoU Loss: Faster and Better
Learning for Bounding Box Regression https://arxiv.org/abs/1911.08287`_.
Code is modified from https://github.com/Zzh-tju/DIoU.
Args:
eps (float): Epsilon to avoid log(0).
reduction (str): Options are "none", "mean" and "sum".
loss_weight (float): Weight of loss.
"""
def __init__(self,
eps: float = 1e-6,
reduction: str = 'mean',
loss_weight: float = 1.0) -> None:
super().__init__()
self.eps = eps
self.reduction = reduction
self.loss_weight = loss_weight
def forward(self,
pred: Tensor,
target: Tensor,
weight: Optional[Tensor] = None,
avg_factor: Optional[int] = None,
reduction_override: Optional[str] = None,
**kwargs) -> Tensor:
"""Forward function.
Args:
pred (Tensor): Predicted bboxes of format (x1, y1, x2, y2),
shape (n, 4).
target (Tensor): The learning target of the prediction,
shape (n, 4).
weight (Optional[Tensor], optional): The weight of loss for each
prediction. Defaults to None.
avg_factor (Optional[int], optional): Average factor that is used
to average the loss. Defaults to None.
reduction_override (Optional[str], optional): The reduction method
used to override the original reduction method of the loss.
Defaults to None. Options are "none", "mean" and "sum".
Returns:
Tensor: Loss tensor.
"""
if weight is not None and not torch.any(weight > 0):
if pred.dim() == weight.dim() + 1:
weight = weight.unsqueeze(1)
return (pred * weight).sum() # 0
assert reduction_override in (None, 'none', 'mean', 'sum')
reduction = (
reduction_override if reduction_override else self.reduction)
if weight is not None and weight.dim() > 1:
# TODO: remove this in the future
# reduce the weight of shape (n, 4) to (n,) to match the
# giou_loss of shape (n,)
assert weight.shape == pred.shape
weight = weight.mean(-1)
loss = self.loss_weight * diou_loss(
pred,
target,
weight,
eps=self.eps,
reduction=reduction,
avg_factor=avg_factor,
**kwargs)
return loss
16、CIoULoss (回归任务)
1、算法原理
CIoU Loss也是由Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression这篇论文提出的,是解决上面的第2个问题:当pred_box和gt_box有重叠时,能否更加准确的做回归。
CIoU Loss把长宽比(aspect ratio)这个要素考虑进来了,定义公式如下:
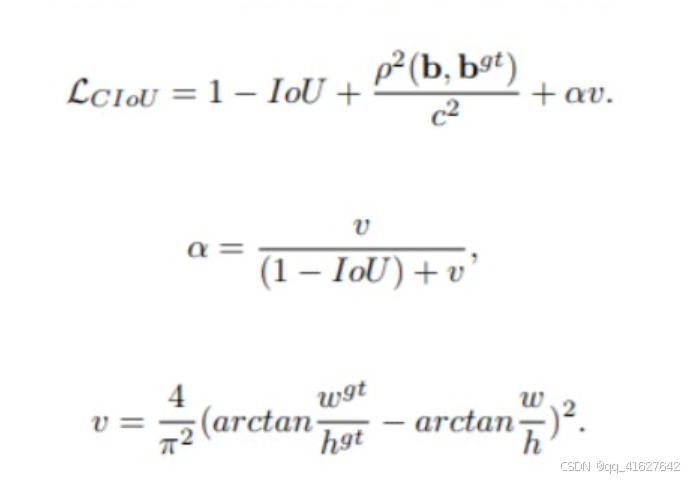

2、代码实现
@mmcv.jit(derivate=True, coderize=True)
@weighted_loss
def ciou_loss(pred, target, eps=1e-7):
r"""`Implementation of paper `Enhancing Geometric Factors into
Model Learning and Inference for Object Detection and Instance
Segmentation <https://arxiv.org/abs/2005.03572>`_.
Code is modified from https://github.com/Zzh-tju/CIoU.
Args:
pred (Tensor): Predicted bboxes of format (x1, y1, x2, y2),
shape (n, 4).
target (Tensor): Corresponding gt bboxes, shape (n, 4).
eps (float): Eps to avoid log(0).
Return:
Tensor: Loss tensor.
"""
# overlap
lt = torch.max(pred[:, :2], target[:, :2])
rb = torch.min(pred[:, 2:], target[:, 2:])
wh = (rb - lt).clamp(min=0)
overlap = wh[:, 0] * wh[:, 1]
# union
ap = (pred[:, 2] - pred[:, 0]) * (pred[:, 3] - pred[:, 1])
ag = (target[:, 2] - target[:, 0]) * (target[:, 3] - target[:, 1])
union = ap + ag - overlap + eps
# IoU
ious = overlap / union
# enclose area
enclose_x1y1 = torch.min(pred[:, :2], target[:, :2])
enclose_x2y2 = torch.max(pred[:, 2:], target[:, 2:])
enclose_wh = (enclose_x2y2 - enclose_x1y1).clamp(min=0)
cw = enclose_wh[:, 0]
ch = enclose_wh[:, 1]
c2 = cw**2 + ch**2 + eps
b1_x1, b1_y1 = pred[:, 0], pred[:, 1]
b1_x2, b1_y2 = pred[:, 2], pred[:, 3]
b2_x1, b2_y1 = target[:, 0], target[:, 1]
b2_x2, b2_y2 = target[:, 2], target[:, 3]
w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps
left = ((b2_x1 + b2_x2) - (b1_x1 + b1_x2))**2 / 4
right = ((b2_y1 + b2_y2) - (b1_y1 + b1_y2))**2 / 4
rho2 = left + right
factor = 4 / math.pi**2
v = factor * torch.pow(torch.atan(w2 / h2) - torch.atan(w1 / h1), 2)
with torch.no_grad():
alpha = (ious > 0.5).float() * v / (1 - ious + v)
# CIoU
cious = ious - (rho2 / c2 + alpha * v)
loss = 1 - cious.clamp(min=-1.0, max=1.0)
return loss
@MODELS.register_module()
class CIoULoss(nn.Module):
r"""`Implementation of paper `Enhancing Geometric Factors into
Model Learning and Inference for Object Detection and Instance
Segmentation <https://arxiv.org/abs/2005.03572>`_.
Code is modified from https://github.com/Zzh-tju/CIoU.
Args:
eps (float): Epsilon to avoid log(0).
reduction (str): Options are "none", "mean" and "sum".
loss_weight (float): Weight of loss.
"""
def __init__(self,
eps: float = 1e-6,
reduction: str = 'mean',
loss_weight: float = 1.0) -> None:
super().__init__()
self.eps = eps
self.reduction = reduction
self.loss_weight = loss_weight
def forward(self,
pred: Tensor,
target: Tensor,
weight: Optional[Tensor] = None,
avg_factor: Optional[int] = None,
reduction_override: Optional[str] = None,
**kwargs) -> Tensor:
"""Forward function.
Args:
pred (Tensor): Predicted bboxes of format (x1, y1, x2, y2),
shape (n, 4).
target (Tensor): The learning target of the prediction,
shape (n, 4).
weight (Optional[Tensor], optional): The weight of loss for each
prediction. Defaults to None.
avg_factor (Optional[int], optional): Average factor that is used
to average the loss. Defaults to None.
reduction_override (Optional[str], optional): The reduction method
used to override the original reduction method of the loss.
Defaults to None. Options are "none", "mean" and "sum".
Returns:
Tensor: Loss tensor.
"""
if weight is not None and not torch.any(weight > 0):
if pred.dim() == weight.dim() + 1:
weight = weight.unsqueeze(1)
return (pred * weight).sum() # 0
assert reduction_override in (None, 'none', 'mean', 'sum')
reduction = (
reduction_override if reduction_override else self.reduction)
if weight is not None and weight.dim() > 1:
# TODO: remove this in the future
# reduce the weight of shape (n, 4) to (n,) to match the
# giou_loss of shape (n,)
assert weight.shape == pred.shape
weight = weight.mean(-1)
loss = self.loss_weight * ciou_loss(
pred,
target,
weight,
eps=self.eps,
reduction=reduction,
avg_factor=avg_factor,
**kwargs)
return loss
3、配置文件设置
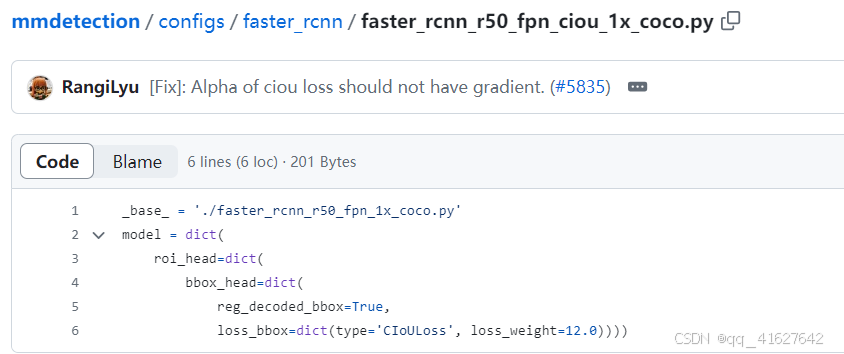
17、 EIoULoss(回归任务)
@MODELS.register_module()
class EIoULoss(nn.Module):
r"""Implementation of paper Extended-IoU Loss: A Systematic IoU-Related Method: Beyond Simplified Regression for Better Localization <https://ieeexplore.ieee.org/abstract/document/9429909>_
Code is modified from https://github.com//ShiqiYu/libfacedetection.train.
Args:
eps (float): Epsilon to avoid log(0).
reduction (str): Options are "none", "mean" and "sum".
loss_weight (float): Weight of loss.
smooth_point (float): hyperparameter, default is 0.1.
"""
def __init__(self,
eps: float = 1e-6,
reduction: str = 'mean',
loss_weight: float = 1.0,
smooth_point: float = 0.1) -> None:
super().__init__()
self.eps = eps
self.reduction = reduction
self.loss_weight = loss_weight
self.smooth_point = smooth_point
def forward(self,
pred: Tensor,
target: Tensor,
weight: Optional[Tensor] = None,
avg_factor: Optional[int] = None,
reduction_override: Optional[str] = None,
**kwargs) -> Tensor:
"""Forward function.
Args:
pred (Tensor): Predicted bboxes of format (x1, y1, x2, y2),
shape (n, 4).
target (Tensor): The learning target of the prediction,
shape (n, 4).
weight (Optional[Tensor], optional): The weight of loss for each
prediction. Defaults to None.
avg_factor (Optional[int], optional): Average factor that is used
to average the loss. Defaults to None.
reduction_override (Optional[str], optional): The reduction method
used to override the original reduction method of the loss.
Defaults to None. Options are "none", "mean" and "sum".
Returns:
Tensor: Loss tensor.
"""
if weight is not None and not torch.any(weight > 0):
if pred.dim() == weight.dim() + 1:
weight = weight.unsqueeze(1)
return (pred * weight).sum() # 0
assert reduction_override in (None, 'none', 'mean', 'sum')
reduction = (
reduction_override if reduction_override else self.reduction)
if weight is not None and weight.dim() > 1:
assert weight.shape == pred.shape
weight = weight.mean(-1)
loss = self.loss_weight * eiou_loss(
pred,
target,
weight,
smooth_point=self.smooth_point,
eps=self.eps,
reduction=reduction,
avg_factor=avg_factor,
**kwargs)
return loss
18、SIoULoss(回归任务)
@MODELS.register_module()
class SIoULoss(nn.Module):
r"""Implementation of paper SIoU Loss: More Powerful Learning
for Bounding Box Regression https://arxiv.org/abs/2205.12740`_.
Code is modified from https://github.com/meituan/YOLOv6.
Args:
pred (Tensor): Predicted bboxes of format (x1, y1, x2, y2),
shape (n, 4).
target (Tensor): Corresponding gt bboxes, shape (n, 4).
eps (float): Eps to avoid log(0).
neg_gamma (bool): `True` follows original implementation in paper.
Return:
Tensor: Loss tensor.
"""
def __init__(self,
eps: float = 1e-6,
reduction: str = 'mean',
loss_weight: float = 1.0,
neg_gamma: bool = False) -> None:
super().__init__()
self.eps = eps
self.reduction = reduction
self.loss_weight = loss_weight
self.neg_gamma = neg_gamma
def forward(self,
pred: Tensor,
target: Tensor,
weight: Optional[Tensor] = None,
avg_factor: Optional[int] = None,
reduction_override: Optional[str] = None,
**kwargs) -> Tensor:
"""Forward function.
Args:
pred (Tensor): Predicted bboxes of format (x1, y1, x2, y2),
shape (n, 4).
target (Tensor): The learning target of the prediction,
shape (n, 4).
weight (Optional[Tensor], optional): The weight of loss for each
prediction. Defaults to None.
avg_factor (Optional[int], optional): Average factor that is used
to average the loss. Defaults to None.
reduction_override (Optional[str], optional): The reduction method
used to override the original reduction method of the loss.
Defaults to None. Options are "none", "mean" and "sum".
Returns:
Tensor: Loss tensor.
"""
if weight is not None and not torch.any(weight > 0):
if pred.dim() == weight.dim() + 1:
weight = weight.unsqueeze(1)
return (pred * weight).sum() # 0
assert reduction_override in (None, 'none', 'mean', 'sum')
reduction = (
reduction_override if reduction_override else self.reduction)
if weight is not None and weight.dim() > 1:
# TODO: remove this in the future
# reduce the weight of shape (n, 4) to (n,) to match the
# giou_loss of shape (n,)
assert weight.shape == pred.shape
weight = weight.mean(-1)
loss = self.loss_weight * siou_loss(
pred,
target,
weight,
eps=self.eps,
reduction=reduction,
avg_factor=avg_factor,
neg_gamma=self.neg_gamma,
**kwargs)
return loss


KD_LOSS
@LOSSES.register_module()
class KnowledgeDistillationKLDivLoss(nn.Module):
"""Loss function for knowledge distilling using KL divergence.
Args:
reduction (str): Options are `'none'`, `'mean'` and `'sum'`.
loss_weight (float): Loss weight of current loss.
T (int): Temperature for distillation.
"""
def __init__(self, reduction='mean', loss_weight=1.0, T=10):
super(KnowledgeDistillationKLDivLoss, self).__init__()
assert T >= 1
self.reduction = reduction
self.loss_weight = loss_weight
self.T = T
def forward(self,
pred,
soft_label,
weight=None,
avg_factor=None,
reduction_override=None):
"""Forward function.
Args:
pred (Tensor): Predicted logits with shape (N, n + 1).
soft_label (Tensor): Target logits with shape (N, N + 1).
weight (torch.Tensor, optional): The weight of loss for each
prediction. Defaults to None.
avg_factor (int, optional): Average factor that is used to average
the loss. Defaults to None.
reduction_override (str, optional): The reduction method used to
override the original reduction method of the loss.
Defaults to None.
"""
assert reduction_override in (None, 'none', 'mean', 'sum')
reduction = (
reduction_override if reduction_override else self.reduction)
loss_kd = self.loss_weight * knowledge_distillation_kl_div_loss(
pred,
soft_label,
weight,
reduction=reduction,
avg_factor=avg_factor,
T=self.T)
return loss_kd
MSELoss
@LOSSES.register_module()
class MSELoss(nn.Module):
“”"MSELoss.
Args:
reduction (str, optional): The method that reduces the loss to a
scalar. Options are "none", "mean" and "sum".
loss_weight (float, optional): The weight of the loss. Defaults to 1.0
"""
def __init__(self, reduction='mean', loss_weight=1.0):
super().__init__()
self.reduction = reduction
self.loss_weight = loss_weight
def forward(self,
pred,
target,
weight=None,
avg_factor=None,
reduction_override=None):
"""Forward function of loss.
Args:
pred (torch.Tensor): The prediction.
target (torch.Tensor): The learning target of the prediction.
weight (torch.Tensor, optional): Weight of the loss for each
prediction. Defaults to None.
avg_factor (int, optional): Average factor that is used to average
the loss. Defaults to None.
reduction_override (str, optional): The reduction method used to
override the original reduction method of the loss.
Defaults to None.
Returns:
torch.Tensor: The calculated loss
"""
assert reduction_override in (None, 'none', 'mean', 'sum')
reduction = (
reduction_override if reduction_override else self.reduction)
loss = self.loss_weight * mse_loss(
pred, target, weight, reduction=reduction, avg_factor=avg_factor)
return loss
2、MMDetection自定义损失
MMDetection 为用户提供了不同的损失函数。但默认配置可能不适用于不同的数据集或模型,因此用户可能需要修改特定的损失以适应新的情况。
1、损失的计算流程
本教程首先详细说明损失的计算流程,然后给出有关如何修改每个步骤的说明。修改可分为调整和加权。
设置采样方法,采样正样本和负样本。
通过损失核函数获取逐元素或者逐样本的损失。
使用权重张量逐个元素地计算损失的权重。
将损失张量简化为标量。
用标量来加权损失。
2、设置采样方法,采样正样本和负样本。 (step 1)
对于某些损失函数,需要采取抽样策略来避免正样本和负样本之间的不平衡。
例如,当在RPN头部使用CrossEntropyLoss时,我们需要在train_cfg中设置RandomSampler
train_cfg=dict(
rpn=dict(
sampler=dict(
type='RandomSampler',
num=256,
pos_fraction=0.5,
neg_pos_ub=-1,
add_gt_as_proposals=False))
对于具有正负样品平衡机制的其他损失,如FocalLoss、GHMC和QualityFocalLoss,则不再需要采样器。
2、调整损失
调整损失与步骤2、步骤4、步骤5更相关,大多数修改都可以在配置中指定。这里我们以Focal Loss (FL)为例。下面的代码狙击手分别是FL的构造方法和配置,它们实际上是一一对应的。
@LOSSES.register_module()
class FocalLoss(nn.Module):
def __init__(self,
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
reduction='mean',
loss_weight=1.0):
loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0)
调整超参数(步骤 2) (step 2)
gamma和beta是焦损的两个超参数。假设我们想要将gamma值改为1.5,alpha值改为0.5,那么我们可以在配置中如下所示指定它们:
loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=1.5,
alpha=0.5,
loss_weight=1.0)
调整减少的方式 (step 3)
对于FL,约简的默认方式是mean。例如,如果我们想要将约简从mean更改为sum,我们可以在配置中指定如下:
loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0,
reduction='sum')
调整损失权重(步骤 5) (step 5)
这里的损失权值是一个标量,它控制多任务学习中不同损失的权值,例如分类损失和回归损失。例如,如果我们想将分类损失的损失权重改为0.5,我们可以在配置中如下所示:
loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=0.5)
3、加权损失 (step 3)
加权损失意味着我们明智地重新加权损失元素。更具体地说,我们将损失张量与一个具有相同形状的权张量相乘。因此,损失的不同分项可以按不同的比例计算,这就是所谓的“要素”。损失权值在不同的模型中是不同的,并且与上下文高度相关,但总体上有两种损失权值,用于分类损失的label_weights和用于框回归损失的bbox_weights。您可以在相应头部的get_target方法中找到它们。这里我们以atshead为例,它继承了AnchorHead但是覆盖了它的get_targets方法,从而产生了不同的label_weights和bbox_weights。
lass ATSSHead(AnchorHead):
...
def get_targets(self,
anchor_list,
valid_flag_list,
gt_bboxes_list,
img_metas,
gt_bboxes_ignore_list=None,
gt_labels_list=None,
label_channels=1,
unmap_outputs=True):

















 1985
1985

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









