








简单的数据预处理:
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler,StandardScaler
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
from sklearn.preprocessing import Normalizer
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.decomposition import PCA
import pydotplus
#sl:satisfaction_level---False:MinMaxScaler;True:StandardScaler
#le:last_evaluation---False:MinMaxScaler;True:StandardScaler
#npr:number_project---False:MinMaxScaler;True:StandardScaler
#amh:average_monthly_hours--False:MinMaxScaler;True:StandardScaler
#tsc:time_spend_company--False:MinMaxScaler;True:StandardScaler
#wa:Work_accident--False:MinMaxScaler;True:StandardScaler
#pl5:promotion_last_5years--False:MinMaxScaler;True:StandardScaler
#dp:department--False:LabelEncoding;True:OneHotEncoding
#slr:salary--False:LabelEncoding;True:OneHotEncoding
#定义函数读入数据
def hr_preprocessing(sl=False,le=False,npr=False,amh=False,tsc=False,wa=False,pl5=False,dp=False,slr=False,lower_d=False,ld_n=1):
df = pd.read_csv("./HR.csv")
# 1、清洗数据
df = df.dropna(subset=["satisfaction_level", "last_evaluation"])
df = df[df["satisfaction_level"] <= 1][df["salary"] != "nme"]
# 2、得到标注
label = df["left"]
df = df.drop("left", axis=1)
# 3、特征选择
# 4、特征处理
scaler_lst = [sl, le, npr, amh, tsc, wa, pl5]
column_lst = ["satisfaction_level", "last_evaluation", "number_project", \
"average_monthly_hours", "time_spend_company", "Work_accident", \
"promotion_last_5years"]
for i in range(len(scaler_lst)):
if not scaler_lst[i]:
df[column_lst[i]] = \
MinMaxScaler().fit_transform(df[column_lst[i]].values.reshape(-1, 1)).reshape(1, -1)[0]
else:
df[column_lst[i]] = \
StandardScaler().fit_transform(df[column_lst[i]].values.reshape(-1, 1)).reshape(1, -1)[0]
scaler_lst = [slr, dp]
column_lst = ["salary", "department"]
for i in range(len(scaler_lst)):
if not scaler_lst[i]:
if column_lst[i] == "salary":
df[column_lst[i]] = [map_salary(s) for s in df["salary"].values]
else:
df[column_lst[i]] = LabelEncoder().fit_transform(df[column_lst[i]])
df[column_lst[i]] = MinMaxScaler().fit_transform(df[column_lst[i]].values.reshape(-1, 1)).reshape(1, -1)[0]
else:
df = pd.get_dummies(df, columns=[column_lst[i]])
if lower_d:
return PCA(n_components=ld_n).fit_transform(df.values), label #PAC降维可以不使用标注
return df, label
d = dict([("low", 0), ("medium", 1), ("high", 2)])
def map_salary(s):
return d.get(s,0)
def main():
print(hr_preprocessing())
if __name__ == '__main__':
main()
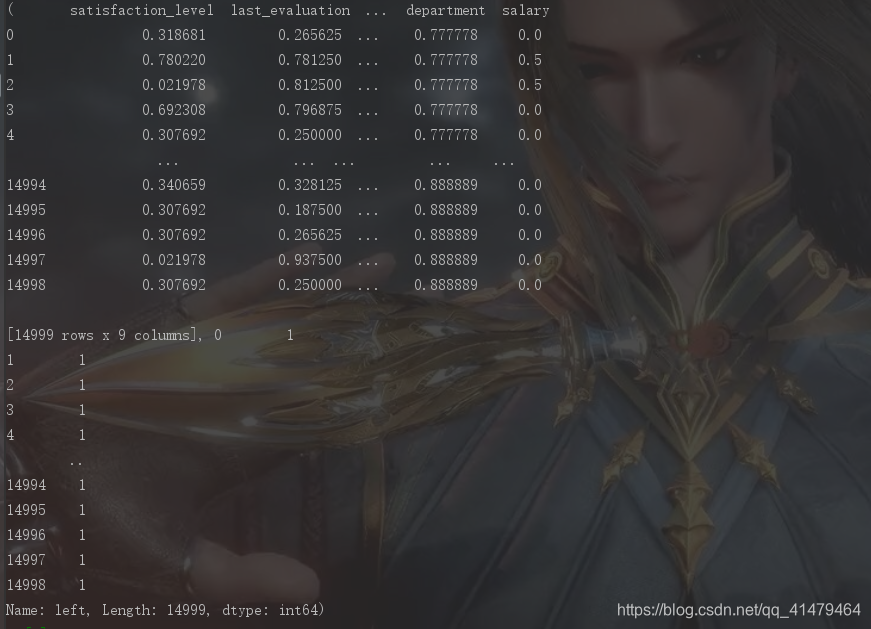
部分数据:
satisfaction_level,last_evaluation,number_project,average_monthly_hours,time_spend_company,Work_accident,left,promotion_last_5years,department,salary
0.38,0.53,2,157,3,0,1,0,sales,low
0.8,0.86,5,262,6,0,1,0,sales,medium
0.11,0.88,7,272,4,0,1,0,sales,medium
0.72,0.87,5,223,5,0,1,0,sales,low
0.37,0.52,2,159,3,0,1,0,sales,low
0.41,0.5,2,153,3,0,1,0,sales,low
0.1,0.77,6,247,4,0,1,0,sales,low
0.92,0.85,5,259,5,0,1,0,sales,low
0.89,1,5,224,5,0,1,0,sales,low
0.42,0.53,2,142,3,0,1,0,sales,low
0.45,0.54,2,135,3,0,1,0,sales,low
0.11,0.81,6,305,4,0,1,0,sales,low
0.84,0.92,4,234,5,0,1,0,sales,low
0.41,0.55,2,148,3,0,1,0,sales,low
0.36,0.56,2,137,3,0,1,0,sales,low
0.38,0.54,2,143,3,0,1,0,sales,low
0.45,0.47,2,160,3,0,1,0,sales,low
0.78,0.99,4,255,6,0,1,0,sales,low
0.45,0.51,2,160,3,1,1,1,sales,low
0.76,0.89,5,262,5,0,1,0,sales,low
0.11,0.83,6,282,4,0,1,0,sales,low
0.38,0.55,2,147,3,0,1,0,sales,low
0.09,0.95,6,304,4,0,1,0,sales,low
0.46,0.57,2,139,3,0,1,0,sales,low
0.4,0.53,2,158,3,0,1,0,sales,low
0.89,0.92,5,242,5,0,1,0,sales,low
0.82,0.87,4,239,5,0,1,0,sales,low
0.4,0.49,2,135,3,0,1,0,sales,low
0.41,0.46,2,128,3,0,1,0,accounting,low
0.38,0.5,2,132,3,0,1,0,accounting,low
0.09,0.62,6,294,4,0,1,0,accounting,low
0.45,0.57,2,134,3,0,1,0,hr,low
0.4,0.51,2,145,3,0,1,0,hr,low
0.45,0.55,2,140,3,0,1,0,hr,low
0.84,0.87,4,246,6,0,1,0,hr,low
0.1,0.94,6,255,4,0,1,0,technical,low
0.38,0.46,2,137,3,0,1,0,technical,low
0.45,0.5,2,126,3,0,1,0,technical,low
0.11,0.89,6,306,4,0,1,0,technical,low
0.41,0.54,2,152,3,0,1,0,technical,low
0.87,0.88,5,269,5,0,1,0,technical,low
0.45,0.48,2,158,3,0,1,0,technical,low
0.4,0.46,2,127,3,0,1,0,technical,low
0.1,0.8,7,281,4,0,1,0,technical,low
0.09,0.89,6,276,4,0,1,0,technical,low
0.84,0.74,3,182,4,0,1,0,technical,low
0.4,0.55,2,147,3,0,1,0,support,low
0.57,0.7,3,273,6,0,1,0,support,low
0.4,0.54,2,148,3,0,1,0,support,low
0.43,0.47,2,147,3,0,1,0,support,low
0.13,0.78,6,152,2,0,1,0,support,low
0.44,0.55,2,135,3,0,1,0,support,low
0.38,0.55,2,134,3,0,1,0,support,low
0.39,0.54,2,132,3,0,1,0,support,low
0.1,0.92,7,307,4,0,1,0,support,low
0.37,0.46,2,140,3,0,1,0,support,low
0.11,0.94,7,255,4,0,1,0,support,low
0.1,0.81,6,309,4,0,1,0,technical,low
0.38,0.54,2,128,3,0,1,0,technical,low
0.85,1,4,225,5,0,1,0,technical,low
0.85,0.91,5,226,5,0,1,0,management,medium
0.11,0.93,7,308,4,0,1,0,IT,medium
0.1,0.95,6,244,5,0,1,0,IT,medium
0.36,0.56,2,132,3,0,1,0,IT,medium
0.11,0.94,6,286,4,0,1,0,IT,medium
0.81,0.7,6,161,4,0,1,0,IT,medium
0.43,0.54,2,153,3,0,1,0,product_mng,medium
0.9,0.98,4,264,6,0,1,0,product_mng,medium
0.76,0.86,5,223,5,1,1,0,product_mng,medium
0.43,0.5,2,135,3,0,1,0,product_mng,medium
0.74,0.99,2,277,3,0,1,0,IT,medium
0.09,0.77,5,275,4,0,1,0,product_mng,medium
0.45,0.49,2,149,3,0,1,0,product_mng,high
0.09,0.87,7,295,4,0,1,0,product_mng,low
0.11,0.97,6,277,4,0,1,0,product_mng,medium
0.11,0.79,7,306,4,0,1,0,product_mng,medium
0.1,0.83,6,295,4,0,1,0,product_mng,medium
0.4,0.54,2,137,3,0,1,0,marketing,medium
0.43,0.56,2,157,3,0,1,0,sales,low
0.39,0.56,2,142,3,0,1,0,accounting,low
0.45,0.54,2,140,3,0,1,0,support,low
0.38,0.49,2,151,3,0,1,0,technical,low
0.79,0.59,4,139,3,0,1,1,management,low
0.84,0.85,4,249,6,0,1,0,marketing,low
0.11,0.77,6,291,4,0,1,0,marketing,low
0.11,0.87,6,305,4,0,1,0,marketing,low
0.17,0.84,5,232,3,0,1,0,sales,low
0.44,0.45,2,132,3,0,1,0,sales,low
0.37,0.57,2,130,3,0,1,0,sales,low
0.1,0.79,6,291,4,0,1,0,sales,low
0.4,0.5,2,130,3,0,1,0,sales,low
0.89,1,5,246,5,0,1,0,sales,low
0.42,0.48,2,143,3,0,1,0,sales,low
0.46,0.55,2,129,3,0,1,0,sales,low
0.09,0.83,6,255,4,0,1,0,sales,low
0.37,0.51,2,155,3,0,1,0,sales,low
0.1,0.77,6,265,4,0,1,0,sales,low
0.1,0.84,6,279,4,0,1,0,sales,low
0.11,0.97,6,284,4,0,1,0,sales,low
处理结果 :
数据清洗:
1)样本抽样
2)异常值(空值处理)
特征处理:
- 特征选择
- 特征变换,对指化、离散化、数据平滑、归一化(标准化)、数值化、正规化
- 特征降维
- 特征衍生

















 767
767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









