







什么是缓存穿透:客户端请求的数据库都不存在,这样缓存就永远不会生效,这些请求都会打到数据库
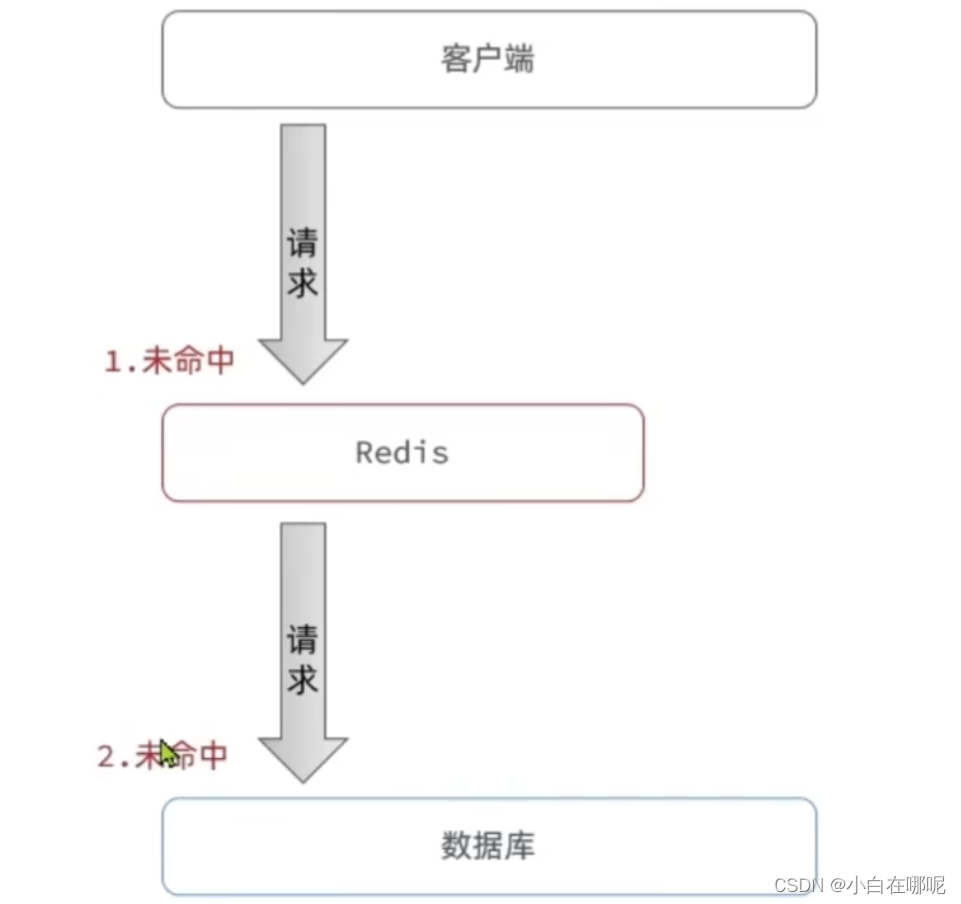
有如下解决方案:
- 缓存空对象,
- 优点:实现简单,维护方便
- 缺点:
- 额外的内存消耗
- 可以设置较短的TTL过期时间
- 造成短期不一致
- 当更新的时候手动更新redis中的数据
- 额外的内存消耗
- 布隆过滤
- 是一种算法
- 如何知道有没有?
- 简单理解成是一个Byte‘数组,里面存的是二进制位,当要去判断数据库中的数据是否存在的时候,并不是真的把数据存储到布隆过滤器,而是把这些数据基于某一种算法hash算法,计算出hash值,然后在将这些hash值转换成二进制位,保存到布隆过滤器中,(01)的形式保存,判断数据是否存在,其实就是判断对应的位值, 是一种概率上的统计,不是百分表准确,不存在的时候是真的不能存在,存在的时候也不一定存在,所以说还是有穿透的风险。
- 优点:内存占用少,没有多余Key
- 缺点:实现复杂,存在误判可能
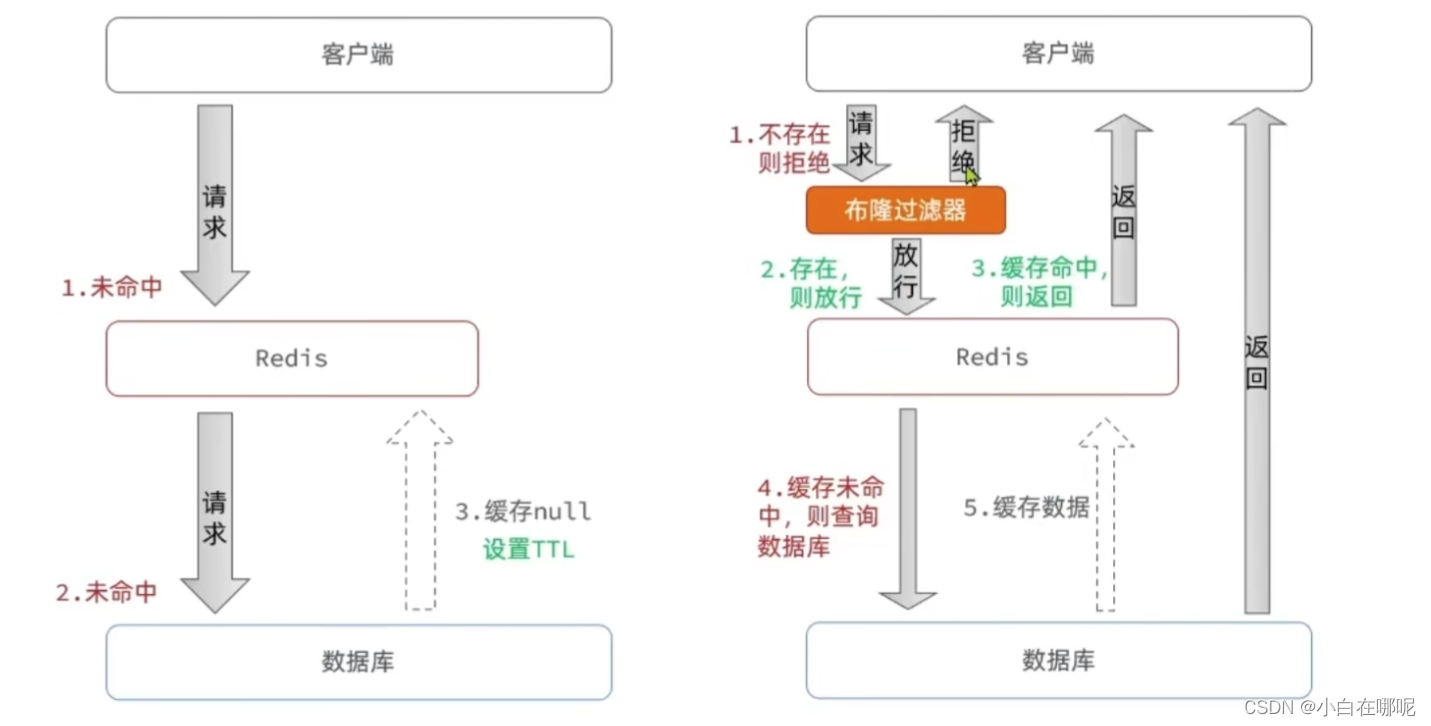
- 增强id的复杂度,避免被猜测id规律
- 长度保证在10位或者20位,有一定的规律性
- 做好数据的基础格式校验
- 用户权限校验,
- 做好热点参数的限流
- 附代码实现
//缓存穿透
public <R,ID>R queryWithPassThrough(String keyPrefix, ID id, Class<R>type, Function<ID,R>dbFallBack,Long time,TimeUnit unit){
String key = keyPrefix +id;
//从redis中查询缓存
String json = stringRedisTemplate.opsForValue().get(key);
//如果存在,直接返回
if(StrUtil.isNotBlank(json)){
return JSONUtil.toBean(json,type);
}
//如果不存在
if(json != null){
//返回一个错误信息
return null;
}
//不存在,查询
R r = dbFallBack.apply(id);
if(r==null){
stringRedisTemplate.opsForValue().set(key,"",20,TimeUnit.MINUTES);
return null;
}
this.set(key, r,time,unit);
return r;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









