







IQR 方法背景
- 四分位数的计算并不依赖于特定的概率分布假设。它是一种非参数方法,适用于任何数据集的分析,无论其分布类型。
-
四分位数(Quartiles):
- Q1(下四分位数)是将数据集分为四部分的第一个分位数,即将数据排序后 25% 的数据位于这个值之下。
- Q3(上四分位数)是将数据集分为四部分的第三个分位数,即将数据排序后 75% 的数据位于这个值之下。
- IQR(四分位数间距)定义为 QR=Q3−Q1,代表中间 50% 数据的范围。
-
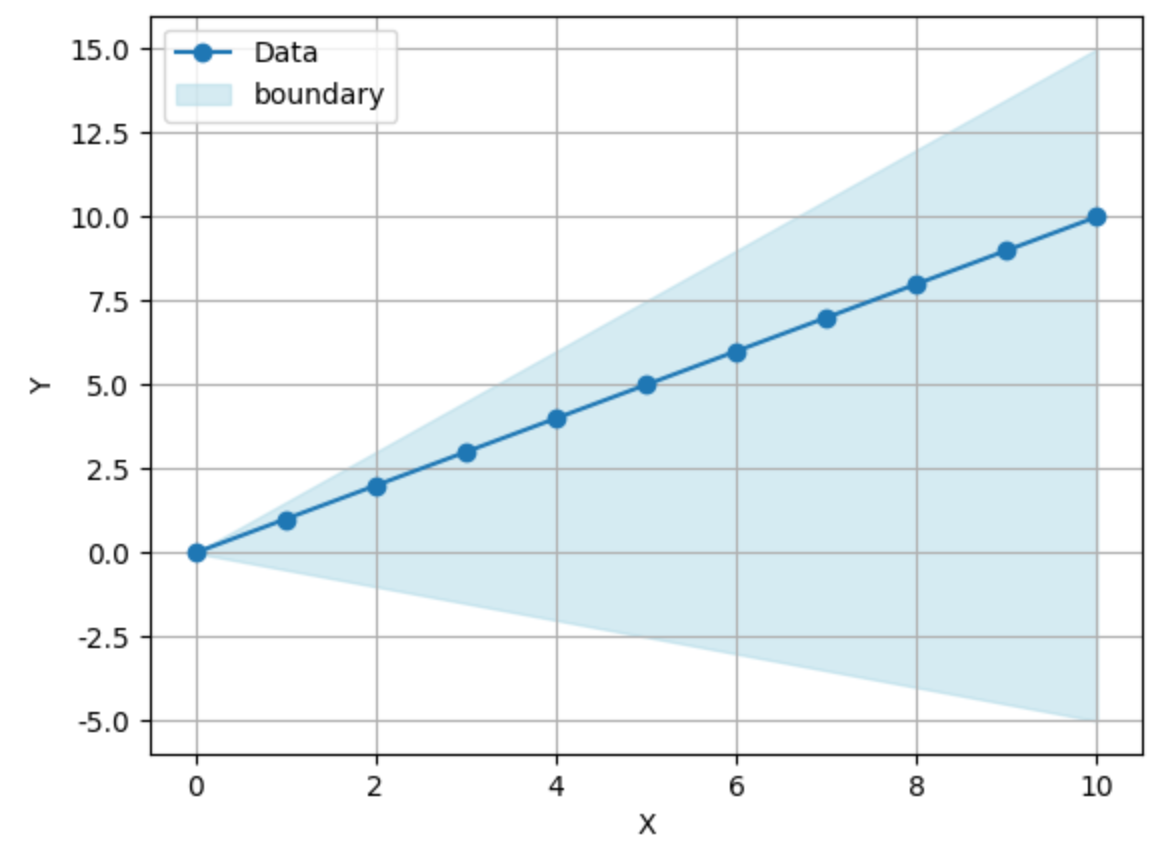
异常值的界定:
- 为了确定哪些点被视为异常值,常用的规则是:
- 上限(Upper Bound) = Q3+1.5×IQR
- 下限(Lower Bound) = Q1−1.5×IQR
- 为了确定哪些点被视为异常值,常用的规则是:
代码实现
 </
</

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 1209
1209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











