







第一章 iptable的使用
一、实验原理
1.1 Iptables
Iptables 是用来设置、维护和检查Linux内核的IP包过滤规则的。
可以定义不同的表,每个表都包含几个内部的链,也能包含用户定义的链。每个链都是一个规则列表,对对应的包进行匹配:每条规则指定应当如何处理与之相匹配的包。这被称作‘target’(目标),也可以跳向同一个表内的用户定义的链。
Iptables中的filter表一般就是用来配置过滤用的。
1.2 Iptables的优点
Iptables的最大优点是它可以配置有状态的防火墙,这是ipfwadm和ipchains等以前的工具都无法提供的一种重要功能。有状态的防火墙能够指定并记住为发送或接收信息包所建立的连接的状态。防火墙可以从信息包的连接跟踪状态获得该信息。在决定新的信息包过滤时,防火墙所使用的这些状态信息可以增加其效率和速度。这里有四种有效状态,名称分别为ESTABLISHED、INVALID、NEW和RELATED。
状态ESTABLISHED指出该信息包属于已建立的连接,该连接一直用于发送和接收信息包并且完全有效。INVALID状态指出该信息包与任何已知的流或连接都不相关联,它可能包含错误的数据或头。状态NEW意味着该信息包已经或将启动新的连接,或者它与尚未用于发送和接收信息包的连接相关联。最后,RELATED表示该信息包正在启动新连接,以及它与已建立的连接相关联。
iptables的另一个重要优点是,它使用户可以完全控制防火墙配置和信息包过滤。用户可以定制自己的规则来满足特定需求,从而只允许用户想要的网络流量进入系统。
另外,iptables是免费的,这对于那些想要节省费用的人来说十分理想,它可以代替昂贵的防火墙解决方案。
1.3 链表结构
四个表:
iptables由四个表:filter,nat,mangle,raw,默认表是filter(没有指定表的时候就是filter表)。表的处理优先级:raw>mangle>nat>filter。
- filter:一般的过滤功能
- nat:用于nat功能(端口映射,地址映射等)
- mangle:用于对特定数据包的修改
- raw:有限级最高,设置raw时一般是为了不再让iptables做数据包的链接跟踪处理,提高性能。
五个链:
这五个规则链也被称为五个钩子函数(hook functions),五个位置。
- REROUTING (路由前):内核空间中,从一个网络接口进来,到另一个网络接口去的
- INPUT (数据包流入口):数据包从内核流入用户空间的
- FORWARD (转发管卡):数据包从用户空间流出的
- OUTPUT(数据包出口):进入/离开本机的外网接口
- POSTROUTING(路由后):入/离开本机的内网接口
二、基本使用
2.1 查看相关信息
- 查看版本信息:
iptables -V - 查看安装路径“:
whereis iptables - 查看帮助:
iptables --help
2.2 查看表和每个表中的规则
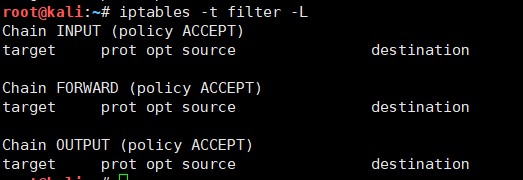
- 查看filter表中的规则:
iptables -t filter –L
- 查看Nat表中的规则:
iptables -t nat -L

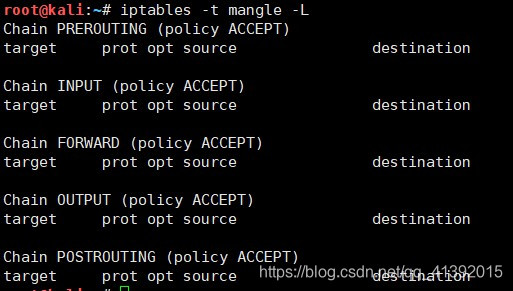
- 查看Mangle表中的规则:
iptables -t mangle –L
- 查看Raw表中的规则:
iptables -t raw –L - 查看所有表:见第7点图。(文件
ip_tables_names) - 查看某条链的规则:
iptables -t filter/nat/mangle/raw -L INPUT/OUTPUT/FORWARD/PREROUTING/POSTROUTING查看某条链的rule。
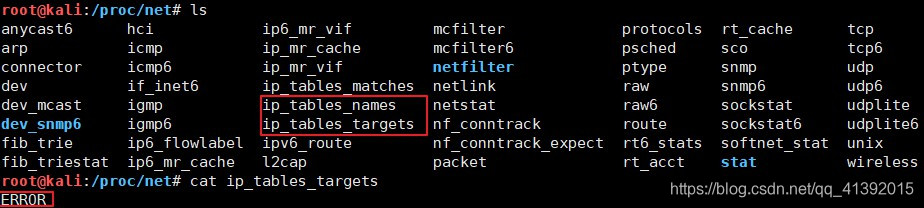
如查看nat表PREROUTING链中的规则:iptables –t nat –L PREROUTING。 - 查看Iptables有哪些target:目录:
/proc/net
2.3 删除表中的规则
- 删除每个非内建的链:
iptables –t /raw/mangle/nat/filter –X。如:iptables -t raw -X,因为此时没有建链,所以没效果 - 清空链中的规则:
iptables –t raw/mangle/nat/filter –F。其实就是把规则一个个删除。(注:-F删除,-L查看)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 736
736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









