



 本文介绍了爬虫的基础概念,包括获取网页、数据类型、JavaScript渲染页面的处理、Session和Cookie的作用、静态与动态网页的区别、HTTP无状态机制以及如何处理登录状态。还探讨了代理的基本原理、爬虫中的代理使用、多线程和多进程在并发中的应用。
本文介绍了爬虫的基础概念,包括获取网页、数据类型、JavaScript渲染页面的处理、Session和Cookie的作用、静态与动态网页的区别、HTTP无状态机制以及如何处理登录状态。还探讨了代理的基本原理、爬虫中的代理使用、多线程和多进程在并发中的应用。

1.爬虫概述
爬虫就是获取网页并提取和保存信息的自动化程序。
-
获取网页
就是获取网页的源代码
-
提取信息
获取网页的源代码后,接下来就是分析源代码,从中提取我们想要的数据
-
保存数据
提取信息后,保存到某处以便后续使用。
-
自动化程序
自动化程序的意思是爬虫可以代替人来完成上述操作。

2. 能爬怎样的数据
常见的是HTML源代码,但有可能是JSON字符串。

3. JavaScript渲染的页面
有些网站是由JavaScript渲染的页面,原始的HTML代码是空壳。
对于这种情况,可以分析源代码后台Ajax接口,也可以使用Selenium、Splash、Pyppeteer、Playwright等库来模拟JavaScript渲染。

1.4 Session和Cookie
在浏览网站的过程中,经常会遇到需要登录的情况,有些网页必须登录之后才能访问。

1. 静态网页和动态网页
静态网页加载速度快,编写简单,同时存在缺陷,比如维护性差,不能根据URL灵活多变的显示内容。
动态网页可以动态解析URL中参数的变化,关联数据库并动态呈现不同的页面内容,此外还可以实现用户登录和注册的功能。

2. 无状态HTTP
HTTP的无状态是指HTTP协议是对事务处理没有记忆的,或者说服务器并不知道客户端处于什么状态。
保持HTTP连接状态的方法,Session和Cookit。
Session在服务端,也就是网站的服务器,用来保存用户的Session信息;Cookit在客户端,也可以理解为浏览器端,有了Cookit,浏览器在下次访问相同的网站时会自动附带Cookit,并发给服务器,服务器通过识别Cookit鉴定出是哪个用户在访问,然后判断此用户是否处于登录状态,并返回对应的响应。

3. Session
中文称为会话,是指有始有终的一系列动作、消息。
例如打电话,从拿起电话拨号到挂断电话之间的一系列操作过程,就可以称为一个Session。
Web中,Session对象用来存储特定用户所需的属性及配置信息。这样用户在应用程序的页面跳转时,存储在Session对象中的对象将不会丢失,会在整个用户Session中一直存在下去。
当用户请求来自应用程序的页面时,如果该用户还没有Session,那么Web服务器将会创建一个Session对象。
当用户的Session过期或者放弃,服务器将会终止Session服务。

4. Cookit
Cookit,指某些网站为了鉴别用户身份,进行Session跟踪而存储在用户本地终端上的数据。
- Session维持
保持Cookit登录状态
原理:
客户端第一次请求服务器时,服务端会返回一个响应头,响应头中带有Set-Cookit字段的响应给客户端,这个字段用来标记用户。客户端浏览器会保存Cookit,当下一次访问相同网站时,把保存的Cookit放到请求头中一起提交给服务器。Cookit中携带有SessionID的相关信息,服务器通过检查Cookit找到相应的Session,继而判断Session辨认用户状态。如果Session当前是有效,就证明用户处于登录状态,此时服务器返回登录之后才可以查看网页内容,浏览器再进行解析就可以看到了。
如果传个服务器是无效的Cookit,或者过期了,客户端将不能继续访问页面,此时可能会收到错误的响应或者跳转到登录页面重新登录。
Cookit和Session需要配合,一个在客户端,一个在服务端,就可以登录控制。
-
属性结构
浏览器开发者工具打开Application选项卡,左侧有一个Storage,Storage的最后一项为Cookit。
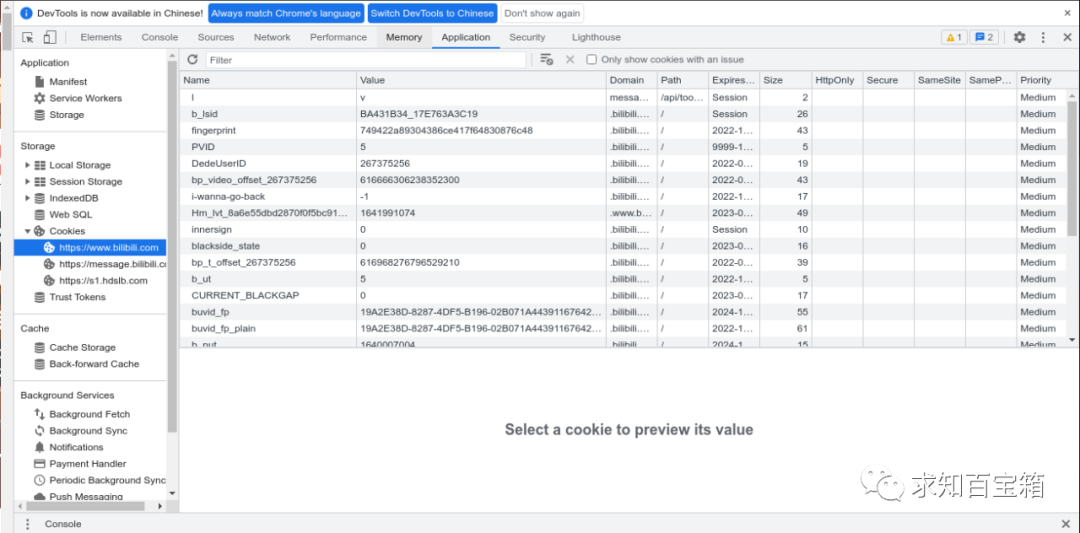
每一个条目都为一个Cookit条目。
Cookit属性:
-
Name: Cookit的名称。不可更改
-
Value: Cookit的值。如果值为Unicode字符,则需要为字符编码。如果值为二进制数据,则需要BASE64编码。
-
Domain: 指定可以访问该Cookit的域名。
-
Path: Cookit的使用路径。
-
Max-Age: Cookit失效的时间,单位为秒
-
Size字段: Cookit的大小。
-
HTTP字段: Cookit的httponly属性。
-
Secure: 是否仅允许使用安全协议传输Cookit。安全协议有HTTPS和SSL等,使用这些协议在网络上传输数据之前会先将数据加密。其默认值为false。
-
会话Cookit和持久Cookit
会话Cookit就是把Cookit放到浏览器内存里,关闭浏览器后,Cookit即失效;
持久Cookit则会把Cookit保存到硬盘里,以便下次使用。
Max-Age与Expires字段决定了Cookit失效时间。

5. 常见误区
关闭浏览器并不会删除用户数据,服务器会一直保留用户数据,只有通知程序才能进行删除用户数据。
例如,进行注销操作才会进行删除用户数据(Session)。

1.5 代理的基本原理

1. 代理的基本原理
代理是指代理服务器,英文Proxy Server。
原理:
当客户端正常请求一个网站时,请求发个web服务器,web服务器再把响应传回客户端。
设置代理服务器,就是再客户端和服务端之间搭建一座桥,此时并非直接向web服务器发起请求,而是把请求发给代理服务器,然后由代理服务器把请求发送给web服务器,web服务器返回的响应也是由代理服务器转发给客户端。客户端可以正常访问网页,这个过程中web服务器识别出的真实IP就不是客户端IP。

2. 代理的作用
代理作用:
-
突破自身IP的访问限制,访问一些不能访问的
-
访问一些单位或团体的内部资源
-
提高访问速度
-
隐藏真实IP

3. 爬虫代理
对于爬虫来说,由于爬虫速度过快,因此在爬取过程中可能遇到同一个IP访问关于频繁的问题,此时网站会让我们输入验证码登录或直接封锁IP。
使用代理隐藏真实的IP,让服务器误以为是代理服务器在请求自己,这样可以避免IP被封锁。

4. 代理分类
根据协议和代理的匿名程度,这两种分类总结如下:
协议区分:
-
FTP代理服务器: 主要用于访问FTP服务器,一般有上传、下载以及缓存功能,端口一般为21、2121等
-
HTTP代理服务器: 主要用于访问网页,一般有内容过滤和缓存功能,端口一般为80、8080、3128等
-
SSL/TLS代理: 主要用于访问加密网站,一般有SSL或TLS加密功能(最高支持128位加密),端口一般为443
-
RTSP代理: 主要用于Realplayer访问Real流媒体服务器,一般有缓存功能,端口一般为554
-
Telnet代理: 主要用于Telnet远程控制(黑客用于隐藏身份),端口一般为23
-
POP3/SMTP代理: 主要用于以POP3/SMTP方式收发邮件,一般有缓存功能,端口一般为110/25
-
SOCKS代理: 只是单纯的传递数据,不关心具体用法和协议,速度很快,一般有缓存功能,端口一般为1080
SOCKS代理分为SOCKS4,SOCKS5,SOCKS4使用TCP,SOCKS使用TCP和UDP,还支持各种身份验证机制、服务器端域名解析等。
匿名程度区分:
高度匿名代理: 高度匿名代理会将数据包原封不动的转发,在服务器看来只是一个普通客户端在访问,记录的IP则是代理服务器的IP。
普通匿名代理: 普通匿名代理会对数据包做一些改动,服务端可能会发现正在访问自己的是个代理服务器,并且有一定可能会追查到客户端真实IP。
透明代理: 透明代理不但改动了数据包,还会告诉服务器客户端的真实IP
间谍代理: 间谍代理是由组织或个人创建的代理服务器,用于记录用户传输的数据,然后对记录的数据进行数据研究、监控等。

5. 常见代理设置
常见的代理设置:
-
对于网上的免费代理,最好使用高度匿名代理,可以在使用前把所有代理都抓取下来筛选可用代理,也可以维护一个代理池。
-
使用付费代理服务。
-
ADSL拨号,拨一次号换一次IP,稳定性高。
-
蜂窝代理,即用4G和5G网卡等制作的代理,成本高。

1.6 多线程和多进程的基本原理
1. 多线程的含义
进程可以理解为一个独立运行的程序单位。
浏览器打开多个页面,有的网页播放音乐,有点页面可以播放视频,这些任务可以同时进行,互不干扰,每一个任务对应一个线程。
进程有多个线程的构成。

2. 并发和并行
并发是指多个线程对应的多条指令被快速轮换的执行。
并行是指同一时刻有多条指令在多个处理器上同时执行,着意味着并行必须依赖多个处理器。

3. 多线程适用场景
执行一个操作需等待,然后才能执行另一个任务,这叫做IO密集型任务。
计算机密集型任务,任务的运行一直需要处理器的参与,例如,开启了多线程,处理器从一个计算机密集型任务切换到另一个密集型任务,处理器不会停下来,一直忙于计算。
任务不全是计算机密集型任务,就可以使用多线程来提高程序整体的执行效率。

4. 多进程的含义
进程可以理解为一个独立运行的程序单位。
浏览器打开多个页面,有的网页播放音乐,有点页面可以播放视频,这些任务可以同时进行,互不干扰,每一个任务对应一个线程。
进程有多个线程的构成。

5. Python中的多线程和多进程
GIL: 全局解锁器锁
Python多线程下,每个线程的执行方式分为三步:
-
获取GIL
-
执行对应线程的代码
-
释放GIL
某个线程想执行,必须有GIL。
本文转自 https://mp.weixin.qq.com/s/1KF2hWeEoIUcTJMDUybCuw,如有侵权,请联系删除。
题外话
当下这个大数据时代不掌握一门编程语言怎么跟的上脚本呢?当下最火的编程语言Python前景一片光明!如果你也想跟上时代提升自己那么请看一下.

感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。

一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试宝典


简历模板
若有侵权,请联系删除

















 57万+
57万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









