







1数据集介绍
采用了清华NLP组提供的THUCNews新闻文本分类数据集的子集。其中训练集一共有 180000 条,验证集一共有 10000 条,测试集一共有 10000 条。其类别为 finance、realty、stocks、education、science、society、politics、sports、game、entertainment 十个类别。
2、TextCNN模型
TextCNN 由 输入层、卷积层、池化层、全连接层组成,整体架构与计算机视觉中的 CNN 模型类似。其结构图如下:
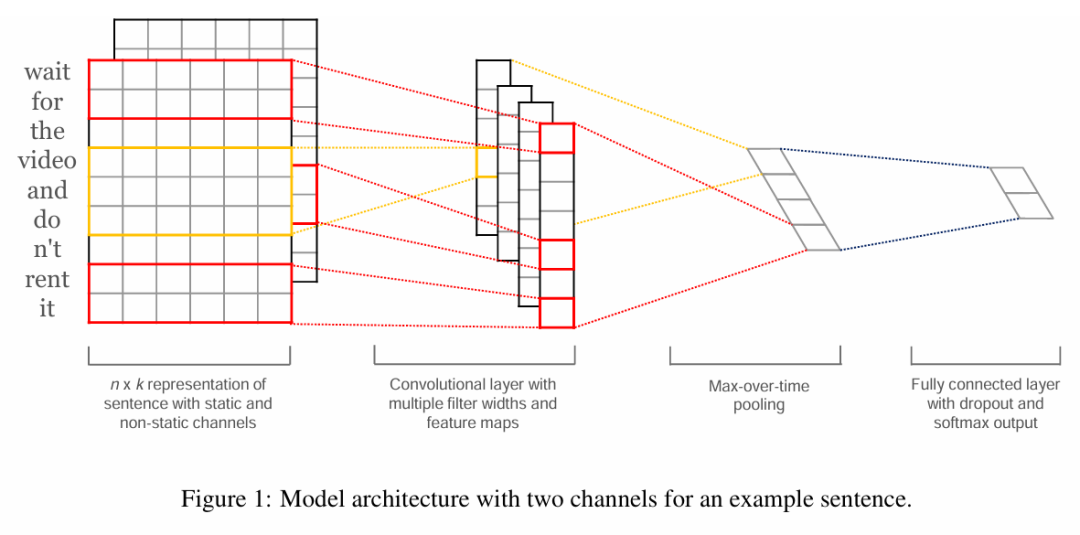
参考文献:https://arxiv.org/abs/1408.5882
3、代码实现
文末免费获取数据集和源码压缩包。
# -*- coding:utf-8 -*-
import argparse
import os.path
def parsers():
parser = argparse.ArgumentParser(description="TextCNN model of argparse") parser.add_argument("--train_file", type=str, default=os.path.join("data", "train.txt")) parser.add_argument("--dev_file", type=str, default=os.path.join("data", "dev.txt")) parser.add_argument("--test_file", type=str, default=os.path.join("data", "test.txt")) parser.add_argument("--classification", type=str, default=os.path.join("data", "class.txt"))
parser.add_argument("--data_pkl", type=str, default=os.path.join("data", "dataset.pkl")) parser.add_argument("--class_num", type=int, default=10)
parser.add_argument("--max_len", type=int, default=38)
parser.add_argument("--embedding_num", type=int, default=100)
parser.add_argument("--batch_size", type=int, default=32)
parser.add_argument("--epochs", type=int, default=30)
parser.add_argument("--learn_rate", type=float, default=1e-3)
parser.add_argument("--num_filters", type=int, default=2, help="卷积产生的通道数") parser.add_argument("--save_model_best", type=str, default=os.path.join("model", "best_model.pth"))
parser.add_argument("--save_model_last", type=str, default=os.path.join("model", "last_model.pth"))
args = parser.parse_args()
return args训练曲线及测试精度:
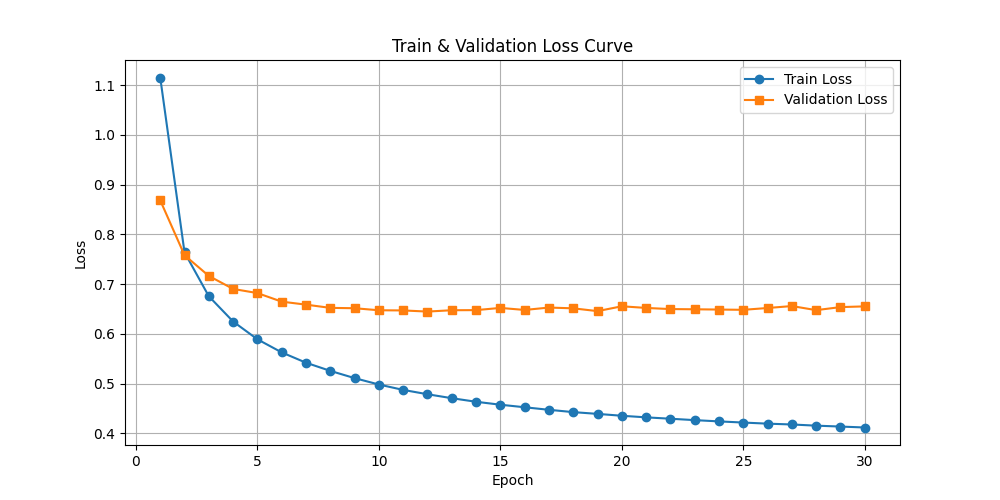
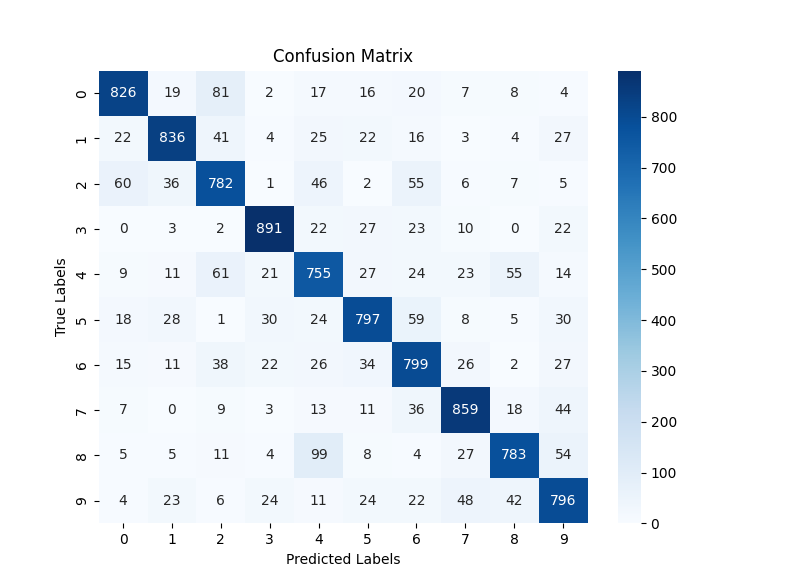

进入下面公众号聊天窗口回复“TextCNN文本分类”即可获取完整源码。
最后:
小编会不定期发布相关设计内容包括但不限于如下内容:信号处理、通信仿真、算法设计、matlab appdesigner,gui设计、simulink仿真......希望能帮到你!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











