







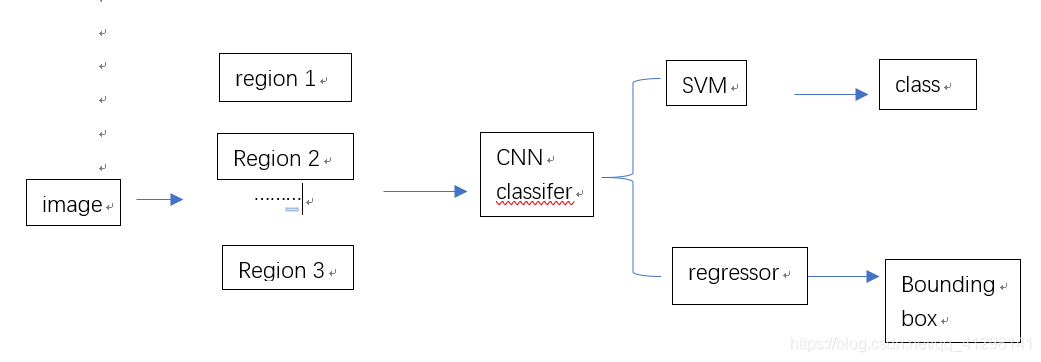
 R-CNN是一种基于选择性搜索的区域建议方法,它使用CNN提取特征并结合SVM进行目标分类和边界框回归,以实现目标检测。通过预训练的AlexNet进行特征提取,然后针对每个类别训练SVM分类器和回归器。测试阶段,通过SVM打分和非极大值抑制确定最终检测结果。尽管R-CNN提高了目标检测的准确性,但其计算效率较低。
R-CNN是一种基于选择性搜索的区域建议方法,它使用CNN提取特征并结合SVM进行目标分类和边界框回归,以实现目标检测。通过预训练的AlexNet进行特征提取,然后针对每个类别训练SVM分类器和回归器。测试阶段,通过SVM打分和非极大值抑制确定最终检测结果。尽管R-CNN提高了目标检测的准确性,但其计算效率较低。
目录
R-CNN
自从Alexnet获得2012年 ILSVRC 2012冠军后,用CNN进行分类成为主流。原始的用于目标检测的暴力方法是从左到右,从上到下滑动窗口,利用分类识别目标。为了在不同观察距离处检测不同的目标类型,需要使用不同大小和宽高比的窗口。
- R-CNN提出了选择性搜索,用候选区域方法创建目标检测的ROI。首先将每个像素作为一组,然后计算每组的纹理,并将两个最接近的组结合起来,继续合并区域,直到所有区域都结合在一起。这样可以减少一部分计算量。
- 下一步取出可能含有目标的ROI送入CNN中提取特征。因为CNN通常是接收一个固定大小的图像,而取出的区域通常大小不一样,因此需要对这些区域进行统一缩放到一定的大小,再使用CNN提取特征
- 提取的特征再使用SVM进行分类,最后通过非极大值抑制输出结果
R-CNN基本结构
训练的数据库:
一个较大的识别库 (Imagenet ILSVC 2012)有1000个类别 一千万张图像 用于预训练
一个较小的检测库(PASCAL VOC 2007)20个类别 1万张图像 用于调优参数
训练步骤:
一:对VOC 2007数据集中所有图像采用selective search方式获取region proposal ,每个图像大约得到2000个region proposal
二:准备正负样本。如果region proposal与ground truth的IOU大于等于0.5,则为正样本,否则为负样本。ground truth 也为正样本。
三:预训练。采用AlexNet学习特征,包含5个卷积层和两个全连接层
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









