




1.描述
抓取北极星电力网的文章标题和内容
2.思路
01.分析当前页面URL
经过反复测试,发现URL具有以下规则,同时最大只能到99页,第100页没有数据,于是
# 循环遍历第1页到第99页
bjx_power_urls = ["http://news.bjx.com.cn/list?catid=111&page={}".format(str(i)) for i in range(1,100)]
02.分析所有文章的URL
因为我们要抓取里面的文章,每一页下面有56条文章,每个文章对应一个URL,所以一页有56个URL,所以我们需要找到URL里面嵌套的URL
''' 省略部分代码,完整代码请关注公众号ElevenKeep回复爬虫02获取 '''
# 通过a标签拿到链接
for a in li.find_all('a'):
title.append(a.string) # 文章标题
link.append(a['href']) # 文章链接
# 为了更快速读取,引入了线程池
bjx_Pool = multiprocessing.Pool(2) # 线程池
# link是a标签下所有的链接
for content_url in link:
# 获取链接里面所有文章
bjx_Pool.apply_async(open_bjx_content(content_url))
03.数据保存的二种方式
- 第一种存储到csv文件中
''' CSV '''
try:
# 根据class元素查找下面所以的p标签,因为p标签里面是文章内容
pList = bsobj.find('div', attrs = {'class': ['list_detail','hydetail_content']}).find_all('p')
content = ''
for p in pList:
content += p.text + '\n'
data = ({"title": [title], "content": [content]})
content = pd.DataFrame(data,index=[0])
content.to_csv('北极星-标题-文章.csv', index=False, mode='a', header=False, encoding="utf_8_sig")
return content
except:
print("图片未保存")
-
第二种是存储到数据库中
以下2中其中一种都可以
''' sqlalchemy导出到MySQL '''
data_sql = pd.DataFrame({"title": [title], "content": [content]})
# 分别是用户名、密码、ip地址、数据库名称、编码格式
engine = create_engine("mysql+pymysql://{}:{}@{}/{}?charset={}".format('root', '123456', '127.0.0.1:3306', 'bjx', 'utf8'))
con = engine.connect() # 创建连接
# bjx_title_content是表的名称
data_sql.to_sql(name='bjx_title_content', con=con, if_exists='append', index=False)
conn.commit()
conn.close()
''' pymysql '''
conn = pymysql.connect(
host = "127.0.0.1",
port = 3306,
user = "root",
password ="123456",
database = "bjx",
charset = "utf8")
cursor = conn.cursor()
sql = 'insert into bjxs_title_content(bjx_title,bjx_content) values(%s,%s);'
cursor.execute(sql, [title,content])
conn.commit()
conn.close()
3.代码
''' 完整代码如下,点下面链接获取 '''
https://www.toutiao.com/i6853641485221364238/
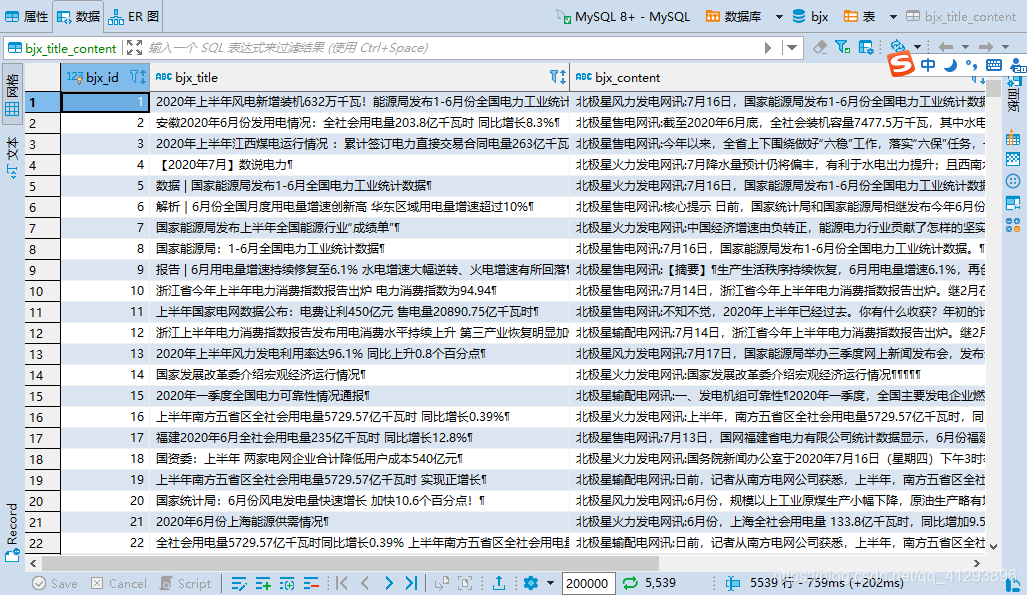
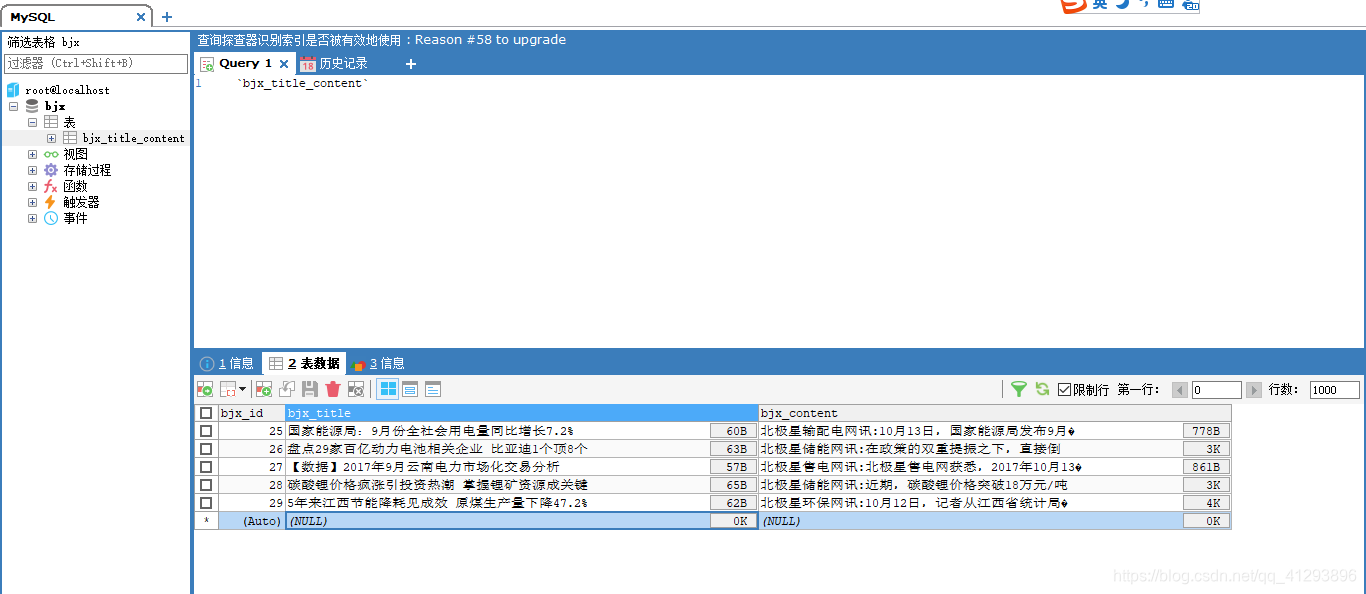
- 数据库数据
4.问题
以下是我做的过程中,遇到的问题
01.request库返回403
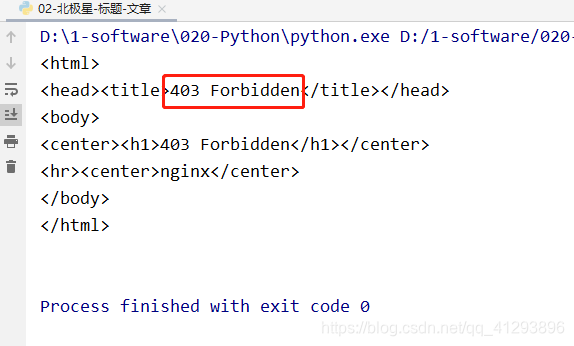
解决办法:
加入header的user-agent
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36"
}
02.UnicodeDecodeError:'utf-8’编解码器无法解码位置191的字节0xca:无效的继续字节
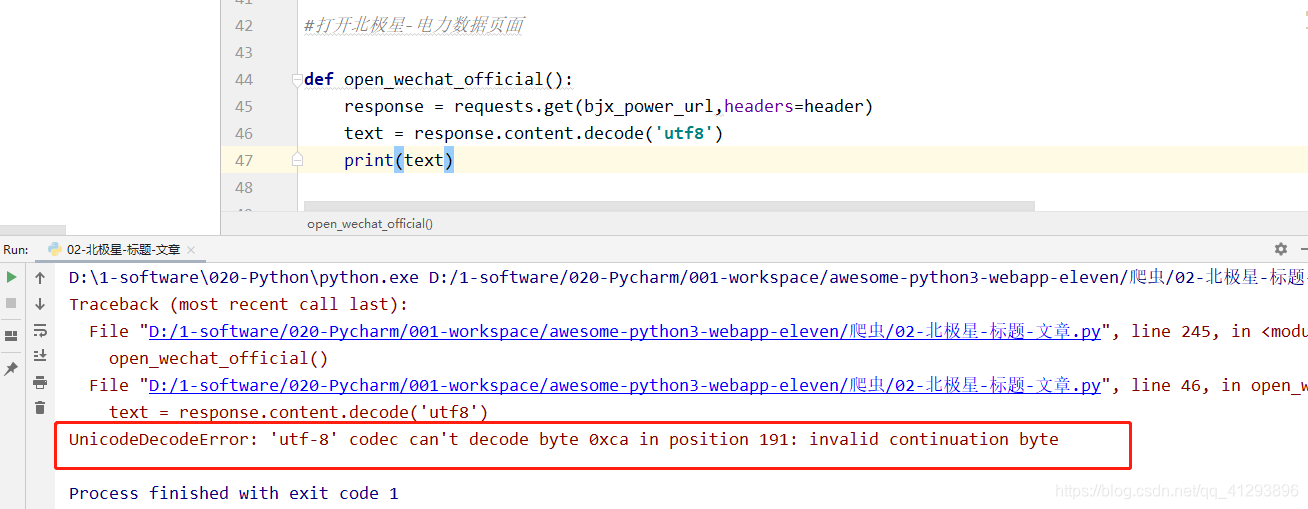
解决方法:
将编码格式改成GBK
def open_wechat_official():
response = requests.get(bjx_power_url,headers=header)
text = response.content.decode('gbk')
print(text)
03.python生成的csv文件是乱码
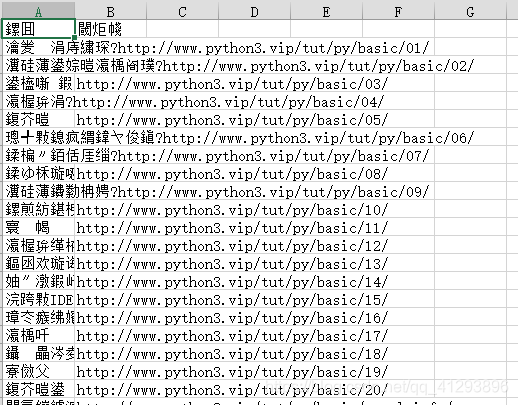
解决方法:
new_data.to_csv('北极星-标题-文章01.csv', index=False, mode='a', header=False,encoding="utf_8_sig")
04.找不到这个属性text

我这个是链接问题,链接弄错了
05.抓取过程中,class的值变了(真是,好不容易看到了胜利的曙光,瞬间浇灭)
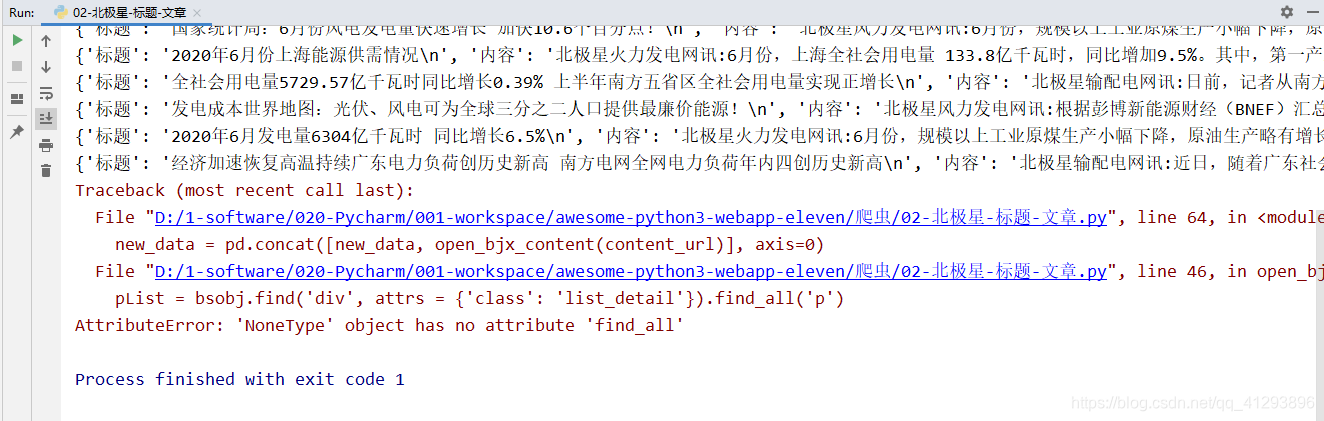
解决方法
既然class会变,那就把变化的加到规则里面
pList = bsobj.find('div', attrs = {'class': ['list_detail','hydetail_content']}).find_all('p')
06.pandas设置Excel不自动换行
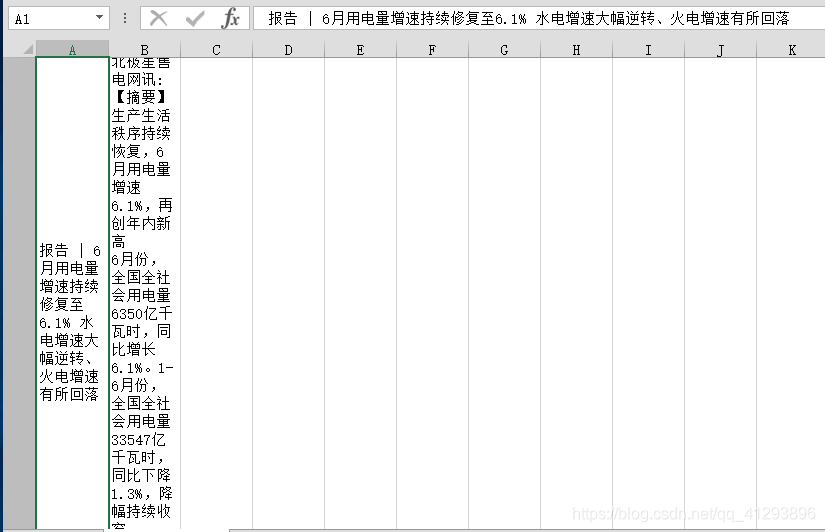
解决方法
pd.set_option('display.width', 100000) # 当consel中输出的列书超过1000的时候才会换行
07.控制台提示Data too long for column 'content' at row 1
解决方法:
很明显,内容ID的值太大(超过64Kb)。考虑使用另一个,例如MEDIUMBLOB或LONGBLOB:
BLOB类型对象类型对象可以容纳的值长度,从0到255字节的TINYBLOB,从0到65535字节的BLOB,从0到16777215字节的MEDIUMBLOB,从0到4294967295 295字节的LONGBLOB
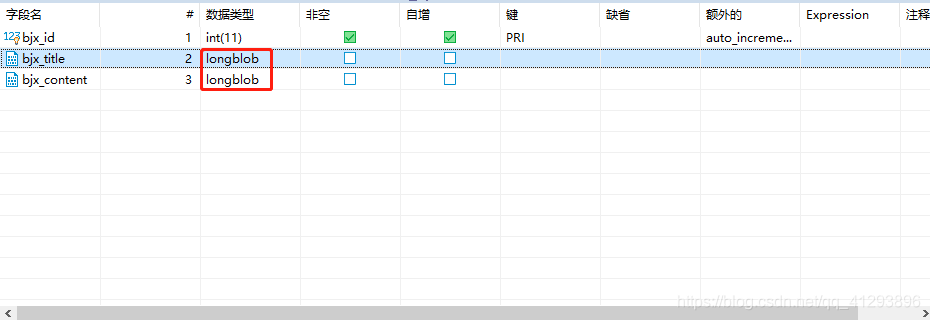
08.MySQL数据是乱码
如下图:
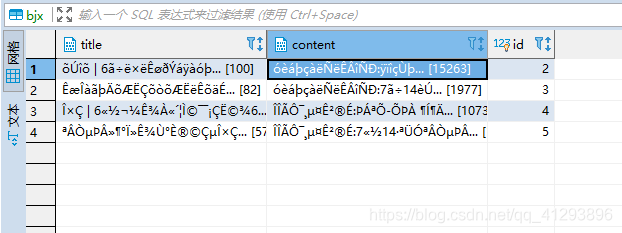
解决办法:
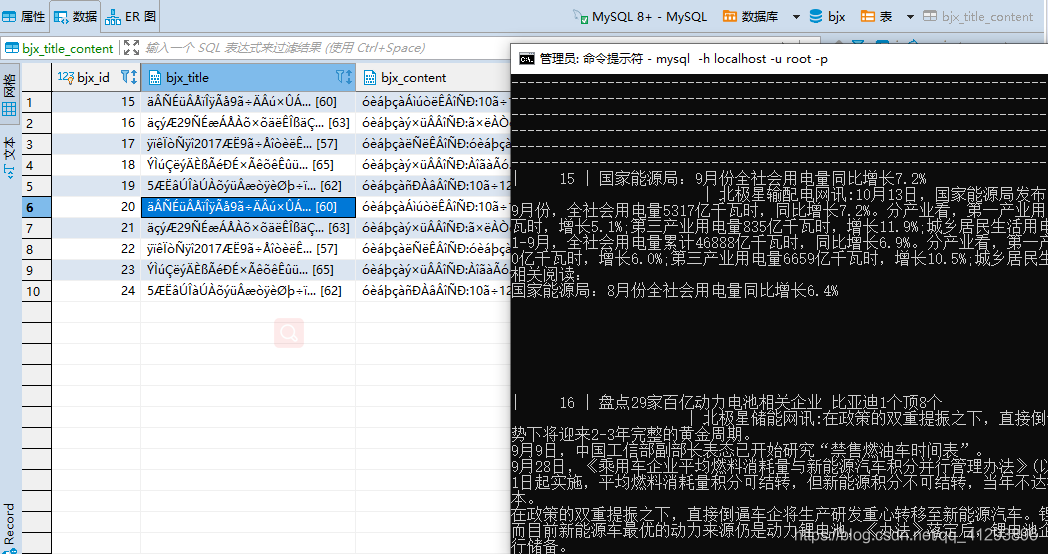
1.该问题是Dbeaver的问题,MySQL没有该问题,换成了SQLyog(治标不治本)
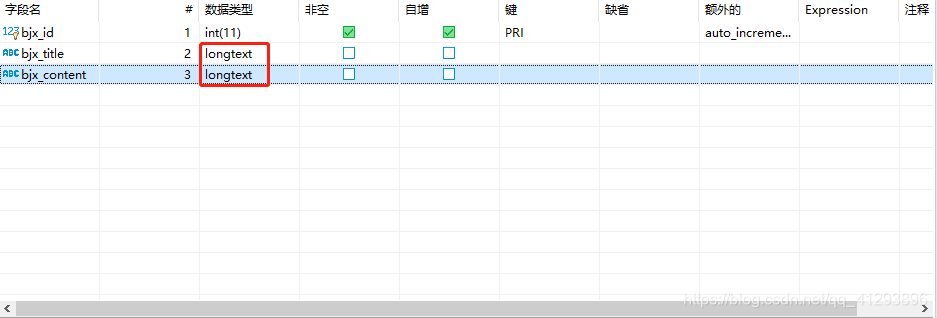
2.数据类型改成longtext
未改前:
修改后:





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









