






异常检测
一、定义
百度百科定义中指出:在数据挖掘中,异常检测(英语:anomaly detection)对不匹配预期模式或数据集中其他项目的项目、事件或观测值的识别。 通常异常项目会转变成银行欺诈、结构缺陷、医疗问题、文本错误、网络入侵、工业生产异常等类型的问题。异常也被称为离群值、新奇、噪声、偏差和例外。
特别是在检测滥用与网络入侵时,有趣性对象往往不是罕见对象,但却是超出预料的突发活动。这种模式不遵循通常统计定义中把异常点看作是罕见对象,于是许多异常检测方法(特别是无监督的方法)将对此类数据失效,除非进行了合适的聚集。相反,聚类分析算法可能可以检测出这些模式形成的微聚类。
1.1 异常的类别[2]
点异常(point anomalies)指的是少数个体实例是异常的,大多数个体实例是正常的,例如正常人与病人的健康指标;
条件异常(conditional anomalies),又称上下文异常,指的是在特定情境下个体实例是异常的,在其他情境下都是正常的,例如在特定时间下的温度突然上升或下降,在特定场景中的快速信用卡交易;
群体异常(group anomalies)指的是在群体集合中的个体实例出现异常的情况,而该个体实例自身可能不是异常,在入侵或欺诈检测等应用中,离群点对应于多个数据点的序列,而不是单个数据点。例如社交网络中虚假账号形成的集合作为群体异常子集,但子集中的个体节点可能与真实账号一样正常。
1.2 异常检测处理方法[6]
分类算法
由于异常检测的特殊性,在将异常检测当做分类算法处理时,由于样本分布不均的情况,很难得到一个行之有效的算法,因此在使用时应该尽量扩充样本的数量,尤其正向样本的数量,同时,获取尽可能多的特征。在测试集或交叉验证集中需要尽可能包含较多的正向样本,来检验算法的优劣性。
算法的评价函数选择f1 Score来代替单纯的精度或召回率。
聚类问题
当作为聚类问题考虑时,例如在使用k-means算法将K设定为2,可能造成算法适应性较差的情况,由于聚类是无监督学习算法,已知的样本类别并不能很好的指导算法的优化,可能造成严重的高偏差,这就要求我们对每一个特征进行分析,同时不能忽视特征间的相关性,因此不推荐采用聚类算法用于异常检测。
概率密度估计
吴恩达老师的ML课程在讲到异常检测时,推荐的是一种基于概率密度估计的算法,主要采用的是高斯分布(正态分布),即用现有的训练集(可以只包含负样本)来模拟高斯分布,在做分类预测时,将特征带入高斯分布公式求取概率,并设定阈值ε来预测分类。常用方法包括高斯分布和多元高斯分布,不同之处在于多元高斯分布考虑了样本特征之间的相关性,能更有效的区分构建分布函数,缺点是计算代价有所提高,同时需要协方差矩阵可逆。
概率密度估计进行异常检测在样本分布严重不均或是样本数量较小的时候也能很好地工作,同时能适应大规模的特征,缺点是ε的选择比较困难,特征数量较少时,性能可能较差。
优化方式同时主要有修正特征分布(将其转化为高斯分布,或者标准化归一),结合其他算法等
1.3 应用------数据安全
多萝西·丹宁教授在1986年提出了入侵检测系统(IDS)的异常检测方法。入侵检测系统的异常检测通常是通过阈值和统计完成的,但也可以用软计算和归纳学习。在1999年提出的统计类型包括检测用户、工作站、网络、远程主机与用户组的配置文件,以及基于频率、均值、方差、协方差和标准差的程序。在入侵检测系统中,与异常检测模式相对应的还有误用检测模式。[1]
1.4 面临的挑战[3]
- 很难定义具有代表性的“正常”区域
- 正常行为与异常行为之间的界限往往并不明确
- 不同的应用领域对异常值的确切定义不同
- 难以获取用于训练/验证的标记数据;具有非常少量的正向类和大量的负向类
- 数据可能含有噪声
- 正常行为并不是一成不变的,会不断发展变化;即未来遇到的异常可能与已经掌握的异常非常不同
二、异常检测方法分类
2.1 基础方法[2]
2.1.1 基于统计学的的方法
学习一个拟合给定数据集的生成模型,然后识别该模型低概率区域中的对象,把它们作为异常点。
即利用统计学方法建立一个模型,然后考虑对象有多大可能符合该模型。
假定输入数据集为x(1),x(2),...,x(m),数据集中的样本服从正态分布,即x(i)∼N(μ,σ2),我们可以根据样本求出参数μ和σ。
2.1.2 线性模型
典型的如PCA方法,Principle Component Analysis是主成分分析,简称PCA。它的应用场景是对数据集进行降维。降维后的数据能够最大程度地保留原始数据的特征(以数据协方差为衡量标准)。其原理是通过构造一个新的特征空间,把原数据映射到这个新的低维空间里。PCA可以提高数据的计算性能,并且缓解"高维灾难"。
在实际应用中,需要建立数据的协方差矩阵,并计算矩阵的特征向量。对应最大特征值(即主要成分)的特征向量可用作重新构建原数据集。原特征空间被减小了(部分数据丢失了,但保留了最重要的信息),得到了由部分特征向量构成的空间。
2.1.3 基于邻近度的方法
这类算法适用于数据点的聚集程度高、离群点较少的情况。同时,因为相似度算法通常需要对每一个数据分别进行相应计算,所以这类算法通常计算量大,不太适用于数据量大、维度高的数据。
基于相似度的检测方法大致可以分为三类:
-
基于距离的度量,如k近邻算法。
k近邻算法的基本思路是对每一个点,计算其与最近k个相邻点的距离,通过距离的大小来判断它是否为离群点。在这里,离群距离大小对k的取值高度敏感。如果k太小,则少量的邻近离群点可能导致较低的离群点得分;如果k太大,则点数少于k的簇中所有的对象可能都成了离群点。为了使模型更加稳定,距离值的计算通常使用k个最近邻的平均距离。
-
基于密度的度量,如LOF(局部离群因子)算法。
局部离群因子(LOF)算法与k近邻类似,不同的是它以相对于其邻居的局部密度偏差而不是距离来进行度量。它将相邻点之间的距离进一步转化为“邻域”,从而得到邻域中点的数量(即密度),认为密度远低于其邻居的样本为异常值。
-
基于集群(簇)的检测,如DBSCAN等聚类方法
聚类算法是将数据点划分为一个个相对密集的“簇”,而那些不能被归为某个簇的点,则被视作离群点。这类算法对簇个数的选择高度敏感,数量选择不当可能造成较多正常值被划为离群点或成小簇的离群点被归为正常。因此对于每一个数据集需要设置特定的参数,才可以保证聚类的效果,在数据集之间的通用性较差。聚类的主要目的通常是为了寻找成簇的数据,而将异常值和噪声一同作为无价值的数据而忽略或丢弃,在专门的异常点检测中使用较少。
2.2 集成方法
集成是提高数据挖掘算法精度的常用方法。集成方法将多个算法或多个基检测器的输出结合起来。其基本思想是一些算法在某些子集上表现很好,一些算法在其他子集上表现很好,然后集成起来使得输出更加鲁棒。集成方法与基于子空间方法有着天然的相似性,子空间与不同的点集相关,而集成方法使用基检测器来探索不同维度的子集,将这些基学习器集合起来。
常用的集成方法有Feature bagging,孤立森林等。
**feature bagging **:
与bagging法类似,只是对象是feature。
孤立森林:
孤立森林假设我们用一个随机超平面来切割数据空间,切一次可以生成两个子空间。然后我们继续用随机超平面来切割每个子空间并循环,直到每个子空间只有一个数据点为止。直观上来讲,那些具有高密度的簇需要被切很多次才会将其分离,而那些低密度的点很快就被单独分配到一个子空间了。孤立森林认为这些很快被孤立的点就是异常点。
2.3 机器学习
在有标签的情况下,可以使用树模型(gbdt,xgboost等)进行分类,缺点是异常检测场景下数据标签是不均衡的,但是利用机器学习算法的好处是可以构造不同特征。
2.3.1 人工神经网络-------------自动编码器网络[4]
自动编码器是一种人工神经网络,通过无监督的方式学习有效的数据编码。自动编码器的目的是学习一组数据的表示(编码),通常用于降维过程。与降维的一层一起,通过学习得到重建层,自动编码器尝试将降维层进行编码,得到尽可能接近于原数据集的结果。
在结构上,最简单的自动编码器形式是前馈非循环神经网络,与许多单层感知器类似,它们构成了包含输入层、输出层和用于连接的一个或多个隐藏层的多层感知器(MLP, multilayer perceptron),但输出层的节点数与输入层相同,目的是对自身的输入进行重建。
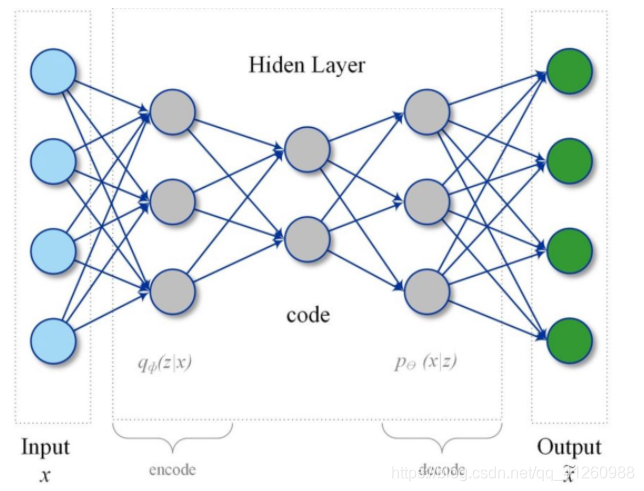
在异常检测和状态监控场景中,基本思想是使用自动编码器网络将传感器的读数进行“压缩”,映射到低维空间来表示,获取不同变量间的联系和相互影响。(与 PCA 模型的基本思想类似,但在这里我们也允许变量间存在非线性的影响)
接下来,用自动编码器网络对表示“正常”运转状态的数据进行训练,首先对其进行压缩然后将输入变量重建。在降维过程中,网络学习不同变量间的联系(例如温度、压力、振动情况等)。当这种情况发生时,我们会看到通过网络重构后的输入变量的异常报错增多了。通过对重构后的报错进行监控,工作人员能够收到所监控设备的“健康”信号,因为当设备状态变差时,报错会增多。在这里使用重建误差的概率分布来判断一个数据点是正常还是异常。
2.3.1 时间序列法:移动平均,同比和环比,时序指标异常检测(STL+GESD)[5]
时间序列异常检测的具体实施流程是:
将这类异常检测作为二分类问题来处理,按照机器学习流程分为四个阶段:预处理,特征提取,模型训练和最后的异常检测。
预处理:
在预处理过程中,我们首先面对的一个挑战是样本极度不平衡,这也是异常检测问题的主要特点。异常样本比例只有2%,远远低于正常样本。
如何避免呢,常用的有两种方式来使得不同类别样本比例相对平衡
下采样:
对训练集里面样本数量较多的类别(多数类)进行欠采样,抛弃一些样本来缓解类不平衡。
过采样:
对训练集里面样本数量较少的类别(少数类)进行过采样,合成新的样本来缓解类不平衡。
这个时候会用到一个非常经典的过采样算法SMOTE
SMOTE全称是Synthetic Minority Oversampling Technique即合成少数类过采样技术,具体思想是:对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中。
通过采用过采样得到的结果相对会较好。
起始端的异常样本点价值是远远大于后续样本的,因此我们需要增强该类样本的权重以提升其价值。结合前面提到的样本均衡策略,样本权重增强也是通过过采样来实现的。
因此,过采样以及起始端异常点样本权重增强是预处理阶段的第二个关键点。
特征提取
异常往往意味着某个维度上的突变,可能是原始值的突变,也可能是均值、方差等统计量的突变,通过前后对比能够很好的捕捉到这类变化。
考虑到这些特点,我们通过三种方式来获取特征:
第一类,通过滑动窗口,提取该窗口类数据的统计特征
第二类,通过序列前后值的对比,得到对比特征
第三类,结合滑动窗口和对比,得到比统计特征
模型训练
第一个是IsolationForest,这是一种常用的异常检测模型,但由于它对局部异常不敏感,在这个问题上表现欠佳
第二个是随机森林,作为一种集成模型,总体表现很稳定,泛化能力也不错,实测结果略低于DNN
第二个是深度学习模型,主要考虑到模型有足够的表达能力,能适应大数据,泛化能力强。
参考资料
- Hodge, V. J.; Austin, J. A Survey of Outlier Detection Methodologies (PDF). Artificial Intelligence Review. 2004, 22 (2): 85–126. doi:10.1007/s10462-004-4304-y.
- AnomalyDetection/一、概述.md · Datawhale/team-learning-data-mining - 码云 - 开源中国 (gitee.com)
- 深入机器学习系列——异常检测(Anomaly Detection) - 菜鸟学院 (cainiaoxueyuan.com)
- 什么是异常检测_异常检测的实用方法-电子发烧友网 (elecfans.com)
- 异常检测—算法篇_Chaseliu1989的博客-优快云博客_异常检测
- 异常检测算法_学习笔记-优快云博客

















 352
352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









