







 本文讲解了在Python中如何正确地将字符串转换为数值进行运算,避免直接使用字符的ASCII值进行比较。通过实例演示了字符串.encode('utf-8')的作用及其实现数值运算的方法。
本文讲解了在Python中如何正确地将字符串转换为数值进行运算,避免直接使用字符的ASCII值进行比较。通过实例演示了字符串.encode('utf-8')的作用及其实现数值运算的方法。
在文本数据解析中,我们常读取文档中的字符串,然后进行数值化处理。如果我们直接读取字符串信息,然后用 i 去索引该字符的值,然后进行数值运算,发现Python 字符的值与整形的数值不能进行比较,代码入戏所示:
str1 = '0123456789'
str2 = str1.encode('utf-8')
if str1[0] == 0x30:
print('str1 get 0 ascii code')
if str2[0] == 0x30:
print('str2 get 0 ascii code')
窗口打印信息为 str2 get 0 ascii code ,如下所示:
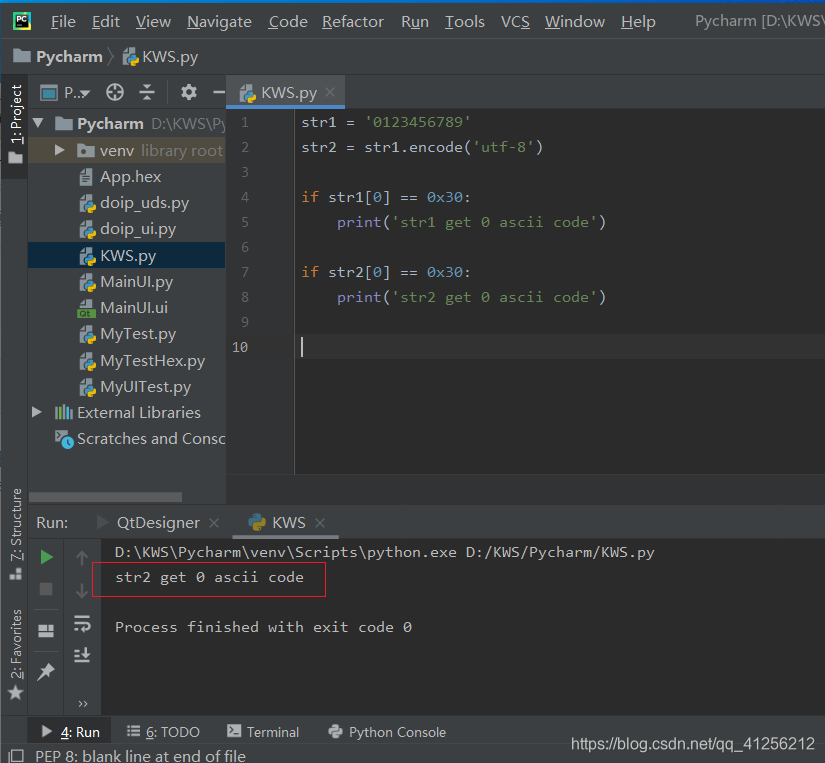
因此我们要将字符串的信息进行数值运算时需要调用 字符串.encode('utf-8'),这样就能进行数值运算了。

















 5232
5232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









