







爬取抽屉新热榜
爬取段子
抽屉网址https://dig.chouti.com/r/scoff/hot/
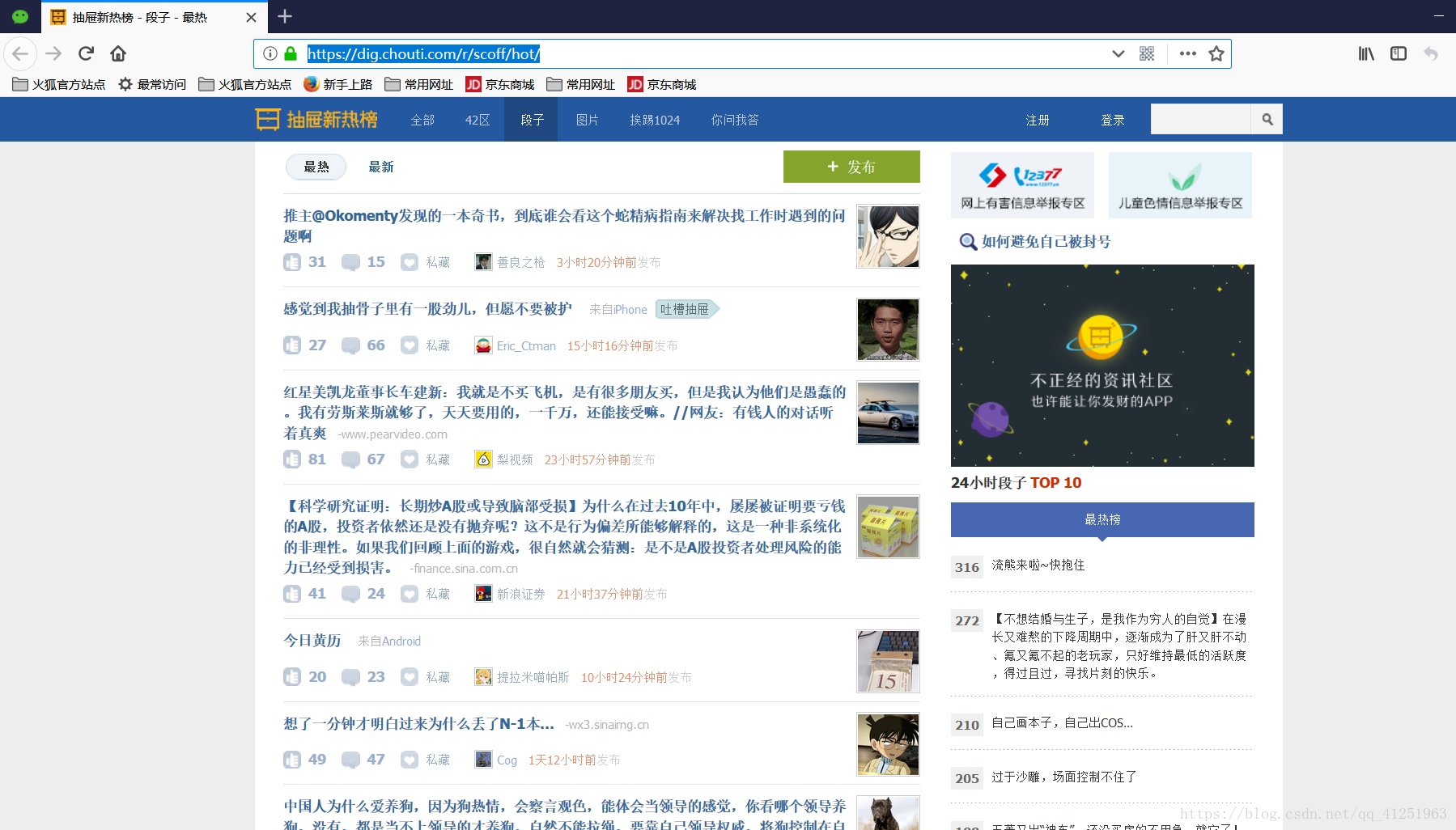
爬虫的常规操作,根据需求进行分析。我们要爬取段子,也就是每条段子信息。先按F12查看一下网页,审查元素。
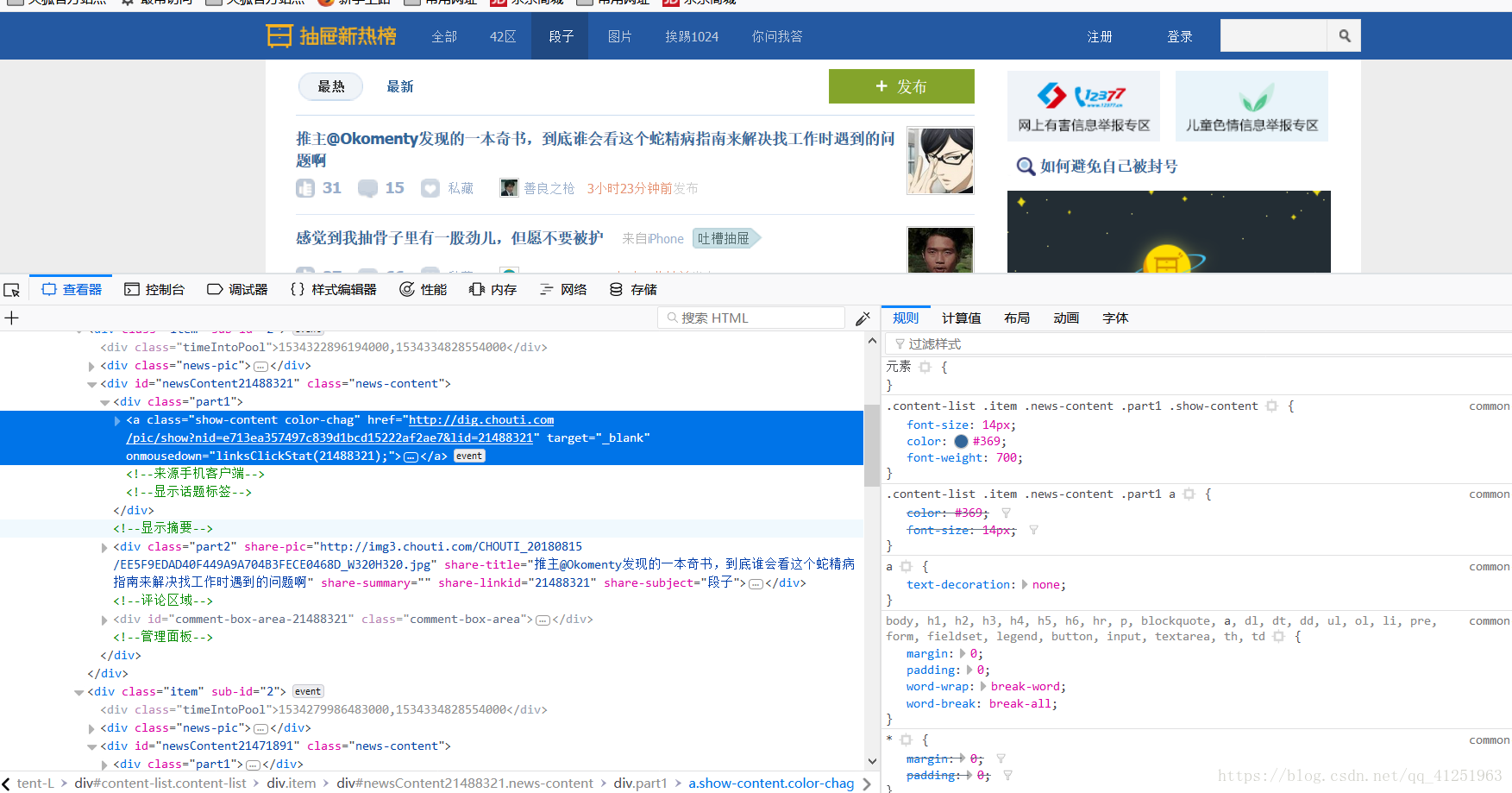
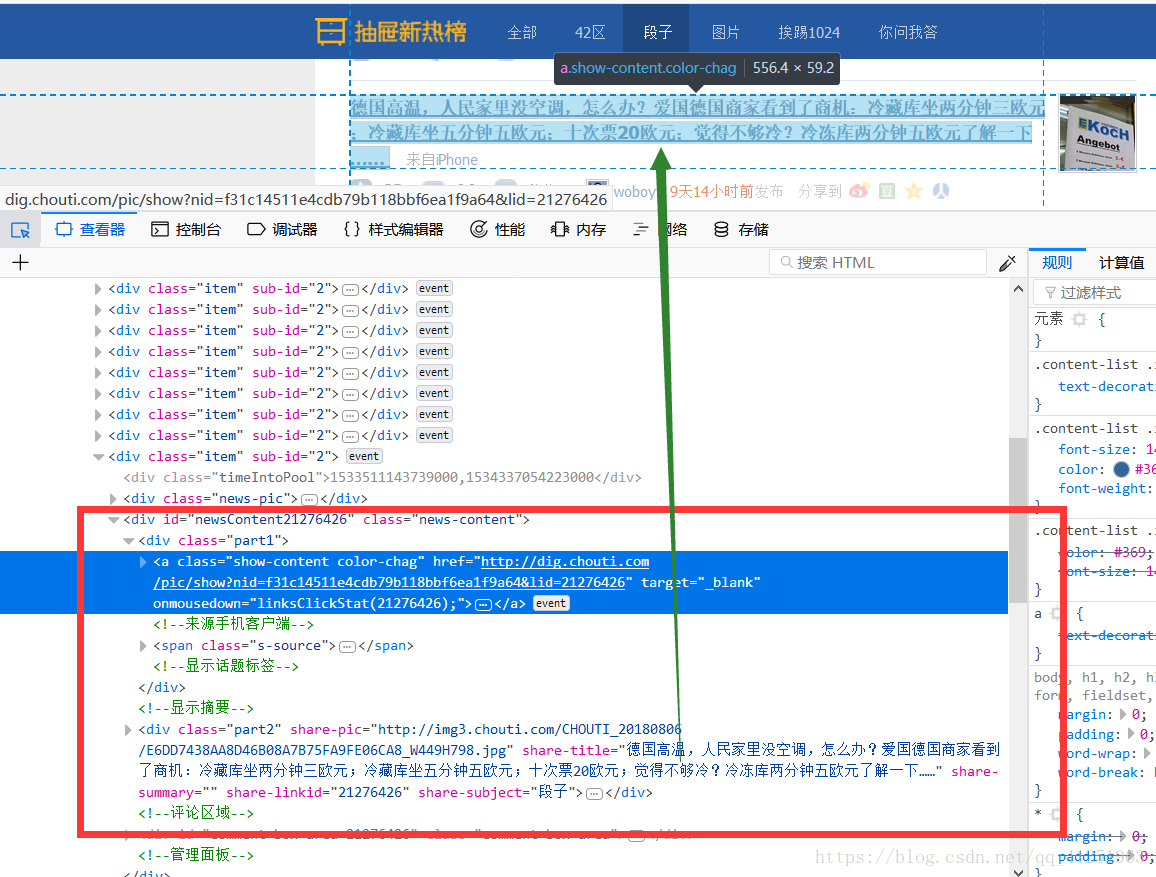
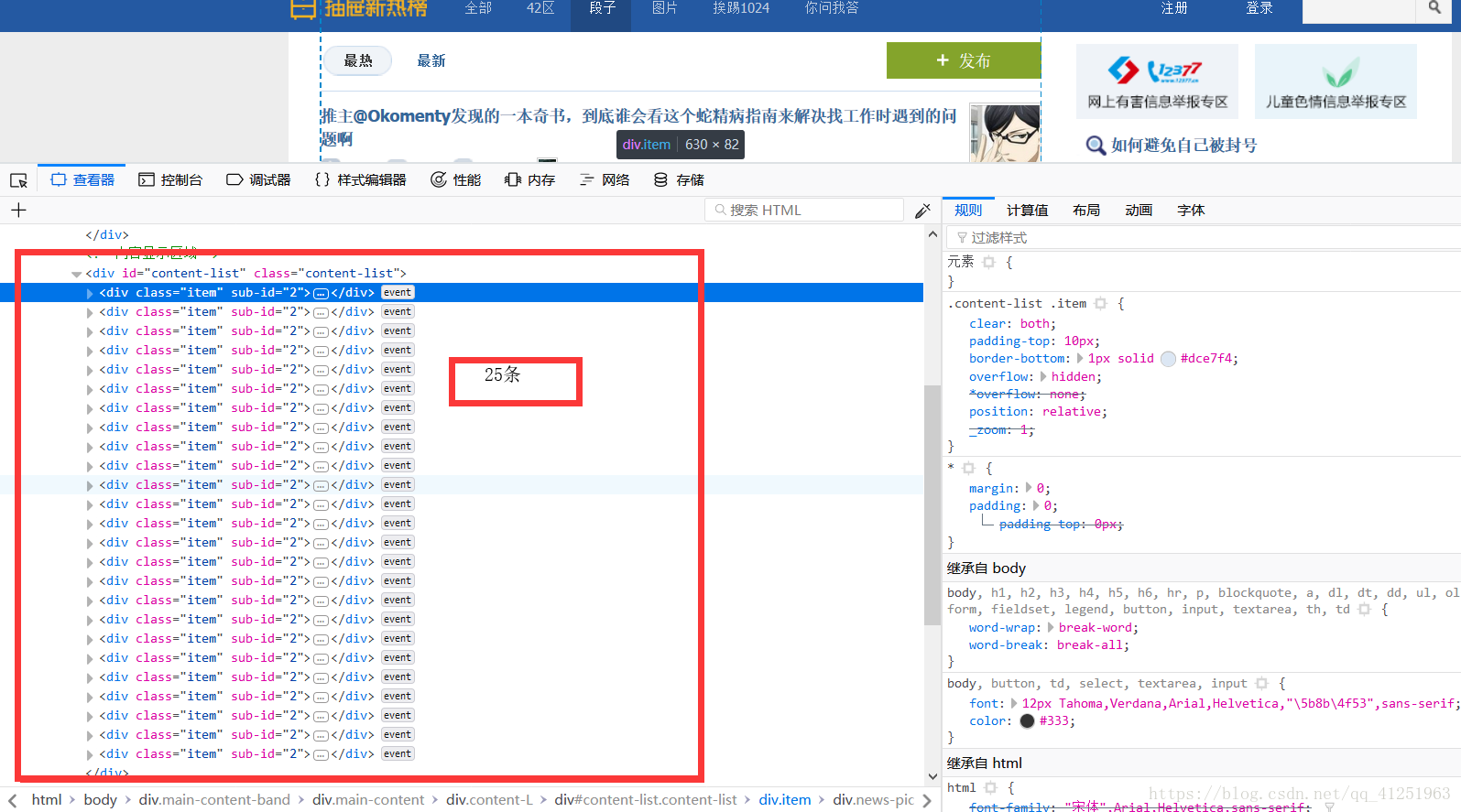
我们刚好找到段子信息,看看其他段子是不是也在这个位置。我们发现了25条一样的 标签。每条标签下都有段子信息,刚好和这页的25条信息相对应。
标签。每条标签下都有段子信息,刚好和这页的25条信息相对应。
提取这些信息,我们同样使用BeautifulSoup。BeautifulSoup的用法我在另一篇文章中有所介绍BeautifulSoup用法
这是一页的信息,如何获取多页呢,看看第二页的网址。
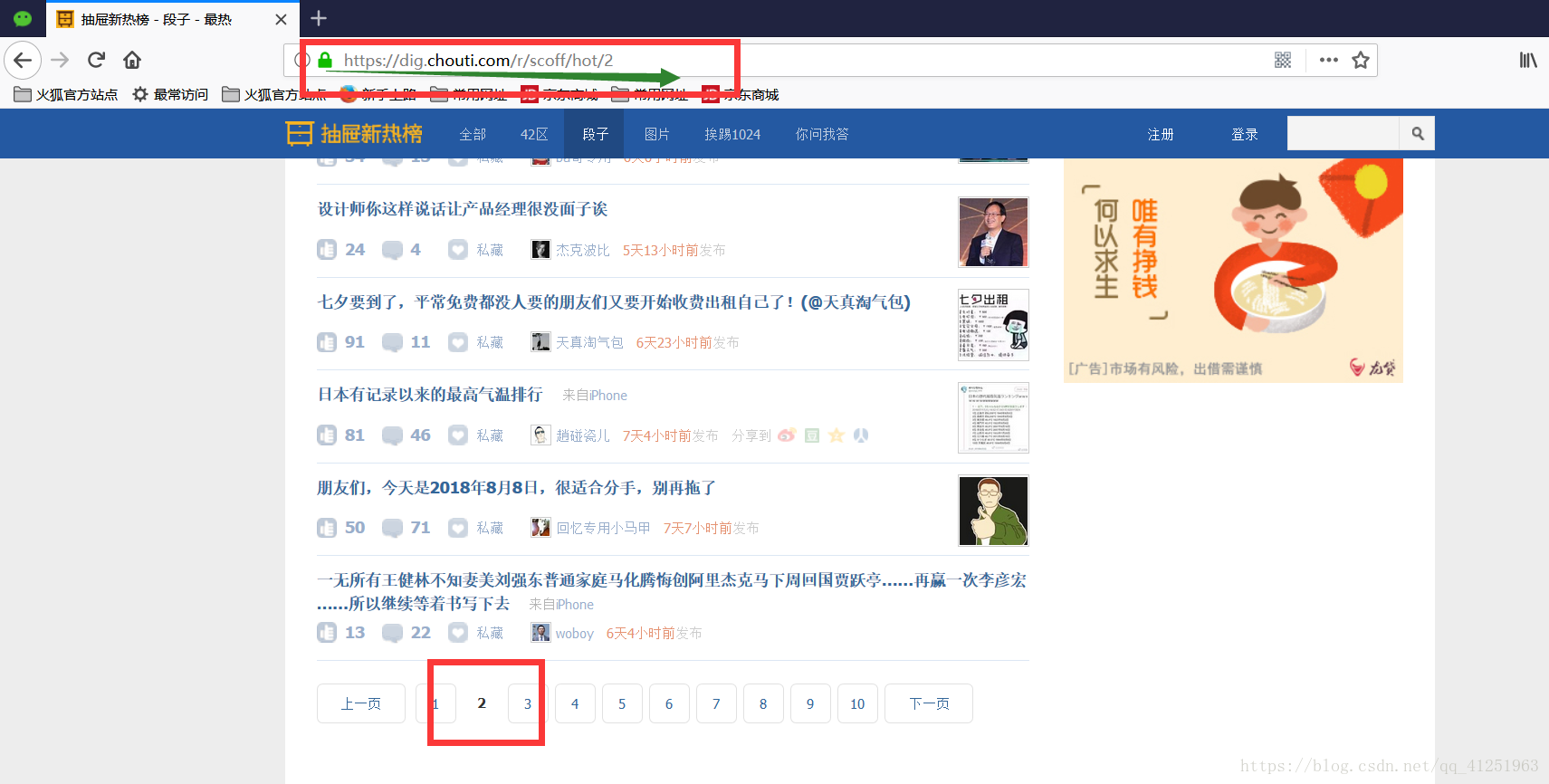
再看看第三页的网址。
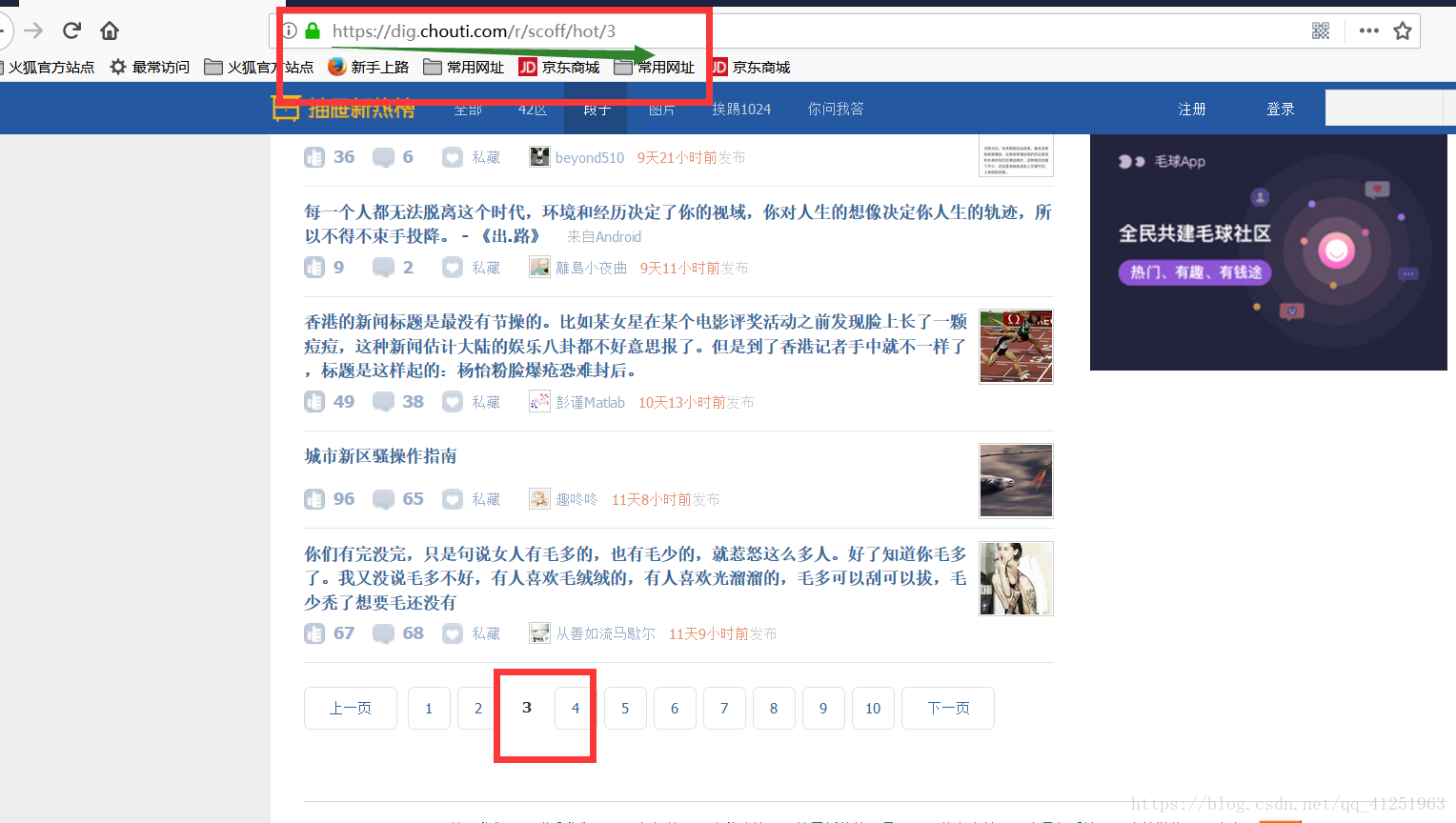
我们发现了规律,用表达式写出来
url = 'http://dig.chouti.com/r/scoff/hot/'+str(i)
这样就可以获取多页的段子信息了。
直接上代码
完整代码
import requests
from bs4 import BeautifulSoup
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:58.0) Gecko/20100101 Firefox/58.0'}
for i in range(10):
url = 'http://dig.chouti.com/r/scoff/hot/'+str(i)
html=requests.get(url,headers=headers)
html.encoding=html.apparent_encoding
soup=BeautifulSoup(html.text,'html.parser')
div=soup.find(id='content-list')
div2=div.find_all('div',class_="item")
for i in div2:
a=i.find('div',class_="part2")
b = a.get('share-title')
print(b)
with open('duanzi.txt','a',encoding='utf-8')as f:
f.write(b)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











