







 本文介绍了如何在Unity中利用Slider组件来控制动画的播放进度。首先,添加Slider组件,接着将带有动画的模型置于场景并为其添加Animation组件。通过调整相关参数并与代码结合,实现用户通过滑动条调整动画播放位置的功能。
本文介绍了如何在Unity中利用Slider组件来控制动画的播放进度。首先,添加Slider组件,接着将带有动画的模型置于场景并为其添加Animation组件。通过调整相关参数并与代码结合,实现用户通过滑动条调整动画播放位置的功能。
1.添加Slider组件。
2.将带有动画的模型放入场景,给模型添加Animation组件。
3.具体参数调整参考下图。
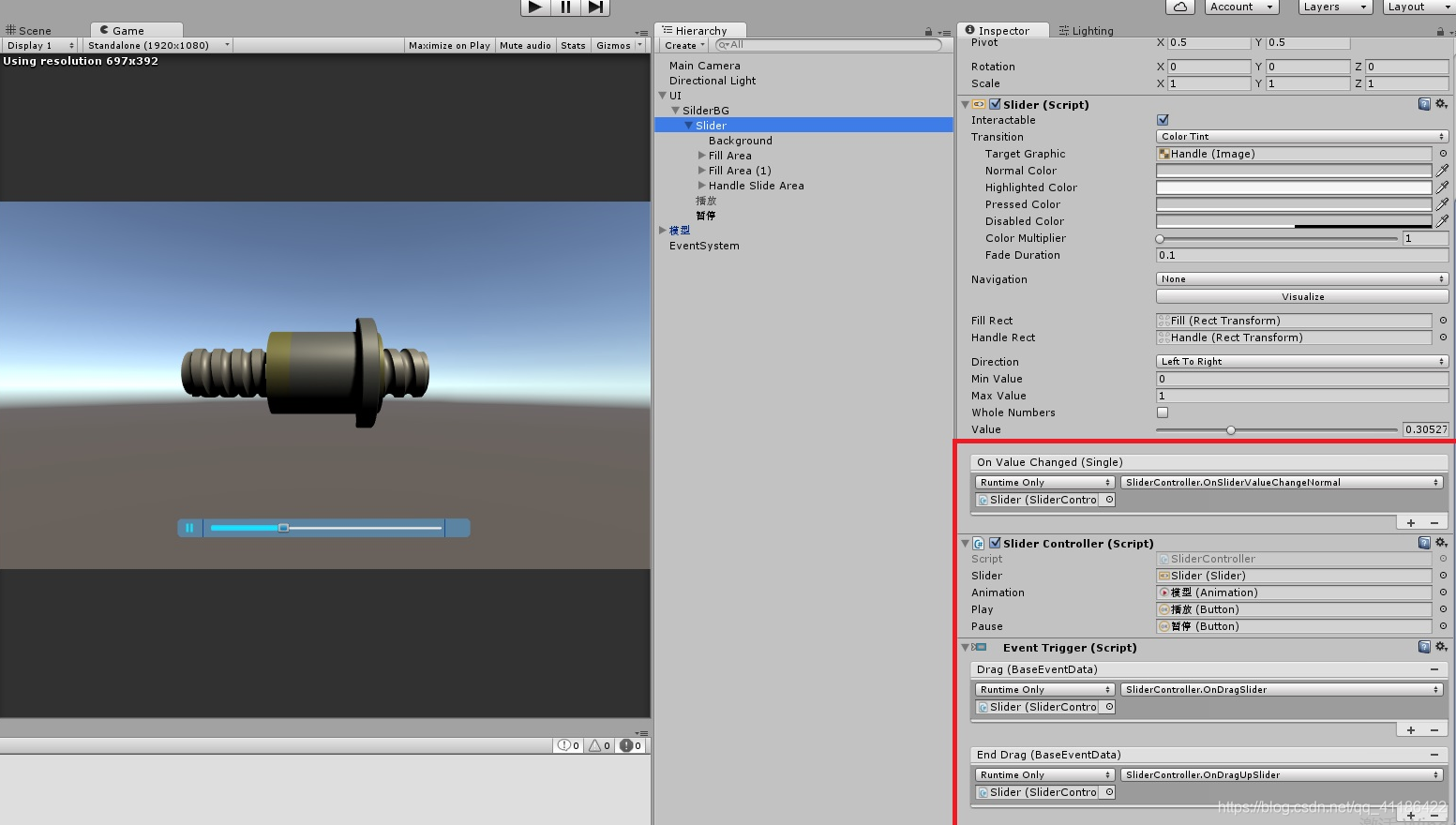 4.代码。
4.代码。
using UnityEngine;
using System.Collections;
using UnityEngine.UI;
public class SliderController : MonoBehaviour {
public Slider slider;
public Animation animation;
public Button play, pause;
// Use this for initialization
void Start ()
{
play.onClick.AddListener(PlayOnClickBtn);
pause.onClick.AddListener(PauseOnClickBtn);
}
// Update is called once per frame
void Update ()
{
slider.value = animation["Take 001"].normalizedTime;
//如果模型动画停止播放,则重新播放动画
if (animation.isPlaying == false)
{
animation.Play();
}
}
/// <summary>
/// 暂停按钮
/// </summary>
private void PauseOnClickBtn()
{
play.gameObject.SetActive(true);
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









