







mysql索引及其实现原理
1、索引的概念
索引是一种可以加快检索的数据库结构,它包含从表或视图的一列或多列生成的键,以及映射到指定数据库位置的指针,通过设计创建设计良好的索引,可以提高数据库查询和应用程序的性能。
2、mysql索引结构类型
Mysql主要有以下几种索引类型:HASH、BTREE、RTREE、FULLTEXT。
HASH:只能用于等值查询,不能用于范围查询。键值不唯一的时候,效率不高。
BTREE,RTREE:可用于等值查询、范围查询,BTREE为mysql的默认索引类型。
3、索引种类
普通索引:单值索引
唯一索引:索引值唯一,值可为空
主键索引:索引值唯一,值不可为空
组合索引:一个索引包含多个列,需要遵从最左前缀法则。
全文索引:一种特殊类型的索引,它查找的是文本中的关键词,而不是直接比较索引中的值。
说明:
覆盖索引:指的是一种查询方式,所查询的字段,在索引的叶子节点就能拿到数据,不用回表,这称为索引覆盖。
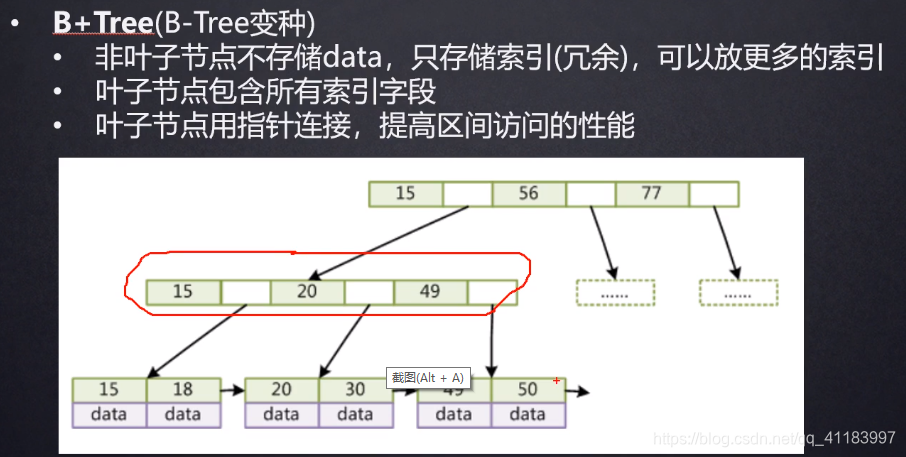
4、B+树结构
B+Tree的根节点分配了大概16kb的空间,大概可以存储1170个索引元素,数据全部存放在叶子节点,一个高度为3的B+Tree大概可以存储2000多万的索引元素。数据量超过后会导致树的高度增高,同时单条数据的大小也会影响树的高度。解释:假设我们有一个表,每行数据为1k,主键的id是bigint。bigint长度为8个字节,指针的大小为6字节。那么8+6=14,一个索引页161024=16384,根节点16384/14=1170,可存储的数据量11701170*16=21902400条。
主键索引:叶子节点存储完整的数据记录
非主键索引:叶子节点存储索引列值+主键值
5、索引实现原理
聚簇索引:聚簇索引指的是一种数据的存储方式,表的数据存储在索引文件是叶子节点中。
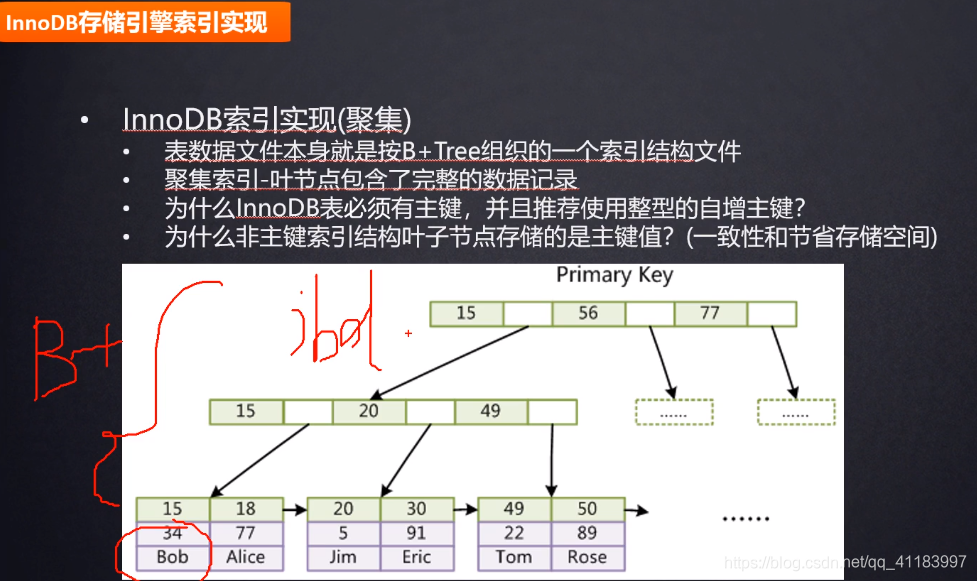
推荐使用整型的自增主键:整型占用的空间更小,方便索引的维护,插入效率很高(末尾插入)
非聚簇索引:非聚簇索引表的数据和索引文件是分开的。
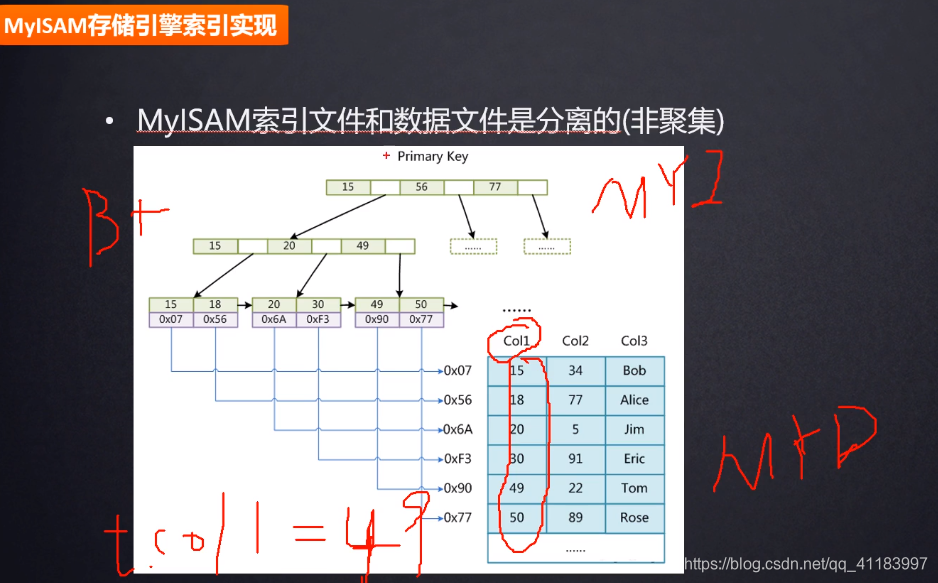
6、关于自增主键和uuid
(1)单实例或者单节点组
经过500W、1000W的单机表测试,自增ID相对UUID来说,自增ID主键性能高于UUID,磁盘存储费用比UUID节省一半的钱。所以在单实例上或者单节点组上,使用自增ID作为首选主键。
(2)分布式架构场景
20个节点组下的小型规模的分布式场景,为了快速实现部署,可以采用多花存储费用、牺牲部分性能而使用UUID主键快速部署;
20到200个节点组的中等规模的分布式场景,可以采用自增ID+步长的较快速方案。
200以上节点组的大数据下的分布式场景,可以借鉴类似twitter雪花算法构造的全局自增ID作为主键。

















 1314
1314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









