import numpy as np
from math import sqrt
from collections import Counter
def kNN_classify(k, X_train, y_train, x):
assert 1 <= k <= X_train.shape[0], "k must be valid"
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must equal to the size of y_train"
assert X_train.shape[1] == x.shape[0], \
"the feature number of x must be equal to X_train"
distances = [sqrt(np.sum((x_train - x)**2)) for x_train in X_train]
nearest = np.argsort(distances)
topK_y = [y_train[i] for i in nearest[:k]]
votes = Counter(topK_y)
return votes.most_common(1)[0][0]








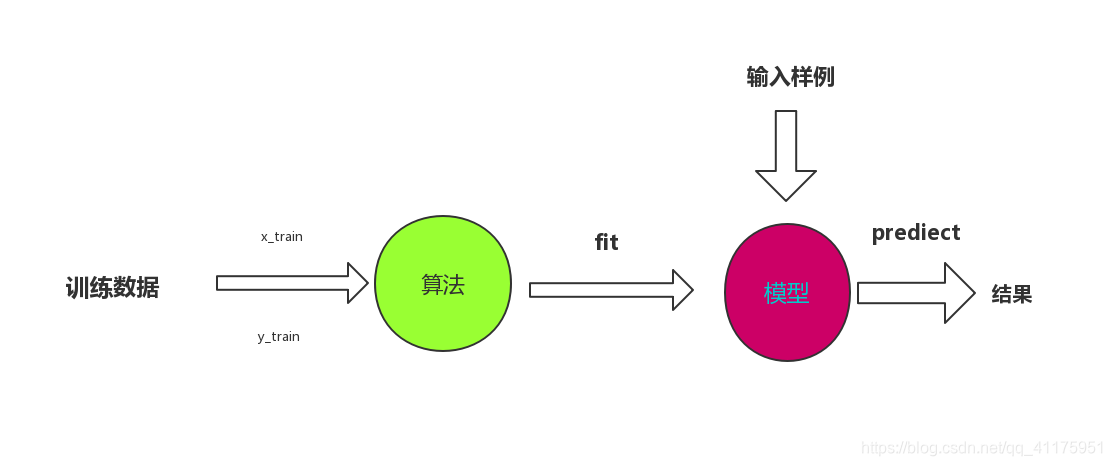
 博客介绍了算法设计流程图,主要围绕KNN算法展开。包括建立KNN模型、初步检测模型,还提及使用scikit - learn中的kNN,展示了KNN算法从构建到应用的基本流程。
博客介绍了算法设计流程图,主要围绕KNN算法展开。包括建立KNN模型、初步检测模型,还提及使用scikit - learn中的kNN,展示了KNN算法从构建到应用的基本流程。

















 1263
1263

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









