






0 前言
关于1:100万公众版基础地理信息数据(2021)全网的介绍、下载和处理教程有很多,有些是用ArcMap建模处理,有些是用bash和python分步骤处理,本文只需要一个python代码+arcgis pro的融合dissolve即可把所有的GDB文件处理成合并好的shp。
Python代码
# Weiguo Xie YITC 20250101 gisxieweiguo@qq.com
import arcpy
import os
# 输入参数
gdb_folder = r"D:\BaiduNetdiskDownload\2021公众版国家基础信息系统1:100万行政区划数据\GDB" # GDB文件夹路径
output_folder = r"D:\Output" # 输出SHP文件夹路径
feature_list = ["CPTP", "CPTL", "HYDA", "HYDL", "HYDP", "HFCA", "HFCL", "HFCP",
"RESA", "RESL", "RESP", "RFCA", "RFCL", "RFCP", "LRRL", "LRDL",
"LFCL", "LFCP", "PIPL", "PIPP", "BOUA", "BOUL", "BOUP", "BRGA",
"BRGL", "BRGP", "TERA", "TERL", "TERP", "VEGA", "VEGL", "VEGP",
"AGNP", "AANP"] # 需要合并的要素名称列表,有些GDB里面没有所有的类别,所以会显示某要素不存在某GDB中,这个是正常情况
# 创建输出文件夹
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 创建一个字典,用于存储每个要素的临时合并结果
merged_features = {feature: [] for feature in feature_list}
# 遍历文件夹中的所有GDB
for gdb in os.listdir(gdb_folder):
gdb_path = os.path.join(gdb_folder, gdb)
if os.path.isdir(gdb_path) and gdb_path.endswith(".gdb"):
print(f"正在处理GDB: {gdb_path}")
arcpy.env.workspace = gdb_path
# 遍历需要合并的要素
for feature in feature_list:
if arcpy.Exists(feature):
print(f" 找到要素: {feature}")
merged_features[feature].append(os.path.join(gdb_path, feature))
else:
print(f" 要素 {feature} 不存在于 {gdb_path}")
# 合并并导出为SHP
for feature, paths in merged_features.items():
if paths:
print(f"正在合并要素: {feature}")
output_shp = os.path.join(output_folder, f"{feature}.shp")
# 合并要素
arcpy.management.Merge(paths, output_shp)
print(f" 已导出合并结果: {output_shp}")
else:
print(f"要素 {feature} 在所有GDB中均不存在,跳过合并。")
print("所有要素处理完成!")
将代码放在Arcgis Pro的python模块中运行即可,整个数据的处理过程比较漫长,我的电脑内存24G,用了一个小时左右处理完。
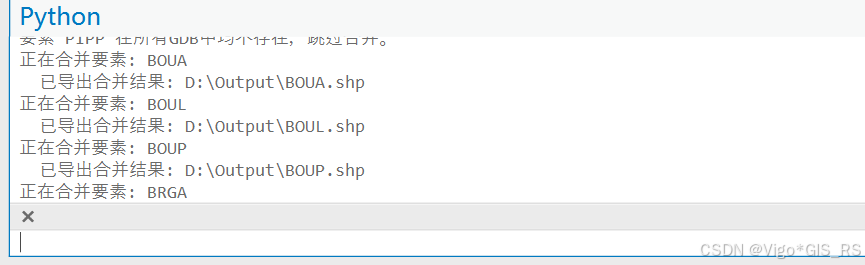
合并完成后,有些线和面还需要根据相同的属性进行融合,在Arcgis Pro中打开融合工具,输入shp和融合字段
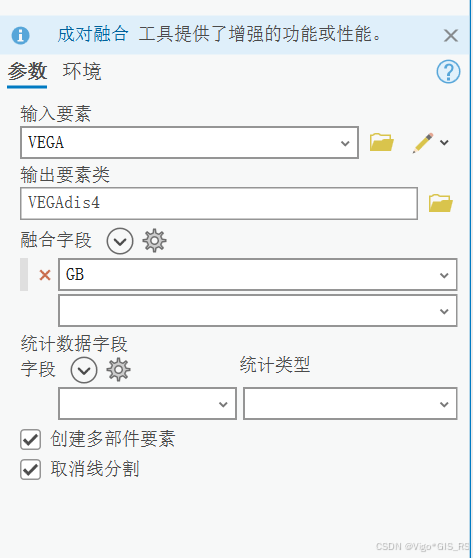
-
融合前:

-
融合后:
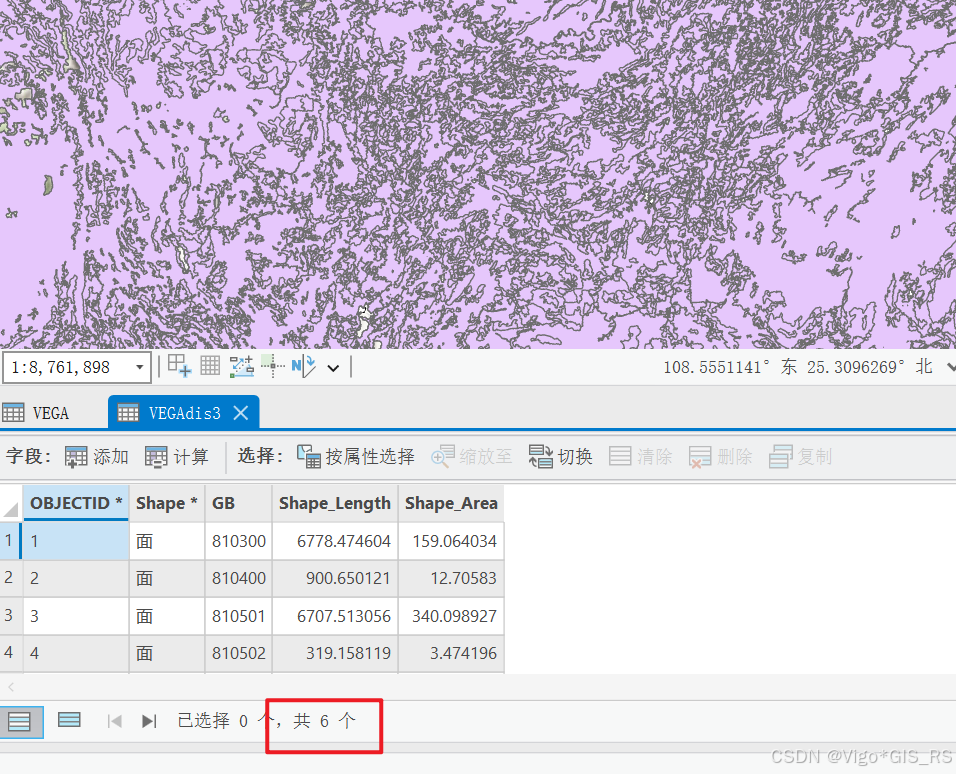
-
附
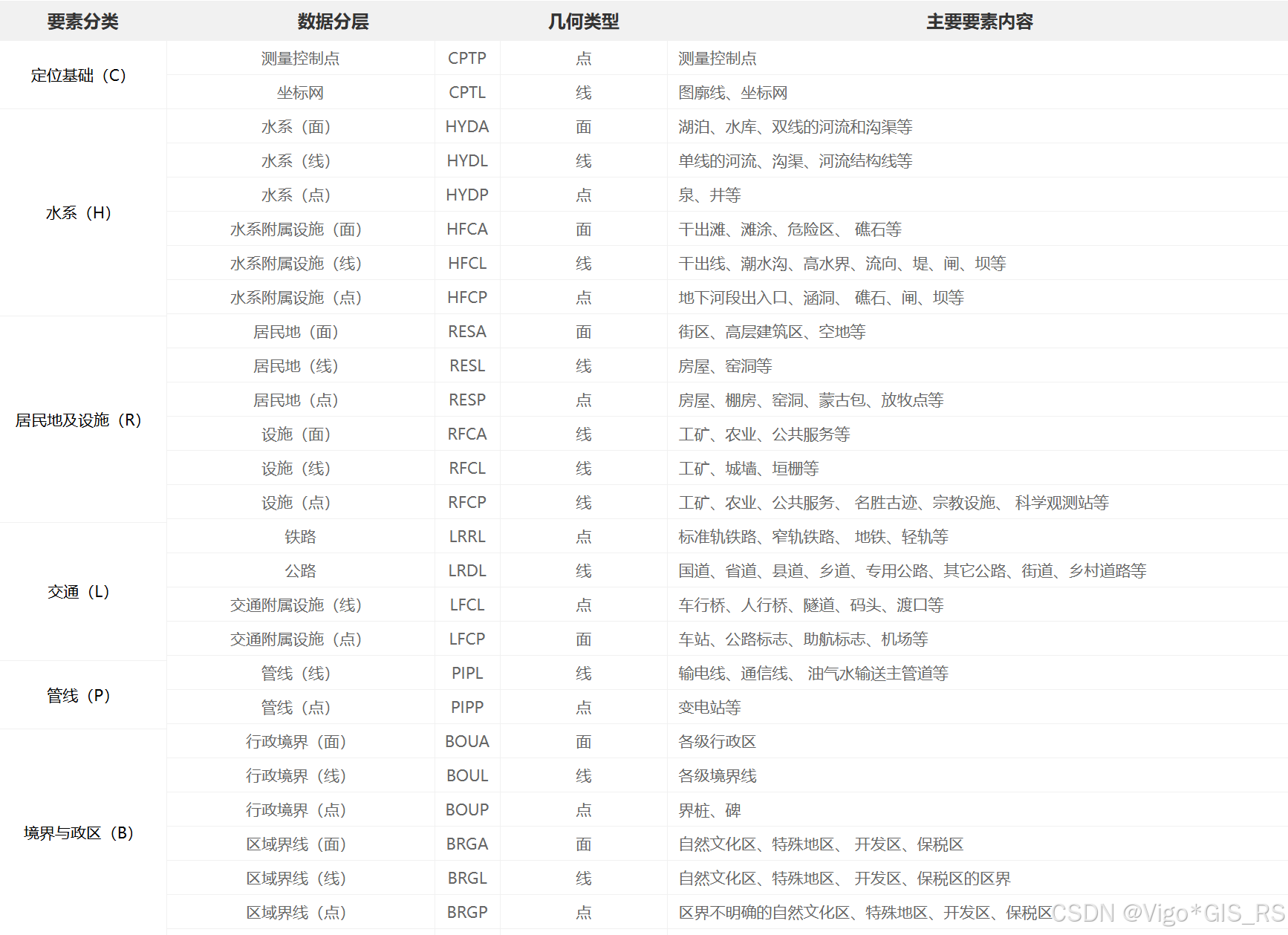
成果数据组织
全国1:100万公众版地形数据(2021)内容包括水系、居民地及设施、交通、管线、境界与政区、地貌与土质、植被、地名及注记9个数据集。
数据分层的命名采用四个字符,第一个字符代表数据分类,第二三个字符是数据内容的缩写,第四个字符代表几何类型。
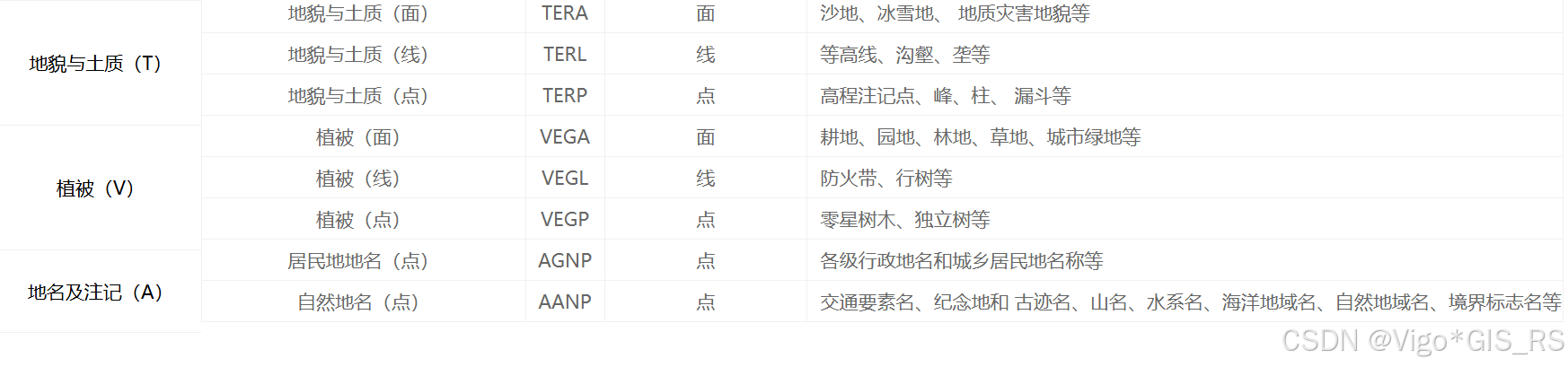



















 1058
1058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











