







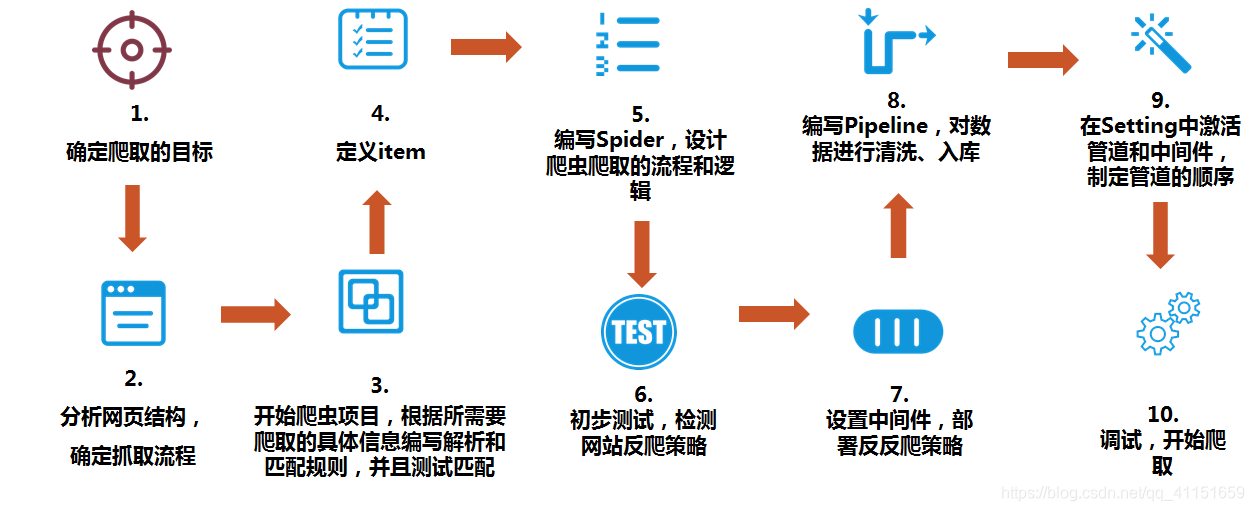
爬虫整体流程
实战
-
58同城抓取流程
-
进入成都小区页面(https://cd.58.com/xiaoqu/),确定抓取目标
-
观察页面,获取各行政区的链接
-
分行政区抓取各小区的URL
-
进入各小区详情页面,抓取名字、价格、地址、年份等信息
-
抓取小区二手房页面第一页的价格,在管道中求该小区房价的平均价格
-
抓取小区出租房页面第一页的URL,进入详情页抓取名称、价格、房型等信息
需要抓取的有:
- 各行政区下的小区列表的小区URL
- 小区详情页中该小区的名字、价格、地址、年份等信息
- 各小区二手房页面的二手房每平米价格,并在管道中计算出小区真实平均房价
- 各小区租房页面列表中每个租房房源的URL
- 每个租房房源的详情页中,该房源的名称、价格、房型等信息
-
-
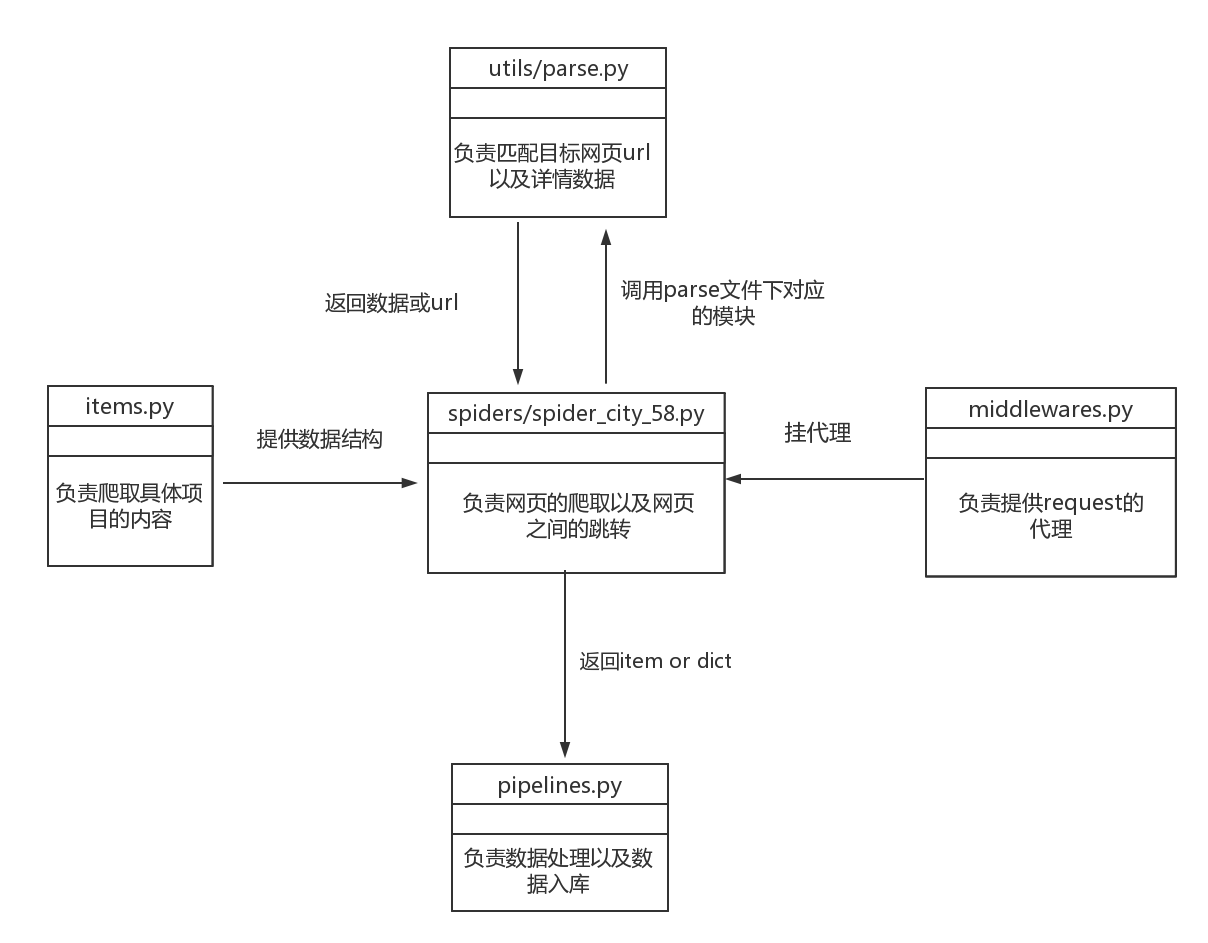
58同城抓取代码模块示意图:
-
代码实现
- 创建scrapy文件,命名为city_58,并创建爬虫文件spider_city_58
>>> scrapy startproject city_58 >>> cd city_58 >>> scrapy genspider spider_city_58 58.com- 编写items.py文件,这个文件主要负责定义具体项目的内容
import scrapy class City58Item(scrapy.Item): # define the fields for your item here like: name = scrapy.Field() price = scrapy.Field() last_updated = scrapy.Field() class City58ItemXiaoQu(scrapy.Item): id = scrapy.Field() name = scrapy.Field() reference_price = scrapy.Field() address = scrapy.Field() times = scrapy.Field() class City58ItemXiaoChuZuQuInfo(scrapy.Item): id = scrapy.Field() name = scrapy.Field() zu_price = scrapy.Field() type = scrapy.Field() mianji = scrapy.Field() chuzu_price_pre = scrapy.Field() url = scrapy.Field() price_pre = scrapy.Field()- 在city_58文件夹下创建utils文件夹,文件夹下创建一个parse.py文件,parse.py共有5个函数,分别负责匹配列表页所有的小区url,小区的详情页信息,二手房的详情页信息,出租页面详情页的url,出租页面详情页
# code:utf8 from pyquery import PyQuery def parse(response): """ 抓取小区列表页面: http://cd.58.com/xiaoqu/11487/ 返回列表页所有的小区url :param:response :return """ jpy = PyQuery(response.text) tr_list = jpy('#infolist > div.listwrap > table > tbody > tr').items() result = set() #result为set集合(不允许重复元素) for tr in tr_list: url = tr(' td.info > ul > li.tli1 > a').attr('href') #爬取各个小区的url result.add(url) return result def xiaoqu_parse(response): """ 小区详情页匹配代码样例url:http://cd.58.com/xiaoqu/shenxianshudayuan/ 返回这个小区的详细信息的dict字典,主要信息包括小区名称,小区参考房价,小区地址,小区建筑年代 :param:response :return: """ result = dict() jpy = PyQuery(response.text) result['name'] = jpy('body > div.bodyItem.bheader > div > h1 > span').text() result['reference_price'] = jpy('body > div.bodyItem.bheader > div > dl > dd:nth-child(1) > span.moneyColor').text() result['address'] = jpy('body > div.bodyItem.bheader > div > dl > dd:nth-child(3) > span.ddinfo')\ .text().replace('查看地图', '') #得到地址详情,去除“查看地图”,如 “ 紫荆西路6号 查看地图”,将“查看地图”替换为“” result['times'] = jpy('body > div.bodyItem.bheader > div > dl > dd:nth-child(5)').text().split() result['times'] = result['times'][2] #取出建筑年代 return result def get_ershou_price_list(response): """ 页面链接样例:http://cd.58.com/xiaoqu/shenxianshudayuan/ershoufang/ 匹配二手房列表页面的所有房价信息 返回一个价格的列表list :param:response :return: """ jpy = PyQuery(response.text) price_tag = jpy('td.tc > span:nth-child(3)').text().split() price_tag = [i[:-3] for i in price_tag] #遍历price_tag截取到倒数第三个元素 return price_tag def chuzu_list_pag_get_detail_url(response): """ 页面链接样例:http://cd.58.com/xiaoqu/shenxianshudayuan/chuzu/ 获取出租列表页所有详情页url 返回一个url的列表list :param:response :return: """ jpy = PyQuery(response.text) a_list = jpy('tr > td.t > a.t').items() url_list = [a.attr('href') for a in a_list] #遍历a_list return url_list def get_chuzu_house_info(response): """ 获取出租详情页的相关信息 返回一个dict包含:出租页标题,出租价格,房屋面积,房屋类型(几室几厅) :param:response :return: """ jpy = PyQuery(response.text) result = dict() result['name'] = jpy('body > div.main-wrap > div.house-title > h1').text() result['zu_price'] = jpy('body > div.main-wrap > div.house-basic-info > div.house-basic-right.fr > ' 'div.house-basic-desc > div.house-desc-item.fl.c_333 > div > span.c_ff552e > b').text() result['type'] = jpy('body > div.main-wrap > div.house-basic-info > div.house-basic-right.fr > div.house-basic-desc' ' > div.house-desc-item.fl.c_333 > ul > li:nth-child(2) > span:nth-child(2)').text() result['type'], result['mianji'], *_ = result['type'].split() return result if __name__ == '__main__': import requests r = requests.get('http://cd.58.com/zufang/31995551807162x.shtml') get_chuzu_house_info(r)- 编写spider_city_58.py,这个文件主要负责网页的爬取以及网页之间的跳转
# -*- coding: utf-8 -*- import scrapy #导入scrapy包 from scrapy.http import Request #导入Request包 from ..utils.parse import parse, \ #从utils文件夹中导入parse文件中的这些类 xiaoqu_parse, get_ershou_price_list, \ chuzu_list_pag_get_detail_url,\ get_chuzu_house_info from ..items import City58ItemXiaoQu, City58ItemXiaoChuZuQuInfo #从items文件导入这些类 from traceback import format_exc class SpiderCity58Spider(scrapy.Spider): name = 'spider_city_58' allowed_domains = ['58.com'] host = 'cd.58.com' xianqu_url_format = 'http://{}/xiaoqu/{}/' # xianqu_code = list() xianqu_code = list(range(103, 118)) xianqu_code.append(21611) def start_requests(self): #重写start_requests函数 start_urls = ['http://{}/xiaoqu/{}/'.format(self.host, code) for code in self.xianqu_code] for url in start_urls: yield Request(url) #遍历所有区域 def parse(self, response): """ 第一步抓取所有的小区 http://cd.58.com/xiaoqu/21611/ :param response: :return: """ url_list = parse(response) #调用utils文件夹中parse文件中的parse方法,得到所有小区的url for url in url_list: yield Request(url, callback=self.xiaoqu_detail_pag, #回调xiaoqu_detail_pag方法 errback=self.error_back, priority=4 ) def xiaoqu_detail_pag(self, response): """ 第二步抓取小区详情页信息 http://cd.58.com/xiaoqu/shenxianshudayuan/ :param response: :return: """ _ = self data = xiaoqu_parse(response) item = City58ItemXiaoQu() item.update(data) item['id'] = response.url.split('/')[4] yield item # 二手房 url = 'http://{}/xiaoqu/{}/ershoufang/'.format(self.host, item['id']) yield Request(url, callback=self.ershoufang_list_pag, #回调ershoufang_list_pag方法 errback=self.error_back, meta={'id': item['id']}, priority=3) # 出租房 url_ = 'http://{}/xiaoqu/{}/chuzu/'.format(self.host, item['id']) yield Request(url_, callback=self.chuzu_list_pag, #回调chuzu_list_pag方法 errback=self.error_back, meta={'id': item['id']}, priority=2) def ershoufang_list_pag(self, response): """ 第三步抓取二手房详情页信息 http://cd.58.com/xiaoqu/shenxianshudayuan/ershoufang/ :param response: :return: """ _ = self price_list = get_ershou_price_list(response) yield {'id': response.meta['id'], 'price_list': price_list} def chuzu_list_pag(self, response): """ 第四步抓取出租房详情页url http://cd.58.com/xiaoqu/shenxianshudayuan/chuzu/ :param response: :return: """ _ = self url_list = chuzu_list_pag_get_detail_url(response) for url in url_list: yield response.request.replace(url=url, callback=self.chuzu_detail_pag, priority=1) #回调chuzu_detail_pag方法 # yield Request(url, callback=) def chuzu_detail_pag(self, response): """ 第五步抓取出租房详情页信息 :param response: :return: """ _ = self data = get_chuzu_house_info(response) item = City58ItemXiaoChuZuQuInfo() item.update(data) item['id'] = response.meta['id'] item['url'] = response.url yield item def error_back(self, e): _ = e self.logger.error(format_exc()) #打出报错信息- 编写middleware.py 文件,这个文件主要负责挂代理,防止封IP
可以在网上寻找免费的代理IP,也可以购买高质量的代理IP
from scrapy import signals #from .utils.proxy_swift import proxy_pool class ProxyMiddleware(object): def process_request(self, request, spider): #传入代理服务器,下面语句需要替换为自己的代理方式 request.meta['proxy'] = 'http://{}'.format(proxy_pool.pop()) print() def process_response(self, request, response, spider): return response def process_exception(self, request, exception, spider): pass- 编写pipeline.py,这个文件主要负责数据处理以及数据入库
from scrapy.exceptions import DropItem from pymongo import MongoClient from scrapy.conf import settings from pymongo.errors import DuplicateKeyError from traceback import format_exc from .items import City58ItemXiaoQu, City58ItemXiaoChuZuQuInfo class City58Pipeline(object): def __init__(self, mongo_uri, mongo_db): self.mongo_uri = mongo_uri self.mongo_db = mongo_db self.client = None self.db = None @classmethod def from_crawler(cls, crawler): return cls( mongo_uri=crawler.settings.get('MONGODB_URI'), #提取出了mongodb配置 mongo_db=settings.get('MONGODB_DATABASE', 'items') ) def open_spider(self, spider): _ = spider self.client = MongoClient(self.mongo_uri) #连接数据库 self.db = self.client[self.mongo_db] self.db['city58_info'].ensure_index('id', unique=True) #在表city58_info中建立索引,并保证索引的唯一性 self.db['city58_chuzu_info'].ensure_index('url', unique=True) #在表city58_chuzu_info中建立索引,并保证索引的唯一性 def close_spider(self, spider): _ = spider self.client.close() #关闭数据库 def process_item(self, item, spider): try: if isinstance(item, City58ItemXiaoQu): #判断是否是小区的item self.db['city58_info'].update({'id': item['id']}, {'$set': item}, upsert=True) #通过id判断,有就更新,没有就插入 elif isinstance(item, City58ItemXiaoChuZuQuInfo): #判断是否是小区出租信息的item try: fangjia = HandleFangjiaPipline.price_per_square_meter_dict[item['id']] #把HandleFangjiaPipline管道的字典price_per_square_meter_dict中每平米平均价格赋值给fangjia # del HandleFangjiaPipline.price_per_square_meter_dict[item['id']] item['price_pre'] = fangjia #赋值给item self.db['city58_chuzu_info'].update({'url': item['url']}, {'$set': item}, upsert=True) #通过url判断,有就更新,没有就插入 except Exception as e: print(e) #打印错误 except DuplicateKeyError: spider.logger.debug(' duplicate key error collection') #唯一键冲突报错 except Exception as e: _ = e spider.logger.error(format_exc()) return item class HandleZuFangPipline(object): def process_item(self, item, spider): _ = spider, self # self.db[self.collection_name].insert_one(dict(item)) if isinstance(item, City58ItemXiaoChuZuQuInfo) and 'mianji' in item: #判断进来的item是否是City58ItemXiaoChuZuQuInfo,是否含有面积参数 item['chuzu_price_pre'] = int(item['zu_price']) / int(item['mianji']) #租金除以面积得到平均价格 return item #继续传递item class HandleFangjiaPipline(object): price_per_square_meter_dict = dict() #声明一个dict() def process_item(self, item, spider): _ = spider if isinstance(item, dict) and 'price_list' in item: #判断传进来的item是否是个字典,并且是否含有price_list item['price_list'] = [int(i) for i in item['price_list']] #遍历price_list if item['price_list']: self.price_per_square_meter_dict[item['id']] = sum(item['price_list']) / len(item['price_list']) #得到每个小区的平均价格 else: self.price_per_square_meter_dict[item['id']] = 0 raise DropItem() return item #继续传递item- 编写settings.py,这个文件主要负责激活管道和中间件,制定管道的顺序
# -*- coding: utf-8 -*- # Scrapy settings for city_58 project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # http://doc.scrapy.org/en/latest/topics/settings.html # http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html # http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html BOT_NAME = 'city_58' SPIDER_MODULES = ['city_58.spiders'] NEWSPIDER_MODULE = 'city_58.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = 'city_58 (+http://www.yourdomain.com)' # Obey robots.txt rules ROBOTSTXT_OBEY = True # Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs DOWNLOAD_DELAY = 0.3 #下载速度 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) #COOKIES_ENABLED = False # Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False # Override the default request headers: #DEFAULT_REQUEST_HEADERS = { # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', # 'Accept-Language': 'en', #} # Enable or disable spider middlewares # See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html #SPIDER_MIDDLEWARES = { # 'city_58.middlewares.City58SpiderMiddleware': 543, #} # Enable or disable downloader middlewares # See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html DOWNLOADER_MIDDLEWARES = { 'city_58.middlewares.ProxyMiddleware': 543, #代理中间件 } # Enable or disable extensions # See http://scrapy.readthedocs.org/en/latest/topics/extensions.html #EXTENSIONS = { # 'scrapy.extensions.telnet.TelnetConsole': None, #} # Configure item pipelines # See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html #先进行数据处理,再进行数据入库 ITEM_PIPELINES = { 'city_58.pipelines.HandleZuFangPipline': 300, # 租房平均每平米价格 'city_58.pipelines.HandleFangjiaPipline': 310, #小区平均价格 'city_58.pipelines.City58Pipeline': 320, #储存入库 } # Enable and configure the AutoThrottle extension (disabled by default) # See http://doc.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True # The initial download delay #AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies #AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: #AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default) # See http://scrapy.readthedocs.org/en/latest/topics/downlo,mhader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True #HTTPCACHE_EXPIRATION_SECS = 0 #HTTPCACHE_DIR = 'httpcache' #HTTPCACHE_IGNORE_HTTP_CODES = [] #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage' MONGODB_HOST = '127.0.0.1' #本地数据库 MONGODB_PORT = '27017' #数据库端口 MONGODB_URI = 'mongodb://{}:{}'.format(MONGODB_HOST, MONGODB_PORT) MONGODB_DATABASE = 'test' #数据库名字



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











