







 本文深入解析了LeNet-5、AlexNet、VGG、GoogleNet和ResNet等经典卷积神经网络(CNN)架构,从LeNet-5的数字识别到ResNet的残差单元,详述了CNN的发展历程与关键技术。
本文深入解析了LeNet-5、AlexNet、VGG、GoogleNet和ResNet等经典卷积神经网络(CNN)架构,从LeNet-5的数字识别到ResNet的残差单元,详述了CNN的发展历程与关键技术。
LeNet-5
-
LeNet-5是Yann LeCun在1998年提出的卷积神经网络算法,主要用于数字识别,他的卷积,池化,全连接层思想一直沿用到现在。
-
LeNet-5结构
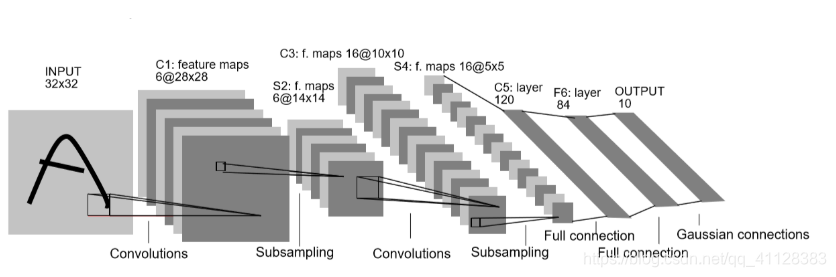
输入:32x32的特征图像
第一层:6个大小为5x5的卷积核,步长为1,输出为28x28x6第二层:2x2大小的池化层,使用的是average pooling,步长为2。 输出为14x14x6
第三层:16个大小为5x5的卷积核,步长为1。输出为10x10x16
第四层:,2x2大小的池化层,步长为2,使用的是average pooling,输出为5x5x16
第五层:全连接层,120个卷积核,大小为1x1。
第六层:全连接层,隐藏单元是84个。
输出分类类别
-
激活层默认不画网络图当中,这个网络结构当时使用的是sigmoid和Tanh函数
AlexNet
2012年Alex Krizhevsky、Ilya Sutskever在多伦多大学Geoff Hinton的实验室设计出了深层卷积神经网络,夺得了2012年ImageNet LSVRC的冠军,且准确率远超第二名,引起了很大的轰动
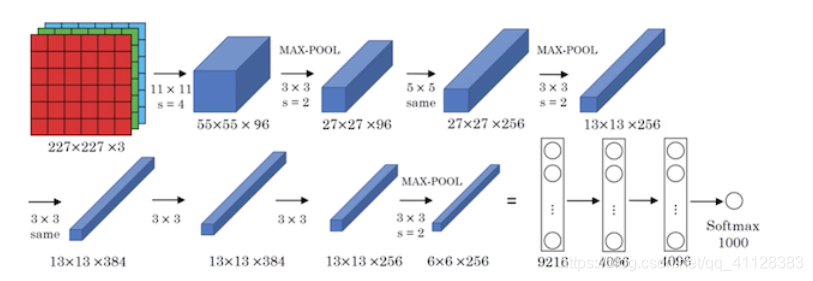
AlexNet结构与LeNet-5类似,但是AlexNet更深更多的参数,其网络中有5个卷积层,3个全连接层,参数达到6000千万个,AlexNet的闪光点是使用了非线性函数ReLu,为了防止过拟合也使用了dropout正则化,批标准化技术点
VGG
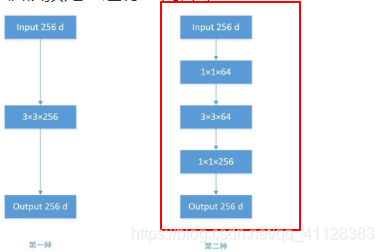
获得ImageNet LSVRC 2014的亚军,与AlexNet的不同是,比AlexNet网络结构更深,达到了16,19层,参数更是达到了1.4亿个,VGG的闪光点是使用了1乘1,3乘3的更小的卷积核,使得卷积,池化层的参数更少,也让我们知道了更深的网络结构可以提升CNN图像识别的能力
Keras实现
def VGG_16():
model = Sequential()
model.add(Conv2D(64,(3,3),strides=(1,1),input_shape=(224,224,3),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(64,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(128,(3,2),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(128,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(4096,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1000,activation='softmax'))
return model
GoogleNet
获得ImageNet LSVRC 2014的冠军, GoogleNet结构也称使用22层更深的网络结构,但是参数量只有500百万,引入了引入了Inception模块,总共由9个线性的Inception模块组成,所以也称Inception v1,它是改变了之前VGG的思想通过加深网络网络结构提升分类性能,而是采用网络设计的思想去解决图片中张图中的主体大小不一的问题从而提升分类性能。
-
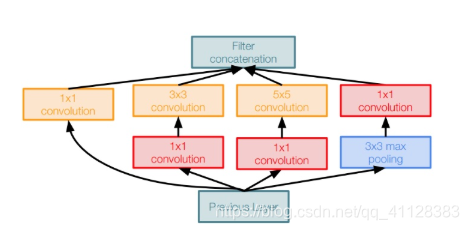
Inception模块介绍
每个Inception模块有多个卷积核,分别是1×1, 3×3和5×5,对输入图像进行卷积操作。并且还会进行一次最大池化操作。最后将这四个操作的输出结合在一起传送给下一个Inception模块
-
从VGGNet以及NIN的论文中可知,fc层具有大量参数,因此GoogleNet用average pooling替代fc,减少参数数量防止过拟合。在softmax前的fc之间加入dropout,p=0.7,进一步防止过拟合
-
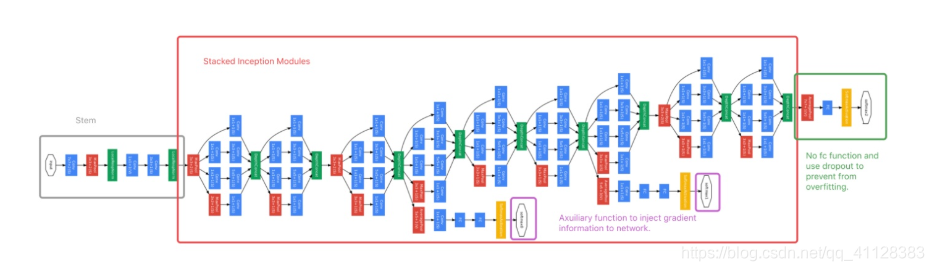
辅助函数(Axuiliary Function)
因为是梯度信息在BP过程中能量衰减,无法到达浅层区域,因此在GoogleNet结构中增加了辅助损失函数,目的是计算损失时让低层的特征也有很好的区分能力,从而让网络更好地被训练,同时达到了网络的收敛的效果,GoogLeNet网络结构中有3个LOSS单元,前两个辅助LOSS单元的计算和最后的LOSS相加作为最终的损失函数来训练网络
完整的GoogleNet结构
-
Inception v2
Inception v2的论文,提出”Batch Normalization”思想:消除因conv而产生internal covariant shift, 保持数据在训练过程中的统计特性的一致性。Inception v2的结构是在卷积层与激活函数之间插入BN层:conv-bn-relu -
Inception v3
Inception v3使用factorization的方法进一步对inception v2的参数数量进行优化和降低
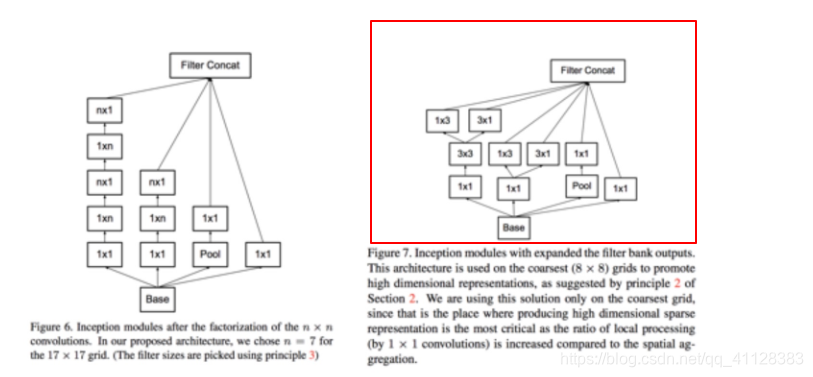
Factorization:
用小的卷积核替代大的卷积核,并使用1x1卷积核预处理进行空间降维
使用receptive field等效的原理,进一步将nxn的卷积核裂化成1xn和nx1的卷积核串联形式或者并联形式,进一步减少计算量。
- ResNet
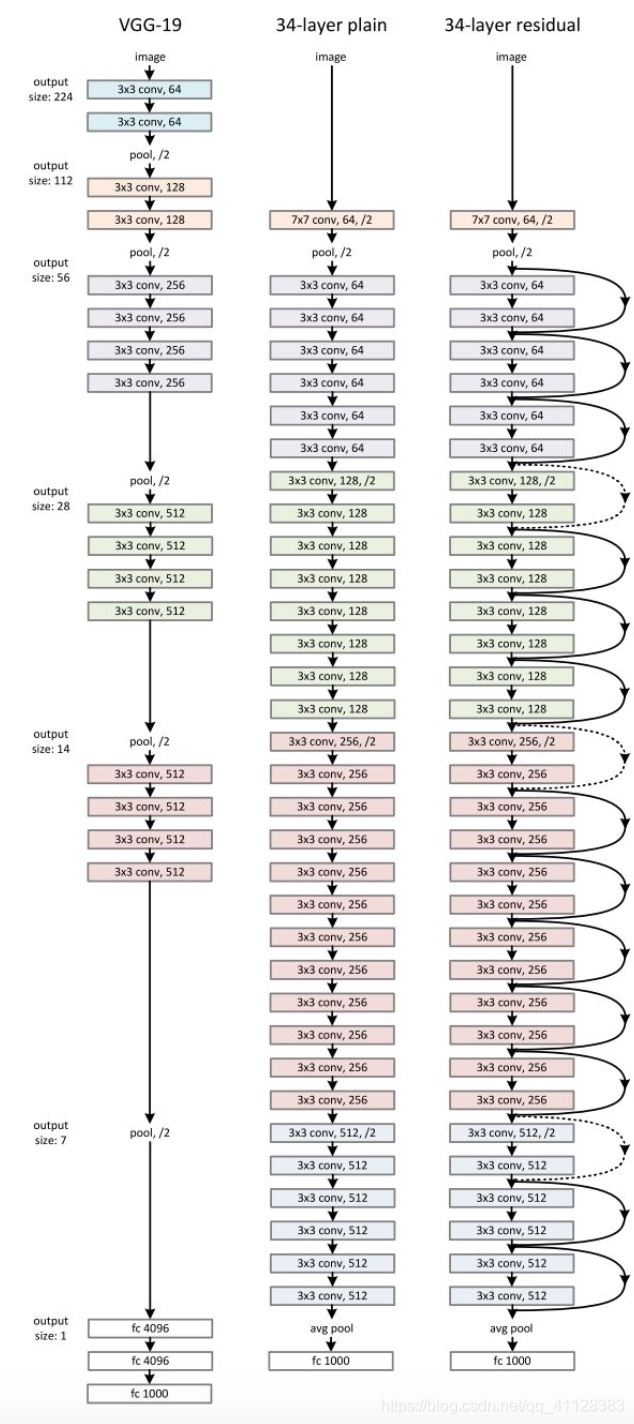
2015年何恺明推出的ResNet在ISLVRC和COCO上横扫所有选手,获得冠军。ResNet在网络结构上做了大创新,而不再是简单的在网络架构中堆积层数
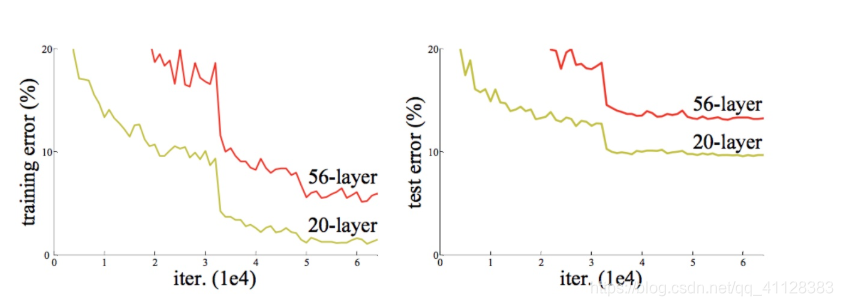
提升网络深度显著对性能提升提到了很大的作用,但是更深层的结构,由于梯度消失问题,很难训练。因为梯度反向传播到前面的层,重复相乘可能使梯度无穷小。结果就是,随着网络的层数更深,其性能趋于饱和,甚至开始迅速下降,直观的反映如下图示
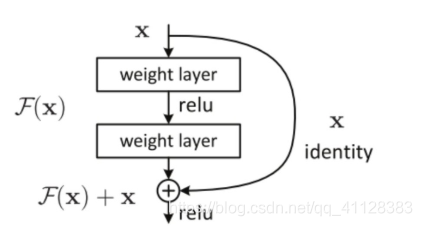
为了解决由于网络深度带来梯度消失的问题,所以ResNet的设计引入残差单元解决网络退化的问题,并且ResNe网络深很多,但是运算量是少于VGG19及其他结构的,ResNet通过增加 恒等快捷连接(identity shortcut connection)实现,直接跳过一个或多个层,ResNet有很多个残差模块(如下图)组成,每个模块卷积层和快捷组成,这个捷径将输入直接和输出连接,在进行Relu激活前,将图中的F(x)和x相加,然后将相加结果输入到激活函数Relu产生该模块的输出
完整结构


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









