




这是CVPR2020 oral的一阶段实例分割的文章。
基于点来出框还是基于特征区域来出框是划分一阶段和二阶段最重要的依据。
论文PDF:https://arxiv.org/pdf/1909.13226.pdf
代码:github.com/xieenze/PolarMask.
摘要
本文通过实例中心分类和极坐标中的密集距离回归,将实例分割问题表述为实例轮廓的预测。 另外,本文采用有效的方法来处理采样高质量中心实例和优化密集距离回归,显著提高性能,简化训练过程。
必要知识
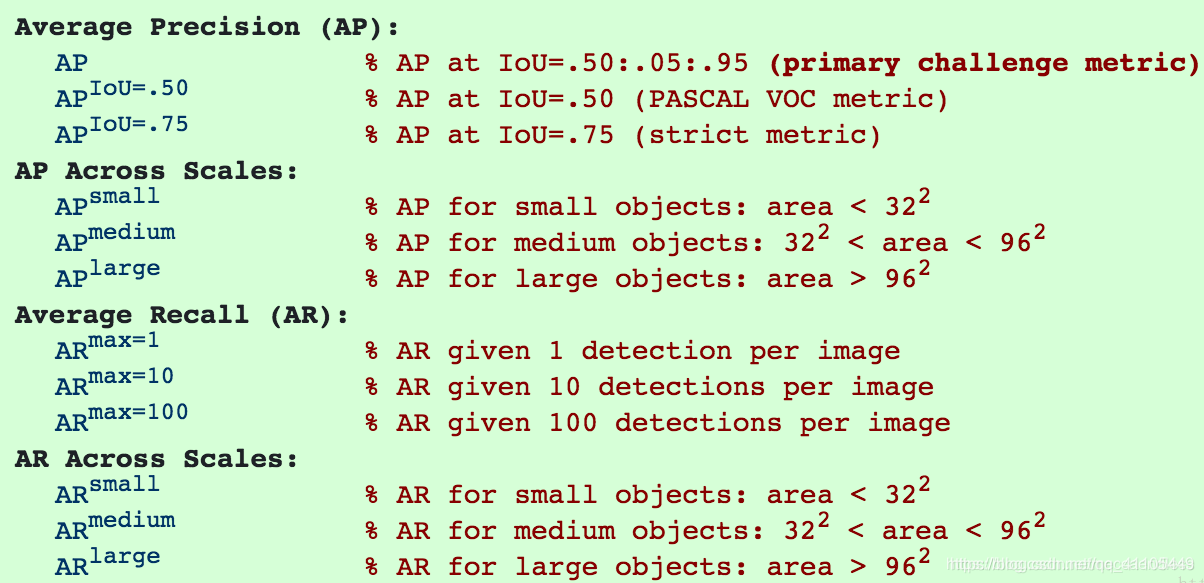
1.mAP值的计算
P:precision,即准确率;也就是所有被识别出来的本类物体中,真正的这类物体所占的比例。
R:recall,即召回率。也就是被正确识别出来的本类物体个数与测试集中所有真实本类物体的个数的比值。
Precision-recall 曲线:即以precision和recall作为纵、横轴坐标的二维曲线。改变识别阈值,使得系统依次能够识别前K张图片,阈值的变化同时会导致Precision与Recall值发生变化,从而得到曲线。
AP: Average Precision,就是Precision-recall 曲线下面的面积,通常来说一个越好的分类器,AP值越高。
mAP:Mean Average Precision,是多个类别AP的平均值。这个mean的意思是对每个类的AP再求平均,得到的就是mAP的值,mAP的大小一定在[0,1]区间,越大越好。该指标是目标检测算法中最重要的一个。
COCO中说的AP是AP[.50:.05:.95],也就是IOU_T设置为0.5,0.55,0.60,0.65……0.95,算十个APx,然后再求平均,得到的就是AP(COCO里的AP就是mAP)。官方解释如下:
2.mask掩码
 第一步建立与原图一样大小的mask图像,并将所有像素初始化为0,因此全图成了一张全黑色图。
第一步建立与原图一样大小的mask图像,并将所有像素初始化为0,因此全图成了一张全黑色图。
第二步将mask图中的r1区域的所有像素值设置为255,也就是整个ROI区域变成了白色。
mask其实就是位图啊,来选择哪个像素允许拷贝,哪个像素不允许拷贝。如果mask像素的值是非0的,我就拷贝它,否则不拷贝。得到的感兴趣的区域是白色的,表明感兴趣区域的像素都是非0,而非感兴趣区域都是黑色。一旦原图与mask图进行与运算后,得到的结果图只留下原始图感兴趣区域的图像了。
3.Smooth L1 Loss
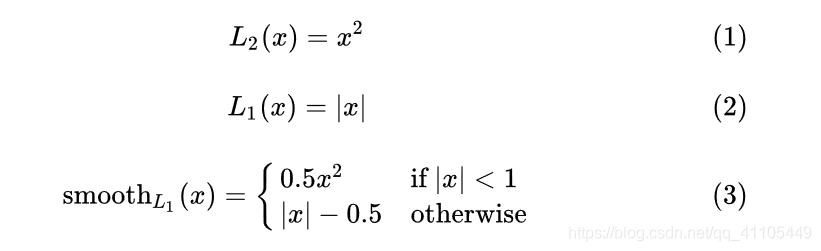

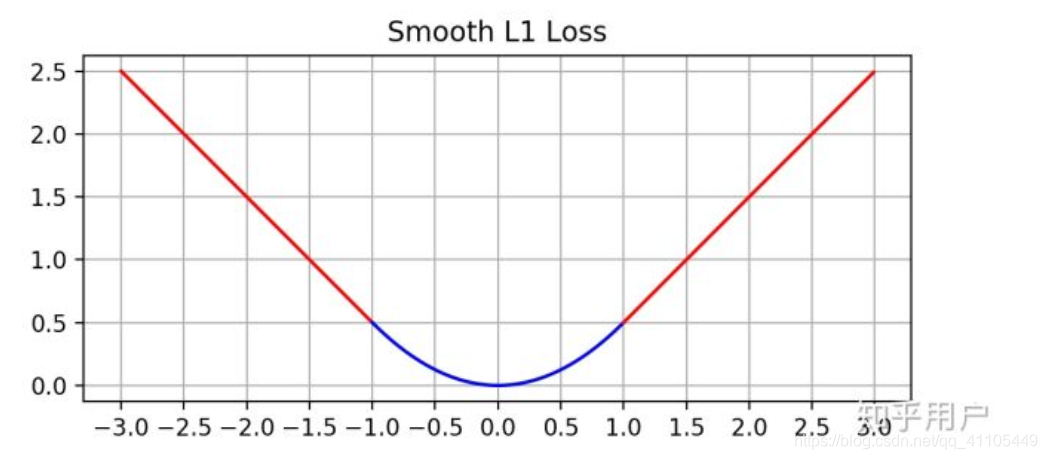 在 x 较小时,对 x 的梯度也会变小,而在 x 很大时,对 x 的梯度的绝对值达到上限 1,也不会太大以至于破坏网络参数。 smooth L1 完美地避开了 L1 和 L2 损失的缺陷。(当 x 增大时 L2 损失对 x 的导数也增大。这就导致训练初期,预测值与 groud truth 差异过于大时,损失函数对预测值的梯度十分大,训练不稳定。L1 对 x 的导数为常数。这就导致训练后期,预测值与 ground truth 差异很小时, L1 损失对预测值的导数的绝对值仍然为 1,而 learning rate 如果不变,损失函数将在稳定值附近波动,难以继续收敛以达到更高度。)
在 x 较小时,对 x 的梯度也会变小,而在 x 很大时,对 x 的梯度的绝对值达到上限 1,也不会太大以至于破坏网络参数。 smooth L1 完美地避开了 L1 和 L2 损失的缺陷。(当 x 增大时 L2 损失对 x 的导数也增大。这就导致训练初期,预测值与 groud truth 差异过于大时,损失函数对预测值的梯度十分大,训练不稳定。L1 对 x 的导数为常数。这就导致训练后期,预测值与 ground truth 差异很小时, L1 损失对预测值的导数的绝对值仍然为 1,而 learning rate 如果不变,损失函数将在稳定值附近波动,难以继续收敛以达到更高度。)
4.全卷积网络
简单来说就是把CNN最后的全连接层换成卷积层,输出的是一张已经Label好的图片,主要好处是支持不同大小的输入。采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类。
5.COCO数据集
起源于微软于2014年出资标注的Microsoft COCO数据集,COCO数据集是一个大型的、丰富的物体检测,分割和字幕数据集。这个数据集以scene understanding为目标,主要从复杂的日常场景中截取,图像中的目标通过精确的分割进行位置的标定。图像包括91类目标,328,000个影像和2,500,000个label。虽然比ImageNet和SUN类别少,但是每一类的图像多,这有利于获得更多的每类中位于某种特定场景的能力,对比PASCAL VOC,其有更多类和图像。
6.随机剪裁(random crop)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4868
4868




 到【灌水乐园】发言
到【灌水乐园】发言







